5.5 Cómputo en paralelo usando GPUs en un sistema de memoria compartida (SMC)
Contents
5.5 Cómputo en paralelo usando GPUs en un sistema de memoria compartida (SMC)#
Notas para contenedor de docker:
Comando de docker para ejecución de la nota de forma local:
nota: cambiar <ruta a mi directorio> por la ruta de directorio que se desea mapear a /datos dentro del contenedor de docker y <versión imagen de docker> por la versión más actualizada que se presenta en la documentación.
docker run --rm -v <ruta a mi directorio>:/datos --name jupyterlab_optimizacion_2 -p 8888:8888 -d palmoreck/jupyterlab_optimizacion_2:<versión imagen de docker>
password para jupyterlab: qwerty
Detener el contenedor de docker:
docker stop jupyterlab_optimizacion_2
Documentación de la imagen de docker palmoreck/jupyterlab_optimizacion_2:<versión imagen de docker> en liga.
Nota generada a partir de liga.
Al final de esta nota la comunidad lectora:
Aprenderá un poco de historia y arquitectura de la GPU.
Se familiarizará con la sintaxis de CUDA-C para cómputo en la GPU con ejemplos sencillos y los relacionará con el modelo de programación CUDA.
Utilizará el paquete CuPy de Python para cómputo en la GPU.
Se presentan códigos y sus ejecuciones en una máquina p2.xlarge con una AMI ubuntu 20.04 - ami-042e8287309f5df03 de la nube de AWS. Se utilizó en la sección de User data el script_cuda_and_tools.sh
La máquina p2.xlarge tiene las siguientes características:
%%bash
lscpu
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
Address sizes: 46 bits physical, 48 bits virtual
CPU(s): 4
On-line CPU(s) list: 0-3
Thread(s) per core: 2
Core(s) per socket: 2
Socket(s): 1
NUMA node(s): 1
Vendor ID: GenuineIntel
CPU family: 6
Model: 79
Model name: Intel(R) Xeon(R) CPU E5-2686 v4 @ 2.30GHz
Stepping: 1
CPU MHz: 2701.377
CPU max MHz: 3000.0000
CPU min MHz: 1200.0000
BogoMIPS: 4600.15
Hypervisor vendor: Xen
Virtualization type: full
L1d cache: 64 KiB
L1i cache: 64 KiB
L2 cache: 512 KiB
L3 cache: 45 MiB
NUMA node0 CPU(s): 0-3
Vulnerability Itlb multihit: KVM: Vulnerable
Vulnerability L1tf: Mitigation; PTE Inversion
Vulnerability Mds: Vulnerable: Clear CPU buffers attempted, no microcode; SMT Host state unknown
Vulnerability Meltdown: Mitigation; PTI
Vulnerability Spec store bypass: Vulnerable
Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Vulnerability Spectre v2: Mitigation; Full generic retpoline, STIBP disabled, RSB filling
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Vulnerable: Clear CPU buffers attempted, no microcode; SMT Host state unknown
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ht syscall nx pdpe1gb rdtscp lm constant_tsc rep_good nopl xtopology nonstop_tsc cpuid aperfmperf pni pclmulqdq ssse3 fma cx16 pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand hypervisor lahf_lm abm 3dnowprefetch cpuid_fault invpcid_single pti fsgsbase bmi1 hle avx2 smep bmi2 erms invpcid rtm rdseed adx xsaveopt
%%bash
sudo lshw -C memory
*-firmware
description: BIOS
vendor: Xen
physical id: 0
version: 4.2.amazon
date: 08/24/2006
size: 96KiB
capabilities: pci edd
*-memory
description: System Memory
physical id: 1000
size: 61GiB
capabilities: ecc
configuration: errordetection=multi-bit-ecc
*-bank:0
description: DIMM RAM
physical id: 0
slot: DIMM 0
size: 16GiB
width: 64 bits
*-bank:1
description: DIMM RAM
physical id: 1
slot: DIMM 1
size: 16GiB
width: 64 bits
*-bank:2
description: DIMM RAM
physical id: 2
slot: DIMM 2
size: 16GiB
width: 64 bits
*-bank:3
description: DIMM RAM
physical id: 3
slot: DIMM 3
size: 13GiB
width: 64 bits
%%bash
#execute next line to have in the book output of cell
sudo lshw -C display
*-display:0 UNCLAIMED
description: VGA compatible controller
product: GD 5446
vendor: Cirrus Logic
physical id: 2
bus info: pci@0000:00:02.0
version: 00
width: 32 bits
clock: 33MHz
capabilities: vga_controller
configuration: latency=0
resources: memory:80000000-81ffffff memory:86004000-86004fff memory:c0000-dffff
*-display:1 UNCLAIMED
description: 3D controller
product: GK210GL [Tesla K80]
vendor: NVIDIA Corporation
physical id: 1e
bus info: pci@0000:00:1e.0
version: a1
width: 64 bits
clock: 33MHz
capabilities: pm msi pciexpress cap_list
configuration: latency=0
resources: iomemory:100-ff memory:84000000-84ffffff memory:1000000000-13ffffffff memory:82000000-83ffffff
%%bash
uname -ar #r for kernel, a for all
Linux ip-10-0-0-128 5.4.0-1045-aws #47-Ubuntu SMP Tue Apr 13 07:02:25 UTC 2021 x86_64 x86_64 x86_64 GNU/Linux
Observación
En la celda anterior se utilizó el comando de magic %%bash. Algunos comandos de magic los podemos utilizar también con import. Ver ipython-magics
Compute Unified Device Architecture (CUDA)#
Un poco de historia…#
La industria de videojuegos impulsó el desarrollo de las tarjetas gráficas a una velocidad sin precedente a partir del año 1999 para incrementar el nivel de detalle visual en los juegos de video. Alrededor del 2003 se planteó la posibilidad de utilizar las unidades de procesamiento gráfico para procesamiento en paralelo relacionado con aplicaciones distintas al ambiente de gráficas. A partir del 2006 la empresa NVIDIA introdujo CUDA, una plataforma GPGPU y un modelo de programación que facilita el procesamiento en paralelo en las GPU’s.
Desde el 2006, las tarjetas gráficas muestran una brecha significativa con las unidades de procesamiento CPU’s. Ver por ejemplo las gráficas que NVIDIA publica año tras año y que están relacionadas con el número de operaciones en punto flotante por segundo (FLOPS) y la transferencia de datos en la memoria RAM de la GPU: gráficas cpu vs gpu en imágenes de google.
Hoy en día se continúa el desarrollo de GPU’s con mayor RAM, con mayor capacidad de cómputo y mejor conectividad con la CPU. Estos avances han permitido resolver problemas con mayor exactitud que los resueltos con las CPU’s, por ejemplo en el terreno de deep learning en reconocimiento de imágenes. Ver ImageNet Classification with Deep Convolutional Neural Networks, 2012: A Breakthrough Year for Deep Learning.
Observación
Para más avances ver NVIDIA Turing Architecture In-Depth, samsung-amd-rdna-gpu-2021, playstation-5-specifications-revealed-but-design-is-still-a-mystery, xbox-series-x-tech y recientemente IBM Supercomputer Summit Attacks Coronavirus….
La arquitectura en la que podemos ubicar a las GPU’s es en la de un sistema MIMD y SIMD. De hecho es SIMT: Simple Instruction Multiple Thread en un modelo de sistema de memoria compartida pues “los threads en un warp leen la misma instrucción para ser ejecutada”.
Definición
Un warp en el contexto de GPU programming es un conjunto de threads. Equivale a \(32\) threads.
¿Diferencia con la CPU multicore?#
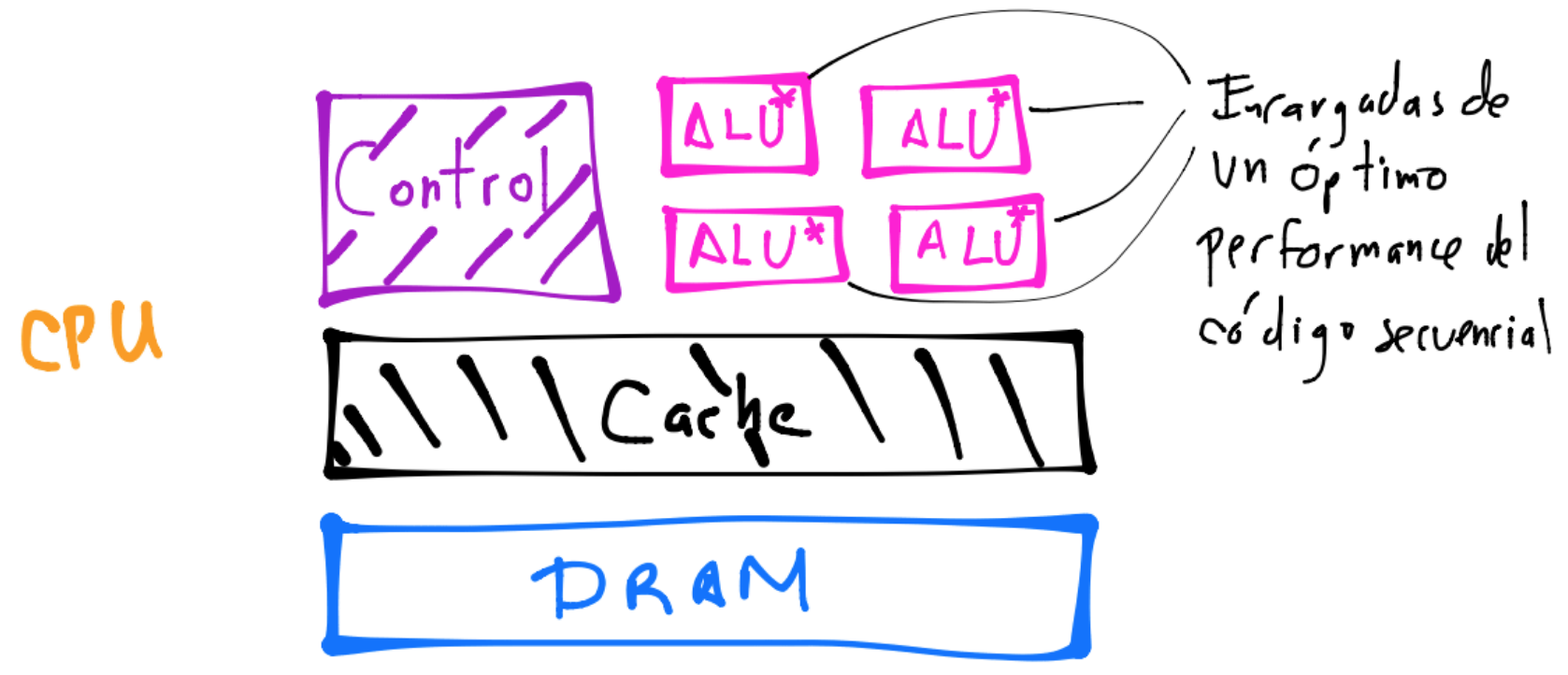
GPU
Observación
Obsérvese en el dibujo anterior la diferencia en tamaño del caché en la CPU y GPU. También la unidad de control es más pequeña en la GPU.
A diferencia de una máquina multicore o multi CPU’s con la habilidad de lanzar en un instante de tiempo unos cuantos threads, la GPU puede lanzar cientos o miles de threads en un instante siendo cada core heavily multithreaded. Sí hay restricciones en el número de threads que se pueden lanzar en un instante pues las tarjetas gráficas tienen diferentes características (modelo) y arquitecturas, pero la diferencia con la CPU es grande. Por ejemplo, la serie GT 200 (2009) en un instante puede lanzar 30,720 threads con sus 240 cores. Ver GeForce_200_series, List of NVIDIA GPU’s.
Ver How Graphics Cards Work y How Microprocessors Work para más información.
¿Otras compañías producen tarjetas gráficas?#
Sí, ver por ejemplo la lista de GPU’s de Advanced Micro Devices.
¿Si tengo una tarjeta gráfica de AMD puedo correr un programa de CUDA?#
No es posible pero algunas alternativas son:
¿Si tengo una tarjeta gráfica de NVIDIA un poco antigua puedo correr un programa de CUDA?#
Las GPU’s producidas por NVIDIA desde 2006 son capaces de correr programas basados en CUDA C. La cuestión sería revisar qué compute capability tiene tu tarjeta. Ver Compute Capabilities para las características que tienen las tarjetas más actuales.
¿Qué es CUDA C?#
Es una extensión al lenguaje C de programación en el que se utiliza una nueva sintaxis para procesamiento en la GPU. Contiene también una librería runtime que define funciones que se ejecutan desde el host por ejemplo para alojar y desalojar memoria en el device, transferir datos entre la memoria host y la memoria device o manejar múltiples devices. La librería runtime está hecha encima de una API de C de bajo nivel llamada NVIDIA CUDA Driver API la cual es accesible desde el código. Para información de la API de la librería runtime ver NVIDIA CUDA Runtime API.
Comentario
La transferencia de datos entre la memoria del host a device o viceversa constituye un bottleneck fuerte.
¿A qué se refiere la terminología de host y device?#
Host es la máquina multicore CPU y device es la GPU. Una máquina puede tener múltiples GPU’s por lo que tendrá múltiples devices.
Tengo una tarjeta NVIDIA CUDA capable ¿qué debo realizar primero?#
Realizar instalaciones dependiendo de tu sistema operativo. Ver instalación donde además se encontrará información para instalación de nvidia-docker.
Instalé lo necesario y al ejecutar en la terminal nvcc -V obtengo la versión… ¿cómo puedo probar mi instalación?#
1)Obteniendo información del NVIDIA driver ejecutando en la terminal el comando nvidia-smi.
%%bash
nvidia-smi
Mon May 10 23:31:35 2021
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 465.19.01 Driver Version: 465.19.01 CUDA Version: 11.3 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 NVIDIA Tesla K80 On | 00000000:00:1E.0 Off | 0 |
| N/A 34C P8 30W / 149W | 0MiB / 11441MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
%%bash
nvidia-smi -a #a for all
==============NVSMI LOG==============
Timestamp : Mon May 10 23:31:35 2021
Driver Version : 465.19.01
CUDA Version : 11.3
Attached GPUs : 1
GPU 00000000:00:1E.0
Product Name : NVIDIA Tesla K80
Product Brand : Tesla
Display Mode : Disabled
Display Active : Disabled
Persistence Mode : Enabled
MIG Mode
Current : N/A
Pending : N/A
Accounting Mode : Disabled
Accounting Mode Buffer Size : 4000
Driver Model
Current : N/A
Pending : N/A
Serial Number : 0325116067357
GPU UUID : GPU-30cfb81b-c816-3139-4205-7e6a686b4699
Minor Number : 0
VBIOS Version : 80.21.1F.00.02
MultiGPU Board : No
Board ID : 0x1e
GPU Part Number : 900-22080-0000-000
Inforom Version
Image Version : 2080.0200.00.04
OEM Object : 1.1
ECC Object : 3.0
Power Management Object : N/A
GPU Operation Mode
Current : N/A
Pending : N/A
GPU Virtualization Mode
Virtualization Mode : Pass-Through
Host VGPU Mode : N/A
IBMNPU
Relaxed Ordering Mode : N/A
PCI
Bus : 0x00
Device : 0x1E
Domain : 0x0000
Device Id : 0x102D10DE
Bus Id : 00000000:00:1E.0
Sub System Id : 0x106C10DE
GPU Link Info
PCIe Generation
Max : 3
Current : 1
Link Width
Max : 16x
Current : 16x
Bridge Chip
Type : N/A
Firmware : N/A
Replays Since Reset : 0
Replay Number Rollovers : 0
Tx Throughput : N/A
Rx Throughput : N/A
Fan Speed : N/A
Performance State : P8
Clocks Throttle Reasons
Idle : Active
Applications Clocks Setting : Not Active
SW Power Cap : Not Active
HW Slowdown : Not Active
HW Thermal Slowdown : N/A
HW Power Brake Slowdown : N/A
Sync Boost : Not Active
SW Thermal Slowdown : Not Active
Display Clock Setting : Not Active
FB Memory Usage
Total : 11441 MiB
Used : 0 MiB
Free : 11441 MiB
BAR1 Memory Usage
Total : 16384 MiB
Used : 2 MiB
Free : 16382 MiB
Compute Mode : Default
Utilization
Gpu : 0 %
Memory : 0 %
Encoder : 0 %
Decoder : 0 %
Encoder Stats
Active Sessions : 0
Average FPS : 0
Average Latency : 0
FBC Stats
Active Sessions : 0
Average FPS : 0
Average Latency : 0
Ecc Mode
Current : Enabled
Pending : Enabled
ECC Errors
Volatile
Single Bit
Device Memory : 0
Register File : 0
L1 Cache : 0
L2 Cache : 0
Texture Memory : 0
Texture Shared : N/A
CBU : N/A
Total : 0
Double Bit
Device Memory : 0
Register File : 0
L1 Cache : 0
L2 Cache : 0
Texture Memory : 0
Texture Shared : N/A
CBU : N/A
Total : 0
Aggregate
Single Bit
Device Memory : 0
Register File : 0
L1 Cache : 0
L2 Cache : 0
Texture Memory : 0
Texture Shared : N/A
CBU : N/A
Total : 0
Double Bit
Device Memory : 0
Register File : 0
L1 Cache : 0
L2 Cache : 0
Texture Memory : 0
Texture Shared : N/A
CBU : N/A
Total : 0
Retired Pages
Single Bit ECC : 0
Double Bit ECC : 0
Pending Page Blacklist : No
Remapped Rows : N/A
Temperature
GPU Current Temp : 34 C
GPU Shutdown Temp : 110 C
GPU Slowdown Temp : 88 C
GPU Max Operating Temp : N/A
GPU Target Temperature : N/A
Memory Current Temp : N/A
Memory Max Operating Temp : N/A
Power Readings
Power Management : Supported
Power Draw : 30.91 W
Power Limit : 149.00 W
Default Power Limit : 149.00 W
Enforced Power Limit : 149.00 W
Min Power Limit : 100.00 W
Max Power Limit : 175.00 W
Clocks
Graphics : 324 MHz
SM : 324 MHz
Memory : 324 MHz
Video : 405 MHz
Applications Clocks
Graphics : 562 MHz
Memory : 2505 MHz
Default Applications Clocks
Graphics : 562 MHz
Memory : 2505 MHz
Max Clocks
Graphics : 875 MHz
SM : 875 MHz
Memory : 2505 MHz
Video : 540 MHz
Max Customer Boost Clocks
Graphics : N/A
Clock Policy
Auto Boost : On
Auto Boost Default : On
Processes : None
Para más información del comando nvidia-smi ver results-for-the-nvidia-smi-command-in-a-terminal y nvidia-smi-367.38.
Comentarios
Ejecutando
nvidia-smi -l 1nos da información cada segundo. Otra opción eswatch -n 3 nvidia-smi --query-gpu=<queries> --format=csv. Por ejemplo:
watch -n 3 nvidia-smi --query-gpu=index,gpu_name,memory.total,memory.used,memory.free,temperature.gpu,pstate,utilization.gpu,utilization.memory --format=csv
Una herramienta que nos ayuda al monitoreo de uso de la(s) GPU(s) es nvtop.
2)Compilando y ejecutando el siguiente programa de CUDA C:
%%file hello_world.cu
#include<stdio.h>
__global__ void func(void){
printf("Hello world! del bloque %d del thread %d\n", blockIdx.x, threadIdx.x);
}
int main(void){
func<<<2,3>>>();
cudaDeviceSynchronize();
printf("Hello world! del cpu thread\n");
return 0;
}
Writing hello_world.cu
Comentario
La sintaxis <<<2,3>>> refiere que serán lanzados 2 bloques de 3 threads cada uno.
Compilamos con nvcc.
%%bash
source ~/.profile
nvcc -gencode arch=compute_37,code=sm_37 hello_world.cu -o hello_world.out
nvcc warning : The 'compute_35', 'compute_37', 'compute_50', 'sm_35', 'sm_37' and 'sm_50' architectures are deprecated, and may be removed in a future release (Use -Wno-deprecated-gpu-targets to suppress warning).
Comentarios
nvcces un wrapper para el compilador de programas escritos en C.En ocasiones para tener funcionalidad de un determinado compute capability se especifica la flag de
-arch=sm_11en la línea denvcc. En este caso se le indica al compilador que compile el programa para un compute capability de \(1.1\). Ver run a kernel using the larger grid size support offered.Para la versión 11 de CUDA se requiere explícitamente indicar la arquitectura y código para la compilación. Ver cuda-11-kernel-doesnt-run, cuda-how-to-use-arch-and-code-and-sm-vs-compute, cuda-compute-capability-requirements, what-is-the-canonical-way-to-check-for-errors-using-the-cuda-runtime-api.
Ejecutamos.
%%bash
./hello_world.out
Hello world! del bloque 0 del thread 0
Hello world! del bloque 0 del thread 1
Hello world! del bloque 0 del thread 2
Hello world! del bloque 1 del thread 0
Hello world! del bloque 1 del thread 1
Hello world! del bloque 1 del thread 2
Hello world! del cpu thread
3)Haciendo un query a la GPU para ver qué características tiene (lo siguiente es posible ejecutar sólo si se instaló el CUDA toolkit):
%%bash
cd /usr/local/cuda/samples/1_Utilities/deviceQuery/ && sudo make
/usr/local/cuda/samples/1_Utilities/deviceQuery/deviceQuery
make: Nothing to be done for 'all'.
/usr/local/cuda/samples/1_Utilities/deviceQuery/deviceQuery Starting...
CUDA Device Query (Runtime API) version (CUDART static linking)
Detected 1 CUDA Capable device(s)
Device 0: "NVIDIA Tesla K80"
CUDA Driver Version / Runtime Version 11.3 / 11.3
CUDA Capability Major/Minor version number: 3.7
Total amount of global memory: 11441 MBytes (11996954624 bytes)
(013) Multiprocessors, (192) CUDA Cores/MP: 2496 CUDA Cores
GPU Max Clock rate: 824 MHz (0.82 GHz)
Memory Clock rate: 2505 Mhz
Memory Bus Width: 384-bit
L2 Cache Size: 1572864 bytes
Maximum Texture Dimension Size (x,y,z) 1D=(65536), 2D=(65536, 65536), 3D=(4096, 4096, 4096)
Maximum Layered 1D Texture Size, (num) layers 1D=(16384), 2048 layers
Maximum Layered 2D Texture Size, (num) layers 2D=(16384, 16384), 2048 layers
Total amount of constant memory: 65536 bytes
Total amount of shared memory per block: 49152 bytes
Total shared memory per multiprocessor: 114688 bytes
Total number of registers available per block: 65536
Warp size: 32
Maximum number of threads per multiprocessor: 2048
Maximum number of threads per block: 1024
Max dimension size of a thread block (x,y,z): (1024, 1024, 64)
Max dimension size of a grid size (x,y,z): (2147483647, 65535, 65535)
Maximum memory pitch: 2147483647 bytes
Texture alignment: 512 bytes
Concurrent copy and kernel execution: Yes with 2 copy engine(s)
Run time limit on kernels: No
Integrated GPU sharing Host Memory: No
Support host page-locked memory mapping: Yes
Alignment requirement for Surfaces: Yes
Device has ECC support: Enabled
Device supports Unified Addressing (UVA): Yes
Device supports Managed Memory: Yes
Device supports Compute Preemption: No
Supports Cooperative Kernel Launch: No
Supports MultiDevice Co-op Kernel Launch: No
Device PCI Domain ID / Bus ID / location ID: 0 / 0 / 30
Compute Mode:
< Default (multiple host threads can use ::cudaSetDevice() with device simultaneously) >
deviceQuery, CUDA Driver = CUDART, CUDA Driver Version = 11.3, CUDA Runtime Version = 11.3, NumDevs = 1
Result = PASS
¿Por qué usar CUDA y CUDA-C o más general cómputo en la GPU?#
NVIDIA como se mencionó al inicio de la nota fue de las primeras compañías en utilizar la GPU para tareas no relacionadas con el área de gráficos, ha colaborado en el avance del conocimiento de las GPU’s y desarrollo de algoritmos y tarjetas gráficas. Otra compañía es Khronos_Group por ejemplo, quien actualmente desarrolla OpenCl.
El cómputo en la GPU constituye hoy en día una alternativa fuerte a la implementación de modelos de machine learning ampliamente utilizada por la comunidad científica, también para cómputo matricial y deep learning.
Sí hay publicaciones científicas para la implementación de deep learning en las CPU’s, ver por ejemplo el paper reciente de SLIDE cuyo repo de github es HashingDeepLearning. Tal paper plantea una discusión a realizar con la frase:
…change in the state-of-the-art algorithms can render specialized hardware less effective in the future.
Ver por ejemplo Tensor Cores, NVIDIA TENSOR CORES, The Next Generation of Deep Learning, The most powerful computers on the planet: SUMMIT como ejemplos de hardware especializado para aprendizaje con Tensorflow.
Observación
Summit powered by 9,126 IBM Power9 CPUs and over 27,000 NVIDIA V100 Tensor Core GPUS, is able to do 200 quadrillion calculations per second… IBM Supercomputer Summit Attacks Coronavirus….
Sin embargo, por falta de implementaciones algorítmicas en la CPU se han adoptado implementaciones de deep learning utilizando GPU’s:
…However, for the case of DL, this investment is justified due to the lack of significant progressin the algorithmic alternatives for years.
Comentario
Revisar también las entradas An algorithm could make CPUs a cheap way to train AI y Deep learning rethink overcomes major obstacle in AI industry.
CUDA-C#
Consiste en extensiones al lenguaje C y en una runtime library.
Kernel#
En CUDA C se define una función que se ejecuta en el device y que se le nombra kernel. El kernel inicia con la sintaxis:
__global__ void mifun(int param){
...
}
Siempre es tipo
void(no hayreturn).El llamado al kernel se realiza desde el host y con una sintaxis en la que se define el número de threads, nombrados CUDA threads (que son distintos a los CPU threads), y bloques, nombrados CUDA blocks, que serán utilizados para la ejecución del kernel. La sintaxis que se utiliza es
<<< >>>y en la primera entrada se coloca el número de CUDA blocks y en la segunda entrada el número de CUDA threads. Por ejemplo para lanzar N bloques de 5 threads.
__global__ void mifun(int param){
...
}
int main(){
int par=0;
mifun<<<N,5>>>(par);
}
Ejemplo#
%%file hello_world_simple.cu
#include<stdio.h>
__global__ void func(void){
}
int main(void){
func<<<1,1>>>();
printf("Hello world!\n");
return 0;
}
Writing hello_world_simple.cu
Compilación:
%%bash
source ~/.profile
nvcc -gencode arch=compute_37,code=sm_37 --compiler-options -Wall hello_world_simple.cu -o hello_world_simple.out
nvcc warning : The 'compute_35', 'compute_37', 'compute_50', 'sm_35', 'sm_37' and 'sm_50' architectures are deprecated, and may be removed in a future release (Use -Wno-deprecated-gpu-targets to suppress warning).
Ejecución:
%%bash
./hello_world_simple.out
Hello world!
Comentarios
La función
mainse ejecuta en la CPU.funces un kernel y es ejecutada por los CUDA threads en el device. Obsérvese que tal función inicia con la sintaxis__global__. En este caso el CUDA thread que fue lanzado no realiza ninguna acción pues el cuerpo del kernel está vacío.El kernel sólo puede tener un
returntipo void:__global__ void funcpor lo que el kernel debe regresar sus resultados a través de sus argumentos.La extensión del archivo debe ser
.cuaunque esto puede modificarse al compilar connvcc:
nvcc -x cu hello_world.c -o hello_world.out
¿Bloques de threads?#
Los CUDA threads son divididos en CUDA blocks y éstos se encuentran en un grid. En el lanzamiento del kernel se debe especificar al hardware cuántos CUDA blocks tendrá nuestro grid y cuántos CUDA threads estarán en cada bloque.
Ejemplo#
%%file hello_world_2.cu
#include<stdio.h>
__global__ void func(void){
printf("Hello world! del bloque %d del thread %d\n", blockIdx.x, threadIdx.x);
}
int main(void){
func<<<2,3>>>();
cudaDeviceSynchronize();
return 0;
}
Writing hello_world_2.cu
%%bash
source ~/.profile
nvcc -gencode arch=compute_37,code=sm_37 --compiler-options -Wall hello_world_2.cu -o hello_world_2.out
nvcc warning : The 'compute_35', 'compute_37', 'compute_50', 'sm_35', 'sm_37' and 'sm_50' architectures are deprecated, and may be removed in a future release (Use -Wno-deprecated-gpu-targets to suppress warning).
%%bash
./hello_world_2.out
Hello world! del bloque 0 del thread 0
Hello world! del bloque 0 del thread 1
Hello world! del bloque 0 del thread 2
Hello world! del bloque 1 del thread 0
Hello world! del bloque 1 del thread 1
Hello world! del bloque 1 del thread 2
En lo que continúa de la nota el nombre thread hará referencia a CUDA thread y el nombre bloque a CUDA block.
Comentarios
El llamado a la ejecución del kernel se realizó en el host y se lanzaron \(2\) bloques cada uno con \(3\) threads.
Se utiliza la función cudaDeviceSynchronize para que el cpu-thread espere la finalización de la ejecución del kernel.
En el ejemplo anterior, las variables
blockIdxythreadIdxhacen referencia a los id’s que tienen los bloques y los threads. El id del bloque dentro del grid y el id del thread dentro del bloque. La parte.xde las variables:blockIdx.xythreadIdx.xrefieren a la primera coordenada del bloque en el grid y a la primera coordenada del thread en en el bloque.La elección del número de bloques en un grid o el número de threads en un bloque no corresponde a alguna disposición del hardware. Esto es, si se lanza un kernel con
<<< 1, 3 >>>no implica que la GPU tenga en su hardware un bloque o 3 threads. Asimismo, las coordenadas que se obtienen víablockIdxothreadIdxson meras abstracciones, no corresponden a algún ordenamiento en el hardware de la GPU.Todos los threads de un bloque ejecutan el kernel por lo que se tienen tantas copias del kernel como número de bloques sean lanzados. Esto es una muestra la GPU sigue el modelo Single Instruction Multiple Threads (SIMT).
¿Grid’s y bloques 3-dimensionales?#
En el device podemos definir el grid de bloques y el bloque de threads utilizando el tipo de dato dim3 el cual también es parte de CUDA C.
Ejemplo#
%%file hello_world_3.cu
#include<stdio.h>
__global__ void func(void){
printf("Hello world! del bloque %d del thread %d\n", blockIdx.y, threadIdx.z);
}
int main(void){
dim3 dimGrid(1,2,1);
dim3 dimBlock(1,1,3);
func<<<dimGrid,dimBlock>>>();
cudaDeviceSynchronize();
printf("Hello world! del cpu thread\n");
return 0;
}
Writing hello_world_3.cu
%%bash
source ~/.profile
nvcc -gencode arch=compute_37,code=sm_37 --compiler-options -Wall hello_world_3.cu -o hello_world_3.out
nvcc warning : The 'compute_35', 'compute_37', 'compute_50', 'sm_35', 'sm_37' and 'sm_50' architectures are deprecated, and may be removed in a future release (Use -Wno-deprecated-gpu-targets to suppress warning).
%%bash
./hello_world_3.out
Hello world! del bloque 0 del thread 0
Hello world! del bloque 0 del thread 1
Hello world! del bloque 0 del thread 2
Hello world! del bloque 1 del thread 0
Hello world! del bloque 1 del thread 1
Hello world! del bloque 1 del thread 2
Hello world! del cpu thread
Ejemplo#
%%file thread_idxs.cu
#include<stdio.h>
__global__ void func(void){
if(threadIdx.x==0 && threadIdx.y==0 && threadIdx.z==0){
printf("blockIdx.x:%d\n",blockIdx.x);
}
printf("thread idx.x:%d\n",threadIdx.x);
printf("thread idx.y:%d\n",threadIdx.y);
printf("thread idx.z:%d\n",threadIdx.z);
}
int main(void){
dim3 dimGrid(1,1,1);
dim3 dimBlock(1,3,1);
func<<<dimGrid,dimBlock>>>();
cudaDeviceSynchronize();
return 0;
}
Writing thread_idxs.cu
%%bash
source ~/.profile
nvcc -gencode arch=compute_37,code=sm_37 thread_idxs.cu -o thread_idxs.out
nvcc warning : The 'compute_35', 'compute_37', 'compute_50', 'sm_35', 'sm_37' and 'sm_50' architectures are deprecated, and may be removed in a future release (Use -Wno-deprecated-gpu-targets to suppress warning).
%%bash
./thread_idxs.out
blockIdx.x:0
thread idx.x:0
thread idx.x:0
thread idx.x:0
thread idx.y:0
thread idx.y:1
thread idx.y:2
thread idx.z:0
thread idx.z:0
thread idx.z:0
Ejemplo#
%%file block_idxs.cu
#include<stdio.h>
__global__ void func(void){
printf("blockIdx.x:%d\n",blockIdx.x);
printf("blockIdx.y:%d\n",blockIdx.y);
printf("blockIdx.z:%d\n",blockIdx.z);
}
int main(void){
dim3 dimGrid(1,2,2);
dim3 dimBlock(1,1,1);
func<<<dimGrid,dimBlock>>>();
cudaDeviceSynchronize();
return 0;
}
Writing block_idxs.cu
%%bash
source ~/.profile
nvcc -gencode arch=compute_37,code=sm_37 --compiler-options -Wall block_idxs.cu -o block_idxs.out
nvcc warning : The 'compute_35', 'compute_37', 'compute_50', 'sm_35', 'sm_37' and 'sm_50' architectures are deprecated, and may be removed in a future release (Use -Wno-deprecated-gpu-targets to suppress warning).
%%bash
./block_idxs.out
blockIdx.x:0
blockIdx.x:0
blockIdx.x:0
blockIdx.x:0
blockIdx.y:1
blockIdx.y:0
blockIdx.y:1
blockIdx.y:0
blockIdx.z:1
blockIdx.z:0
blockIdx.z:0
blockIdx.z:1
Ejemplo#
Podemos usar la variable blockDim para cada coordenada x, y o z y obtener la dimensión de los bloques.
%%file block_dims.cu
#include<stdio.h>
__global__ void func(void){
if(threadIdx.x==0 && threadIdx.y==0 && threadIdx.z==0 && blockIdx.z==1){
printf("blockDim.x:%d\n",blockDim.x);
printf("blockDim.y:%d\n",blockDim.y);
printf("blockDim.z:%d\n",blockDim.z);
}
}
int main(void){
dim3 dimGrid(2,2,2);
dim3 dimBlock(3,1,2);
func<<<dimGrid,dimBlock>>>();
cudaDeviceSynchronize();
return 0;
}
Writing block_dims.cu
%%bash
source ~/.profile
nvcc -gencode arch=compute_37,code=sm_37 --compiler-options -Wall block_dims.cu -o block_dims.out
nvcc warning : The 'compute_35', 'compute_37', 'compute_50', 'sm_35', 'sm_37' and 'sm_50' architectures are deprecated, and may be removed in a future release (Use -Wno-deprecated-gpu-targets to suppress warning).
%%bash
./block_dims.out
blockDim.x:3
blockDim.x:3
blockDim.x:3
blockDim.x:3
blockDim.y:1
blockDim.y:1
blockDim.y:1
blockDim.y:1
blockDim.z:2
blockDim.z:2
blockDim.z:2
blockDim.z:2
Alojamiento de memoria en el device#
Para alojar memoria en el device se utiliza el llamado a cudaMalloc y para transferir datos del host al device o viceversa se llama a la función cudaMemcpy con respectivos parámetros como cudaMemcpyHostToDevice o cudaMemcpyDeviceToHost.
Para desalojar memoria del device se utiliza el llamado a cudaFree.
Ejemplo#
N bloques de 1 thread
%%file vector_sum.cu
#include<stdio.h>
#define N 10
__global__ void vect_sum(int *a, int *b, int *c){
int block_id_x = blockIdx.x;
if(block_id_x<N) //we assume N is less than maximum number of blocks
//that can be launched
c[block_id_x] = a[block_id_x]+b[block_id_x];
}
int main(void){
int a[N], b[N],c[N];
int *device_a, *device_b, *device_c;
int i;
dim3 dimGrid(N,1,1);
dim3 dimBlock(1,1,1);
//allocation in device
cudaMalloc((void **)&device_a, sizeof(int)*N);
cudaMalloc((void **)&device_b, sizeof(int)*N);
cudaMalloc((void **)&device_c, sizeof(int)*N);
//dummy data
for(i=0;i<N;i++){
a[i]=i;
b[i]=i*i;
}
//making copies of a, b arrays to GPU
cudaMemcpy(device_a,a,N*sizeof(int), cudaMemcpyHostToDevice);
cudaMemcpy(device_b,b,N*sizeof(int), cudaMemcpyHostToDevice);
vect_sum<<<dimGrid,dimBlock>>>(device_a,device_b,device_c);
cudaDeviceSynchronize();
//copy result to c array
cudaMemcpy(c,device_c,N*sizeof(int),cudaMemcpyDeviceToHost);
for(i=0;i<N;i++)
printf("%d+%d = %d\n",a[i],b[i],c[i]);
cudaFree(device_a);
cudaFree(device_b);
cudaFree(device_c);
return 0;
}
Writing vector_sum.cu
%%bash
source ~/.profile
nvcc -gencode arch=compute_37,code=sm_37 --compiler-options -Wall vector_sum.cu -o vector_sum.out
nvcc warning : The 'compute_35', 'compute_37', 'compute_50', 'sm_35', 'sm_37' and 'sm_50' architectures are deprecated, and may be removed in a future release (Use -Wno-deprecated-gpu-targets to suppress warning).
%%bash
./vector_sum.out
0+0 = 0
1+1 = 2
2+4 = 6
3+9 = 12
4+16 = 20
5+25 = 30
6+36 = 42
7+49 = 56
8+64 = 72
9+81 = 90
Comentarios
El statement:
int *device_a, *device_b, *device_c;
en sintaxis de C definen apuntadores que refieren a una dirección de memoria. En el contexto de la GPU programming estos apuntadores no apuntan a una dirección de memoria en el device. Aunque NVIDIA añadió el feature de Unified Memory (un espacio de memoria accesible para el host y el device) aquí no se está usando tal feature. Más bien se están utilizando los apuntadores anteriores para apuntar a un struct de C en el que uno de sus tipos de datos es una dirección de memoria en el device.
El uso de
(void **)en el statementcudaMalloc((void **)&device_a, sizeof(int)*N);es por la definición de la funcióncudaMalloc.En el programa anterior se coloca en comentario que se asume que \(N\) el número de datos en el arreglo es menor al número de bloques que es posible lanzar. Esto como veremos más adelante es importante considerar pues aunque en un device se pueden lanzar muchos bloques y muchos threads, se tienen límites en el número de éstos que es posible lanzar.
¿Perfilamiento en CUDA?#
Al instalar el CUDA toolkit en sus máquinas se instala la línea de comando nvprof para perfilamiento.
%%bash
source ~/.profile
nvprof --normalized-time-unit s ./vector_sum.out
0+0 = 0
1+1 = 2
2+4 = 6
3+9 = 12
4+16 = 20
5+25 = 30
6+36 = 42
7+49 = 56
8+64 = 72
9+81 = 90
==17783== NVPROF is profiling process 17783, command: ./vector_sum.out
==17783== Warning: Auto boost enabled on device 0. Profiling results may be inconsistent.
==17783== Profiling application: ./vector_sum.out
==17783== Profiling result:
Type Time(%) Time Calls Avg Min Max Name
% s s s s
GPU activities: 46.15 5.38e-06 1 5.38e-06 5.38e-06 5.38e-06 vect_sum(int*, int*, int*)
31.59 3.68e-06 2 1.84e-06 1.57e-06 2.11e-06 [CUDA memcpy HtoD]
22.25 2.59e-06 1 2.59e-06 2.59e-06 2.59e-06 [CUDA memcpy DtoH]
API calls: 99.59 0.264985 3 0.088328 4.07e-06 0.264975 cudaMalloc
0.19 5.17e-04 1 5.17e-04 5.17e-04 5.17e-04 cuDeviceTotalMem
0.10 2.59e-04 101 2.57e-06 7.33e-07 8.57e-05 cuDeviceGetAttribute
0.06 1.58e-04 3 5.25e-05 4.71e-06 1.44e-04 cudaFree
0.02 6.43e-05 3 2.14e-05 1.17e-05 2.74e-05 cudaMemcpy
0.01 3.55e-05 1 3.55e-05 3.55e-05 3.55e-05 cudaLaunchKernel
0.01 2.60e-05 1 2.60e-05 2.60e-05 2.60e-05 cuDeviceGetName
0.00 1.05e-05 1 1.05e-05 1.05e-05 1.05e-05 cudaDeviceSynchronize
0.00 9.46e-06 1 9.46e-06 9.46e-06 9.46e-06 cuDeviceGetPCIBusId
0.00 4.01e-06 3 1.34e-06 8.12e-07 2.04e-06 cuDeviceGetCount
0.00 2.58e-06 2 1.29e-06 7.99e-07 1.78e-06 cuDeviceGet
0.00 8.94e-07 1 8.94e-07 8.94e-07 8.94e-07 cuDeviceGetUuid
Comentarios
Las unidades en las que se reporta son s: second, ms: millisecond, us: microsecond, ns: nanosecond.
En la documentación de NVIDIA se menciona que
nvprofserá reemplazada próximamente por NVIDIA Nsight Compute y NVIDIA Nsight Systems.
En el ejemplo anterior se lanzaron \(N\) bloques con \(1\) thread cada uno y a continuación se lanza \(1\) bloque con \(N\) threads.
%%file vector_sum_2.cu
#include<stdio.h>
#define N 10
__global__ void vect_sum(int *a, int *b, int *c){
int thread_id_x = threadIdx.x;
if(thread_id_x<N)
c[thread_id_x] = a[thread_id_x]+b[thread_id_x];
}
int main(void){
int *device_a, *device_b, *device_c;
int i;
dim3 dimGrid(1,1,1);
dim3 dimBlock(N,1,1);
//allocation in device with Unified Memory
cudaMallocManaged(&device_a, sizeof(int)*N);
cudaMallocManaged(&device_b, sizeof(int)*N);
cudaMallocManaged(&device_c, sizeof(int)*N);
//dummy data
for(i=0;i<N;i++){
device_a[i]=i;
device_b[i]=i*i;
}
vect_sum<<<dimGrid,dimBlock>>>(device_a,device_b,device_c);
cudaDeviceSynchronize();
for(i=0;i<N;i++)
printf("%d+%d = %d\n",device_a[i],device_b[i],device_c[i]);
cudaFree(device_a);
cudaFree(device_b);
cudaFree(device_c);
return 0;
}
Writing vector_sum_2.cu
%%bash
source ~/.profile
nvcc -gencode arch=compute_37,code=sm_37 --compiler-options -Wall vector_sum_2.cu -o vector_sum_2.out
nvcc warning : The 'compute_35', 'compute_37', 'compute_50', 'sm_35', 'sm_37' and 'sm_50' architectures are deprecated, and may be removed in a future release (Use -Wno-deprecated-gpu-targets to suppress warning).
%%bash
source ~/.profile
nvprof --normalized-time-unit s ./vector_sum_2.out
0+0 = 0
1+1 = 2
2+4 = 6
3+9 = 12
4+16 = 20
5+25 = 30
6+36 = 42
7+49 = 56
8+64 = 72
9+81 = 90
==17829== NVPROF is profiling process 17829, command: ./vector_sum_2.out
==17829== Warning: Auto boost enabled on device 0. Profiling results may be inconsistent.
==17829== Profiling application: ./vector_sum_2.out
==17829== Profiling result:
Type Time(%) Time Calls Avg Min Max Name
% s s s s
GPU activities: 100.00 5.89e-06 1 5.89e-06 5.89e-06 5.89e-06 vect_sum(int*, int*, int*)
API calls: 99.57 0.294598 3 0.098199 5.80e-06 0.294578 cudaMallocManaged
0.18 5.23e-04 1 5.23e-04 5.23e-04 5.23e-04 cuDeviceTotalMem
0.09 2.68e-04 101 2.65e-06 7.37e-07 9.11e-05 cuDeviceGetAttribute
0.09 2.62e-04 1 2.62e-04 2.62e-04 2.62e-04 cudaLaunchKernel
0.05 1.35e-04 3 4.50e-05 9.83e-06 1.01e-04 cudaFree
0.01 3.49e-05 1 3.49e-05 3.49e-05 3.49e-05 cuDeviceGetName
0.01 1.92e-05 1 1.92e-05 1.92e-05 1.92e-05 cudaDeviceSynchronize
0.00 9.34e-06 1 9.34e-06 9.34e-06 9.34e-06 cuDeviceGetPCIBusId
0.00 3.96e-06 3 1.32e-06 7.76e-07 1.99e-06 cuDeviceGetCount
0.00 2.94e-06 2 1.47e-06 9.12e-07 2.02e-06 cuDeviceGet
0.00 9.58e-07 1 9.58e-07 9.58e-07 9.58e-07 cuDeviceGetUuid
==17829== Unified Memory profiling result:
Device "NVIDIA Tesla K80 (0)"
Count Avg Size Min Size Max Size Total Size Total Time Name
1 8.0000KB 8.0000KB 8.0000KB 8.000000KB 3.8720e-06s Host To Device
5 25.600KB 4.0000KB 60.000KB 128.0000KB 2.7422e-05s Device To Host
Total CPU Page faults: 2
Comentarios
El programa anterior utiliza la Unified Memory con la función cudaMallocManaged. La Unified Memory es un feature que se añadió a CUDA desde las arquitecturas de Kepler y Maxwell pero que ha ido mejorando (por ejemplo añadiendo page faulting and migration) en las arquitecturas siguientes a la de Kepler: la arquitectura Pascal y Volta. Por esto en el output anterior de nvprof aparece una sección de page fault.
Al igual que antes, en el programa anterior se asume que \(N\) el número de datos en el arreglo es menor al número de threads que es posible lanzar. Esto como veremos más adelante es importante considerar pues aunque en el device se pueden lanzar muchos bloques y muchos threads, se tienen límites en el número de éstos que es posible lanzar.
¿Tenemos que inicializar los datos en la CPU y copiarlos hacia la GPU?#
En realidad no tenemos que realizarlo para el ejemplo de vector_sum_3.cu.
%%file vector_sum_3.cu
#include<stdio.h>
#define N 10
__global__ void fill_arrays(int *a, int *b){
int thread_id_x = threadIdx.x;
a[thread_id_x]=thread_id_x;
b[thread_id_x]=thread_id_x*thread_id_x;
}
__global__ void vect_sum(int *a, int *b, int *c){
int thread_id_x = threadIdx.x;
if(thread_id_x<N)
c[thread_id_x] = a[thread_id_x]+b[thread_id_x];
}
int main(void){
int *device_a, *device_b, *device_c;
int i;
dim3 dimGrid(1,1,1);
dim3 dimBlock(N,1,1);
//allocating using Unified Memory in device
cudaMallocManaged(&device_a, sizeof(int)*N);
cudaMallocManaged(&device_b, sizeof(int)*N);
cudaMallocManaged(&device_c, sizeof(int)*N);
fill_arrays<<<dimGrid,dimBlock>>>(device_a,device_b);
cudaDeviceSynchronize();
vect_sum<<<dimGrid,dimBlock>>>(device_a,device_b,device_c);
cudaDeviceSynchronize();
for(i=0;i<N;i++)
printf("%d+%d = %d\n",device_a[i],device_b[i],device_c[i]);
cudaFree(device_a);
cudaFree(device_b);
cudaFree(device_c);
return 0;
}
Writing vector_sum_3.cu
%%bash
source ~/.profile
nvcc -gencode arch=compute_37,code=sm_37 --compiler-options -Wall vector_sum_3.cu -o vector_sum_3.out
nvcc warning : The 'compute_35', 'compute_37', 'compute_50', 'sm_35', 'sm_37' and 'sm_50' architectures are deprecated, and may be removed in a future release (Use -Wno-deprecated-gpu-targets to suppress warning).
%%bash
source ~/.profile
nvprof --normalized-time-unit s ./vector_sum_3.out
0+0 = 0
1+1 = 2
2+4 = 6
3+9 = 12
4+16 = 20
5+25 = 30
6+36 = 42
7+49 = 56
8+64 = 72
9+81 = 90
==17875== NVPROF is profiling process 17875, command: ./vector_sum_3.out
==17875== Warning: Auto boost enabled on device 0. Profiling results may be inconsistent.
==17875== Profiling application: ./vector_sum_3.out
==17875== Profiling result:
Type Time(%) Time Calls Avg Min Max Name
% s s s s
GPU activities: 50.47 5.12e-06 1 5.12e-06 5.12e-06 5.12e-06 fill_arrays(int*, int*)
49.53 5.02e-06 1 5.02e-06 5.02e-06 5.02e-06 vect_sum(int*, int*, int*)
API calls: 99.55 0.293179 3 0.097726 6.68e-06 0.293161 cudaMallocManaged
0.18 5.16e-04 1 5.16e-04 5.16e-04 5.16e-04 cuDeviceTotalMem
0.12 3.40e-04 2 1.70e-04 1.54e-04 1.86e-04 cudaLaunchKernel
0.09 2.61e-04 101 2.59e-06 7.38e-07 8.75e-05 cuDeviceGetAttribute
0.05 1.36e-04 3 4.53e-05 9.37e-06 1.02e-04 cudaFree
0.01 3.53e-05 1 3.53e-05 3.53e-05 3.53e-05 cuDeviceGetName
0.01 3.11e-05 2 1.55e-05 1.39e-05 1.71e-05 cudaDeviceSynchronize
0.00 8.34e-06 1 8.34e-06 8.34e-06 8.34e-06 cuDeviceGetPCIBusId
0.00 4.03e-06 3 1.34e-06 7.84e-07 2.03e-06 cuDeviceGetCount
0.00 2.78e-06 2 1.39e-06 9.01e-07 1.88e-06 cuDeviceGet
0.00 8.84e-07 1 8.84e-07 8.84e-07 8.84e-07 cuDeviceGetUuid
==17875== Unified Memory profiling result:
Device "NVIDIA Tesla K80 (0)"
Count Avg Size Min Size Max Size Total Size Total Time Name
3 21.333KB 4.0000KB 52.000KB 64.00000KB 1.4625e-05s Device To Host
Total CPU Page faults: 1
Arquitectura de una GPU y límites en número de threads y bloques que podemos lanzar en el kernel#
Un device está compuesto por arreglos de streaming multiprocessors SM’s (también denotados como MP’s) y en cada SM encontramos un número (determinado por la arquitectura del device) de streaming processors SP’s que comparten el caché y unidades de control (que están dentro de cada SM):
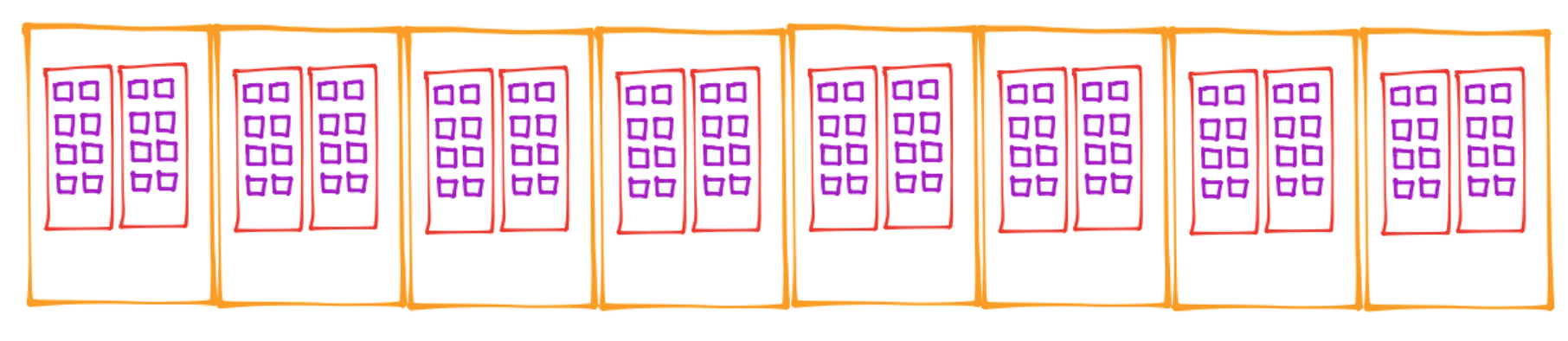
Ver Hardware model: streamingmultiprocessor.
En el dibujo anterior se muestran las SM’s en color rojo y los SP’s en morado. Hay dos SM’s por cada bloque anaranjado y ocho SP’s por cada SM. Así, una GPU es una máquina multicore. Aunque cada SM ejecuta las instrucciones de forma independiente a otra SM, comparten la memoria global.
Los bloques de threads son asignados a cada SM por el CUDA runtime system, el cual puede asignar más de un bloque a una SM pero hay un límite de bloques que pueden ser asignados a cada SM. Ver maximum number of blocks per multiprocessor.
Comentarios
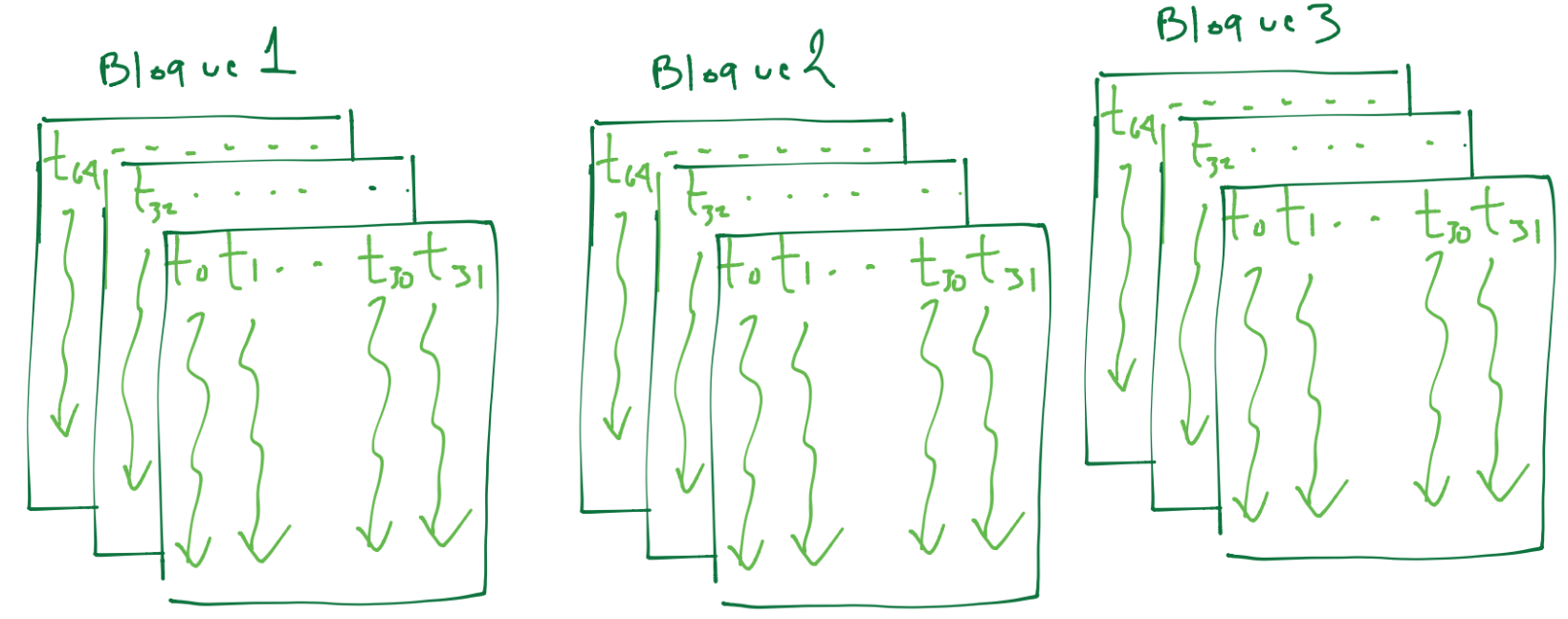
Por ejemplo para el modelo GT200 el máximo número de bloques que podían asignarse a cada SM eran de \(8\) bloques. Tal modelo tenía \(30\) SM’s lo que resultaban en \(240\) bloques que en un instante podían asignarse al device para su ejecución simultánea (asignándose en cualquier orden en alguna SM disponible). Por supuesto que un grid podía contener más de \(240\) bloques en este modelo y en este caso el CUDA runtime system lleva una lista de bloques que va asignando a cada SM y conforme cada SM terminan la ejecución, nuevos bloques son asignados a tales SM que finalizaron. Para visualizar esta situación, considérese una simplificación de lo anterior en donde se tiene un device con \(2\) SM’s y con un kernel se han lanzado \(6\) bloques. El CUDA runtime system ha asignado \(3\) bloques a cada SM, entonces se tiene un dibujo como el siguiente:
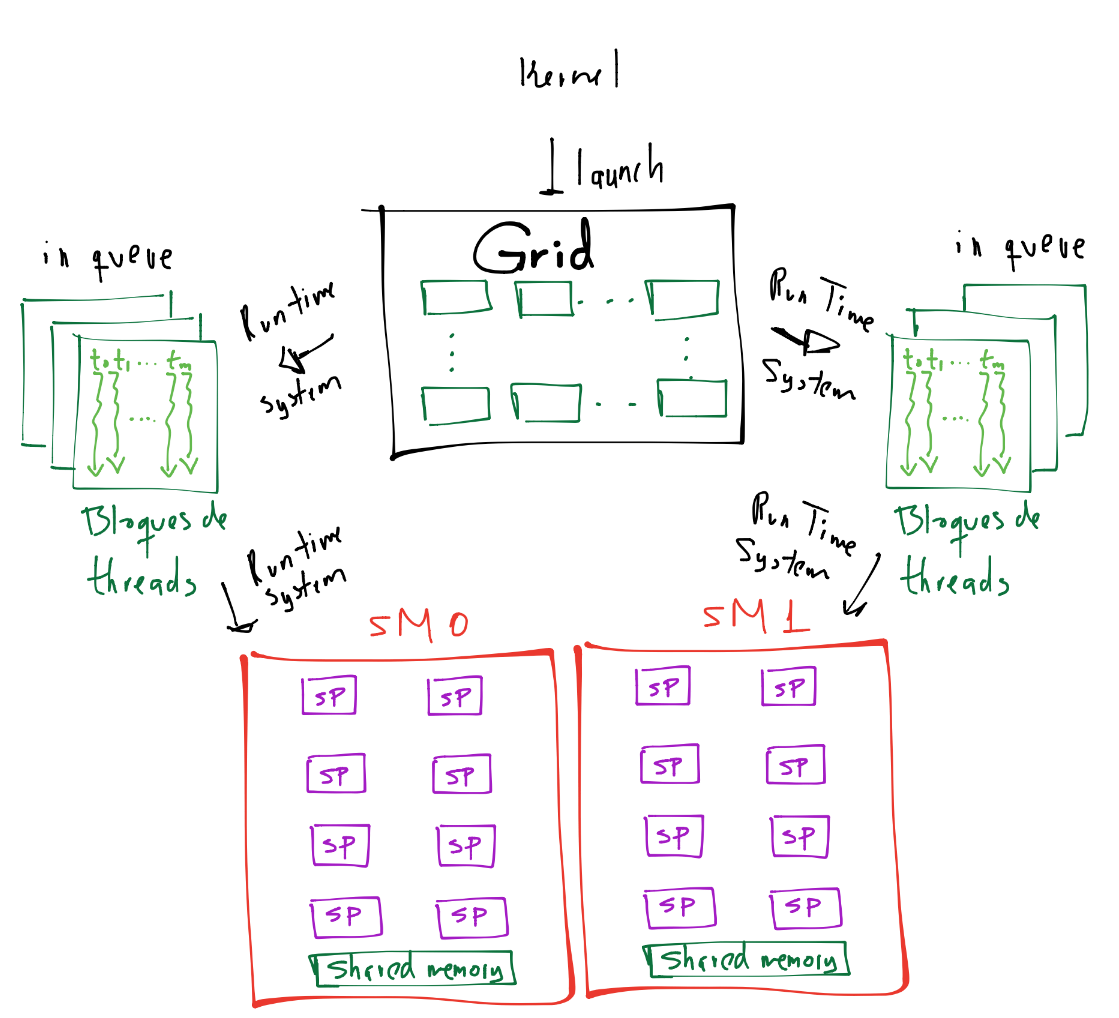
Los bloques asignados a una SM comparten recursos (por ejemplo memoria) y su ejecución es independiente entre ellos, no es posible sincronizar al bloque 1 con el bloque 0. También no es posible sincronizar a los threads de diferentes SM’s pero sí es posible sincronizar a los threads dentro de un mismo bloque.
¿Qué otros límites puedo encontrar en mi(s) device(s) de mi sistema?#
Para responder lo anterior se puede utilizar el siguiente programa que está basado en how-query-device-properties-and-handle-errors-cuda-cc y cudaDeviceProp Struct Reference.
%%file device_properties.cu
#include<stdio.h>
int main(void){
cudaDeviceProp properties;
int count;
int i;
cudaGetDeviceCount(&count);
for(i=0;i<count;i++){
printf("----------------------\n");
cudaGetDeviceProperties(&properties, i);
printf("----device %d ----\n",i);
printf("Device Name: %s\n", properties.name);
printf("Compute capability: %d.%d\n", properties.major, properties.minor);
printf("Clock rate: %d\n", properties.clockRate);
printf("Unified memory: %d\n", properties.unifiedAddressing);
printf(" ---Memory Information for device %d (results on bytes)---\n", i);
printf("Total global mem: %ld\n", properties.totalGlobalMem);
printf("Total constant Mem: %ld\n", properties.totalConstMem);
printf("Shared memory per thread block: %ld\n", properties.sharedMemPerBlock);
printf("Shared memory per SM: %ld\n",properties.sharedMemPerMultiprocessor );
printf(" ---MP Information for device %d ---\n", i);
printf("SM count: %d\n", properties.multiProcessorCount);
printf("Threads in warp: %d\n", properties.warpSize);
printf("Max threads per SM: %d\n", properties.maxThreadsPerMultiProcessor);
printf("Max warps per SM: %d\n",properties.maxThreadsPerMultiProcessor/properties.warpSize);
printf("Max threads per block: %d\n", properties.maxThreadsPerBlock);
printf("Max thread dimensions: (%d, %d, %d)\n", properties.maxThreadsDim[0], properties.maxThreadsDim[1], properties.maxThreadsDim[2]);
printf("Max grid dimensions: (%d, %d, %d)\n", properties.maxGridSize[0], properties.maxGridSize[1], properties.maxGridSize[2]);
}
return 0;
}
Writing device_properties.cu
%%bash
source ~/.profile
nvcc --compiler-options -Wall device_properties.cu -o device_properties.out
%%bash
./device_properties.out
----------------------
----device 0 ----
Device Name: NVIDIA Tesla K80
Compute capability: 3.7
Clock rate: 823500
Unified memory: 1
---Memory Information for device 0 (results on bytes)---
Total global mem: 11996954624
Total constant Mem: 65536
Shared memory per thread block: 49152
Shared memory per SM: 114688
---MP Information for device 0 ---
SM count: 13
Threads in warp: 32
Max threads per SM: 2048
Max warps per SM: 64
Max threads per block: 1024
Max thread dimensions: (1024, 1024, 64)
Max grid dimensions: (2147483647, 65535, 65535)
Comentarios
También en la documentación oficial de NVIDIA dentro de compute-capabilities se pueden revisar los valores anteriores y muchos más.
En un device encontramos diferentes tipos de memoria: global, constante, shared y texture. En esta nota únicamente trabajamos con la memoria global.
Tenemos funciones en CUDA para poder comunicar/coordinar a los threads en un bloque por medio de la shared memory. Ver por ejemplo Using Shared Memory in CUDA C/C++ para un pequeño post del \(2013\) sobre shared memory.
Los bloques de threads que son asignados a una SM son divididos en warps que es la unidad de thread scheduling que tiene el CUDA run time system. El output anterior indica que son divisiones de \(32\) threads.
El thread scheduling se puede pensar a la funcionalidad que tiene el hardware del device para seleccionar una instrucción del programa y asginar su ejecución por los threads en un warp (SIMT). Otro ejemplo es tener una instrucción que indica que se debe realizar lectura o escritura, entonces el hardware del device utiliza un warp de threads para tal operación mientras selecciona un warp de threads distinto para seleccionar otra instrucción diferente a la de I/O.
El número máximo de threads que pueden iniciarse de forma simultánea o en un instante por SM es de \(2048\) o bien \(2048/32 = 64\) warps.
El output anterior muestra los límites para número de bloques en las tres dimensiones de un grid y el número de threads en las tres dimensiones en un bloque.
Un bloque puede tener como máximo \(1024\) threads en cualquier configuración: por ejemplo \((1024,1,1), (32,1,32), (4,4,64)\).
Por los puntos anteriores si lanzamos bloques de \(1024\) threads entonces sólo \(2\) bloques pueden residir en una SM en un instante. Con esta configuración alcanzaríamos \(1024/32=32\) warps por cada bloque y como lanzamos \(2\) bloques alcanzaríamos \(64\) warps (que es el máximo de warps por SM que podemos tener en un instante). Otra configuración para alcanzar el máximo número de warps en un instante, es considerar \(4\) bloques de \(512\) threads pues tendríamos \(512/32=16\) warps por bloque y en total serían \(16*4\) (warps \(\times\) bloques) \(=64\) warps. Entre los datos que hay que elegir en los programas de CUDA C se encuentran las configuraciones en el número de threads y el número de bloques a lanzar. La idea es alcanzar o rebasar el máximo número de warps en cada SM que soporta nuestro device en un instante.
Por ejemplo para el dibujo en el que se asumió que el CUDA runtime system había asignado \(3\) bloques a cada SM, se tendría una división de cada bloque en un warp de \(32\) threads como sigue:
Grid Configuration Choices?#
Los programas de CUDA C tienen la opción de elegir el número de threads y de bloques a ser lanzados. En la referencia Parallel Computing for Data Science. With Examples in R, C++ and CUDA de N. Matloff se enlistan algunas consideraciones para elegir tales parámetros:
Given that scheduling is done on a warp basis, block size should be a multiple of the warp size (32).
One wants to utilize all the SMs. If one sets the block size too large, not all will be used, as a block cannot be split across SM’s.
…, barrier synchronization can be done effectively only at the block level. The larger the block, the more the barrier delay, so one might want smaller blocks.
On the other hand, if one is using shared memory, this can only be done at the block level, and efficient use may indicate using a larger block.
Two threads doing unrelated work, or the same work but with many if/elses, would cause a lot of thread divergence if they were in the same block. In some cases, it may be known in advance which threads will do the “ifs” and which will do the “elses”, in which case they should be placed in different blocks if possible.
A commonly-cited rule of thumb is to have between \(128\) and \(256\) threads per block.
Ejemplo regla compuesta del rectángulo#
En el uso de CUDA se recomienda que:
Users escriban código de CUDA C simple.
Utilicen las librerías ya hechas por NVIDIA o terceros para mantener simplicidad y eficiencia en el código.
Lo anterior para disminuir el tiempo y la cantidad de código que users tengan que hacer (o rehacer) y puesto que dominar la programación de CUDA C requiere una buena inversión de tiempo.
Así, tenemos a Thrust una template library basada en la Standard Template Library (STL) de C++ construída por NVIDIA que de acuerdo a su documentación:
Thrust provides a rich collection of data parallel primitives such as scan, sort, and reduce, which can be composed together to implement complex algorithms with concise, readable source code. By describing your computation in terms of these high-level abstractions you provide Thrust with the freedom to select the most efficient implementation automatically. As a result, Thrust can be utilized in rapid prototyping of CUDA applications, where programmer productivity matters most, as well as in production, where robustness and absolute performance are crucial.
Thrust tiene la opción de utilizarse con OpenMP, Thread Building Blocks (TBB) y con CUDA C++. Ver por ejemplo Device Backends para conocer cómo cambiar entre OpenMP y CUDA C++, lo cual se realiza en la compilación y ¡sin hacer cambios en el código!.
Comentarios
Al software que aprovecha el feature anterior de los sistemas computacionales (por ejemplo cambiar entre OpenMP y CUDA C++) se les nombra Heterogeneous computing.
Si se instala el CUDA toolkit, los headers en la librería template de
Thrustestarán disponibles para su uso.
En el siguiente ejemplo de la regla del rectángulo compuesta se utiliza:
Los headers:
Se hace explícito el uso de la política de ejecucion thrust::device.
Referencias para el programa siguiente se encuentran en thrust inside user written kernels y cuda how to sum all elements of an array into one number within the gpu.
Primero utilicemos \(n=10^3\) subintervalos.
%%file Rcf.cu
#include<stdio.h>
#include <thrust/reduce.h>
#include <thrust/execution_policy.h>
__global__ void Rcf(double *data, double a, double h_hat, int n, double *sum_res ) {
/*
Compute numerical approximation using rectangle or mid-point method in
an interval.
Nodes are generated via formula: x_i = a+(i+1/2)h_hat for i=0,1,...,n-1 and h_hat=(b-a)/n
Args:
data (double): array that will hold values evaluated in function
a (int): left point of interval
h_hat (double): width of subinterval
n (int): number of subintervals
sum_res (double): pointer to result
Returns:
sum_res (double): pointer to result
*/
double x=0.0;
if(threadIdx.x<=n-1){
x=a+(threadIdx.x+1/2.0)*h_hat;
data[threadIdx.x]=std::exp(-std::pow(x,2));
}
if(threadIdx.x==0){
*sum_res = thrust::reduce(thrust::device, data , data + n, (double)0, thrust::plus<double>());
}
}
int main(int argc, char *argv[]){
double sum_res=0.0;
double *d_data;
double *d_sum;
double a=0.0, b=1.0;
double h_hat;
int n=1e3;
double obj=0.7468241328124271;
double time_spent;
clock_t begin,end;
cudaMalloc((void **)&d_data,sizeof(double)*n);
cudaMalloc((void**)&d_sum,sizeof(double));
h_hat=(b-a)/n;
begin=clock();
Rcf<<<1,n>>>(d_data, a,h_hat,n,d_sum);
cudaDeviceSynchronize();
end=clock();
time_spent = (double)(end - begin) / CLOCKS_PER_SEC;
cudaMemcpy(&sum_res, d_sum, sizeof(double), cudaMemcpyDeviceToHost);
sum_res=h_hat*sum_res;
cudaFree(d_data) ;
cudaFree(d_sum) ;
printf("Integral de %f a %f = %1.15e\n", a,b,sum_res);
printf("Error relativo de la solución: %1.15e\n", fabs(sum_res-obj)/fabs(obj));
printf("Tiempo de cálculo en la gpu %.5f\n", time_spent);
return 0;
}
Writing Rcf.cu
%%bash
source ~/.profile
nvcc -gencode arch=compute_37,code=sm_37 --compiler-options -Wall Rcf.cu -o Rcf.out
nvcc warning : The 'compute_35', 'compute_37', 'compute_50', 'sm_35', 'sm_37' and 'sm_50' architectures are deprecated, and may be removed in a future release (Use -Wno-deprecated-gpu-targets to suppress warning).
%%bash
./Rcf.out
Integral de 0.000000 a 1.000000 = 7.468241634690490e-01
Error relativo de la solución: 4.104931878976858e-08
Tiempo de cálculo en la gpu 0.00014
%%bash
source ~/.profile
nvprof --normalized-time-unit s ./Rcf.out
Integral de 0.000000 a 1.000000 = 7.468241634690490e-01
Error relativo de la solución: 4.104931878976858e-08
Tiempo de cálculo en la gpu 0.00019
==18211== NVPROF is profiling process 18211, command: ./Rcf.out
==18211== Warning: Auto boost enabled on device 0. Profiling results may be inconsistent.
==18211== Warning: Profiling results might be incorrect with current version of nvcc compiler used to compile cuda app. Compile with nvcc compiler 9.0 or later version to get correct profiling results. Ignore this warning if code is already compiled with the recommended nvcc version
==18211== Profiling application: ./Rcf.out
==18211== Profiling result:
Type Time(%) Time Calls Avg Min Max Name
% s s s s
GPU activities: 97.53 1.01e-04 1 1.01e-04 1.01e-04 1.01e-04 Rcf(double*, double, double, int, double*)
2.47 2.56e-06 1 2.56e-06 2.56e-06 2.56e-06 [CUDA memcpy DtoH]
API calls: 99.58 0.285237 2 0.142618 6.00e-06 0.285231 cudaMalloc
0.18 5.22e-04 1 5.22e-04 5.22e-04 5.22e-04 cuDeviceTotalMem
0.10 2.84e-04 101 2.81e-06 7.33e-07 9.81e-05 cuDeviceGetAttribute
0.05 1.48e-04 2 7.41e-05 9.64e-06 1.38e-04 cudaFree
0.04 1.08e-04 1 1.08e-04 1.08e-04 1.08e-04 cudaDeviceSynchronize
0.02 6.53e-05 1 6.53e-05 6.53e-05 6.53e-05 cudaLaunchKernel
0.01 3.28e-05 1 3.28e-05 3.28e-05 3.28e-05 cudaMemcpy
0.01 3.16e-05 1 3.16e-05 3.16e-05 3.16e-05 cuDeviceGetName
0.00 9.56e-06 1 9.56e-06 9.56e-06 9.56e-06 cuDeviceGetPCIBusId
0.00 4.41e-06 3 1.47e-06 7.78e-07 2.30e-06 cuDeviceGetCount
0.00 2.58e-06 2 1.29e-06 8.15e-07 1.76e-06 cuDeviceGet
0.00 9.06e-07 1 9.06e-07 9.06e-07 9.06e-07 cuDeviceGetUuid
Incrementemos a \(n=1025\) subintervalos.
%%file Rcf2.cu
#include<stdio.h>
#include <thrust/reduce.h>
#include <thrust/execution_policy.h>
__global__ void Rcf(double *data, double a, double h_hat, int n, double *sum_res ) {
/*
Compute numerical approximation using rectangle or mid-point method in
an interval.
Nodes are generated via formula: x_i = a+(i+1/2)h_hat for i=0,1,...,n-1 and h_hat=(b-a)/n
Args:
data (double): array that will hold values evaluated in function
a (int): left point of interval
h_hat (double): width of subinterval
n (int): number of subintervals
sum_res (double): pointer to result
Returns:
sum_res (double): pointer to result
*/
double x=0.0;
if(threadIdx.x<=n-1){
x=a+(threadIdx.x+1/2.0)*h_hat;
data[threadIdx.x]=std::exp(-std::pow(x,2));
}
if(threadIdx.x==0){
*sum_res = thrust::reduce(thrust::device, data , data + n, (double)0, thrust::plus<double>());
}
}
int main(int argc, char *argv[]){
double sum_res=0.0;
double *d_data;
double *d_sum;
double a=0.0, b=1.0;
double h_hat;
int n=1025;
double obj=0.7468241328124271;
double time_spent;
clock_t begin,end;
cudaMalloc((void **)&d_data,sizeof(double)*n);
cudaMalloc((void**)&d_sum,sizeof(double));
h_hat=(b-a)/n;
begin=clock();
Rcf<<<1,n>>>(d_data, a,h_hat,n,d_sum);
cudaDeviceSynchronize();
end=clock();
time_spent = (double)(end - begin) / CLOCKS_PER_SEC;
cudaMemcpy(&sum_res, d_sum, sizeof(double), cudaMemcpyDeviceToHost);
sum_res=h_hat*sum_res;
cudaFree(d_data) ;
cudaFree(d_sum) ;
printf("Integral de %f a %f = %1.15e\n", a,b,sum_res);
printf("Error relativo de la solución: %1.15e\n", fabs(sum_res-obj)/fabs(obj));
printf("Tiempo de cálculo en la gpu %.5f\n", time_spent);
return 0;
}
Writing Rcf2.cu
%%bash
source ~/.profile
nvcc -gencode arch=compute_37,code=sm_37 --compiler-options -Wall Rcf2.cu -o Rcf2.out
nvcc warning : The 'compute_35', 'compute_37', 'compute_50', 'sm_35', 'sm_37' and 'sm_50' architectures are deprecated, and may be removed in a future release (Use -Wno-deprecated-gpu-targets to suppress warning).
%%bash
./Rcf2.out
Integral de 0.000000 a 1.000000 = 0.000000000000000e+00
Error relativo de la solución: 1.000000000000000e+00
Tiempo de cálculo en la gpu 0.00001
Observación
Obsérvese error relativo de \(100\%\)
¿Cómo lo arreglamos?
%%file Rcf3.cu
#include<stdio.h>
#include <thrust/reduce.h>
#include <thrust/execution_policy.h>
__global__ void Rcf(double *data, double a, double h_hat, int n, double *sum_res) {
/*
Compute numerical approximation using rectangle or mid-point method in
an interval.
Nodes are generated via formula: x_i = a+(i+1/2)h_hat for i=0,1,...,n-1 and h_hat=(b-a)/n
Args:
data (double): array that will hold values evaluated in function
a (int): left point of interval
h_hat (double): width of subinterval
n (int): number of subintervals
sum_res (double): pointer to result
Returns:
sum_res (double): pointer to result
*/
double x=0.0;
int stride=0;
if(threadIdx.x<=n-1){
x=a+(threadIdx.x+1/2.0)*h_hat;
data[threadIdx.x]=std::exp(-std::pow(x,2));
}
if(threadIdx.x==0){
stride=blockDim.x;
x=a+(threadIdx.x+stride+1/2.0)*h_hat;
data[threadIdx.x+stride]=std::exp(-std::pow(x,2));
*sum_res = thrust::reduce(thrust::device, data , data + n, (double)0, thrust::plus<double>());
}
}
int main(int argc, char *argv[]){
double sum_res=0.0;
double *d_data;
double *d_sum;
double a=0.0, b=1.0;
double h_hat;
int n_threads_per_block=1024;
int n_blocks=2;
int n=1025;
double obj=0.7468241328124271;
double time_spent;
clock_t begin,end;
cudaMalloc((void **)&d_data,sizeof(double)*n);
cudaMalloc((void**)&d_sum,sizeof(double));
h_hat=(b-a)/n;
begin=clock();
Rcf<<<n_blocks,n_threads_per_block>>>(d_data, a,h_hat,n,d_sum);
cudaDeviceSynchronize();
end=clock();
time_spent = (double)(end - begin) / CLOCKS_PER_SEC;
cudaMemcpy(&sum_res, d_sum, sizeof(double), cudaMemcpyDeviceToHost);
sum_res=h_hat*sum_res;
cudaFree(d_data) ;
cudaFree(d_sum) ;
printf("Integral de %f a %f = %1.15e\n", a,b,sum_res);
printf("Error relativo de la solución: %1.15e\n", fabs(sum_res-obj)/fabs(obj));
printf("Tiempo de cálculo en la gpu %.5f\n", time_spent);
return 0;
}
Writing Rcf3.cu
%%bash
source ~/.profile
nvcc -gencode arch=compute_37,code=sm_37 --compiler-options -Wall Rcf3.cu -o Rcf3.out
nvcc warning : The 'compute_35', 'compute_37', 'compute_50', 'sm_35', 'sm_37' and 'sm_50' architectures are deprecated, and may be removed in a future release (Use -Wno-deprecated-gpu-targets to suppress warning).
%%bash
./Rcf3.out
Integral de 0.000000 a 1.000000 = 7.468241619918411e-01
Error relativo de la solución: 3.907133247860604e-08
Tiempo de cálculo en la gpu 0.00015
Pero en la propuesta anterior lanzamos \(2*1024\) (bloques \(\times\) número de threads) \(=2048\) threads y sólo ocupamos \(1025\) threads. Entonces podemos cambiar el código anterior para aprovechar los \(2048\) threads como sigue:
%%file Rcf4.cu
#include<stdio.h>
#include <thrust/reduce.h>
#include <thrust/execution_policy.h>
__global__ void Rcf(double *data, double a, double h_hat, int n, double *sum_res) {
/*
Compute numerical approximation using rectangle or mid-point method in
an interval.
Nodes are generated via formula: x_i = a+(i+1/2)h_hat for i=0,1,...,n-1 and h_hat=(b-a)/n
Args:
data (double): array that will hold values evaluated in function
a (int): left point of interval
h_hat (double): width of subinterval
n (int): number of subintervals
sum_res (double): pointer to result
Returns:
sum_res (double): pointer to result
*/
double x=0.0;
int stride=0;
int i;
stride=blockDim.x;
for(i=threadIdx.x;i<=n-1;i+=stride){
if(i<=n-1){
x=a+(i+1/2.0)*h_hat;
data[i]=std::exp(-std::pow(x,2));
}
}
if(threadIdx.x==0){
*sum_res = thrust::reduce(thrust::device, data , data + n, (double)0, thrust::plus<double>());
}
}
int main(int argc, char *argv[]){
double sum_res=0.0;
double *d_data;
double *d_sum;
double a=0.0, b=1.0;
double h_hat;
int n_threads_per_block=1024;
int n_blocks=2;
int n=n_threads_per_block*n_blocks;
double obj=0.7468241328124271;
double time_spent;
clock_t begin,end;
cudaMalloc((void **)&d_data,sizeof(double)*n);
cudaMalloc((void**)&d_sum,sizeof(double));
h_hat=(b-a)/n;
begin=clock();
Rcf<<<n_blocks,n_threads_per_block>>>(d_data, a,h_hat,n,d_sum);
cudaDeviceSynchronize();
end=clock();
time_spent = (double)(end - begin) / CLOCKS_PER_SEC;
cudaMemcpy(&sum_res, d_sum, sizeof(double), cudaMemcpyDeviceToHost);
sum_res=h_hat*sum_res;
cudaFree(d_data) ;
cudaFree(d_sum) ;
printf("Integral de %f a %f = %1.15e\n", a,b,sum_res);
printf("Error relativo de la solución: %1.15e\n", fabs(sum_res-obj)/fabs(obj));
printf("Tiempo de cálculo en la gpu %.5f\n", time_spent);
return 0;
}
Writing Rcf4.cu
%%bash
source ~/.profile
nvcc -gencode arch=compute_37,code=sm_37 --compiler-options -Wall Rcf4.cu -o Rcf4.out
nvcc warning : The 'compute_35', 'compute_37', 'compute_50', 'sm_35', 'sm_37' and 'sm_50' architectures are deprecated, and may be removed in a future release (Use -Wno-deprecated-gpu-targets to suppress warning).
%%bash
./Rcf4.out
Integral de 0.000000 a 1.000000 = 7.468241401215338e-01
Error relativo de la solución: 9.786918140590463e-09
Tiempo de cálculo en la gpu 0.00024
Y podemos no utilizar el ciclo for.
%%file Rcf5.cu
#include<stdio.h>
#include <thrust/reduce.h>
#include <thrust/execution_policy.h>
__global__ void Rcf(double *data, double a, double h_hat, int n, double *sum_res ) {
/*
Compute numerical approximation using rectangle or mid-point method in
an interval.
Nodes are generated via formula: x_i = a+(i+1/2)h_hat for i=0,1,...,n-1 and h_hat=(b-a)/n
Args:
data (double): array that will hold values evaluated in function
a (int): left point of interval
h_hat (double): width of subinterval
n (int): number of subintervals
sum_res (double): pointer to result
Returns:
sum_res (double): pointer to result
*/
double x=0.0;
int idx;
idx = blockIdx.x * blockDim.x + threadIdx.x;
if(idx<=n-1){
x=a+(idx+1/2.0)*h_hat;
data[idx]=std::exp(-std::pow(x,2));
}
if(idx==0){
*sum_res = thrust::reduce(thrust::device, data , data + n, (double)0, thrust::plus<double>());
}
}
int main(int argc, char *argv[]){
double sum_res=0.0;
double *d_data;
double *d_sum;
double a=0.0, b=1.0;
double h_hat;
int n_threads_per_block=1024;
int n_blocks=2;
double obj=0.7468241328124271;
int n=n_blocks*n_threads_per_block;//number of subintervals
double time_spent;
clock_t begin,end;
cudaMalloc((void **)&d_data,sizeof(double)*n);
cudaMalloc((void**)&d_sum,sizeof(double));
h_hat=(b-a)/n;
begin = clock();
Rcf<<<n_blocks,n_threads_per_block>>>(d_data, a,h_hat,n,d_sum);
cudaDeviceSynchronize();
end = clock();
time_spent = (double)(end - begin) / CLOCKS_PER_SEC;
cudaMemcpy(&sum_res, d_sum, sizeof(double), cudaMemcpyDeviceToHost);
sum_res=h_hat*sum_res;
cudaFree(d_data) ;
cudaFree(d_sum) ;
printf("Integral de %f a %f = %1.15e\n", a,b,sum_res);
printf("Error relativo de la solución: %1.15e\n", fabs(sum_res-obj)/fabs(obj));
printf("Tiempo de cálculo en la gpu %.5f\n", time_spent);
return 0;
}
Writing Rcf5.cu
%%bash
source ~/.profile
nvcc -gencode arch=compute_37,code=sm_37 --compiler-options -Wall Rcf5.cu -o Rcf5.out
nvcc warning : The 'compute_35', 'compute_37', 'compute_50', 'sm_35', 'sm_37' and 'sm_50' architectures are deprecated, and may be removed in a future release (Use -Wno-deprecated-gpu-targets to suppress warning).
%%bash
./Rcf5.out
Integral de 0.000000 a 1.000000 = 7.468241401215338e-01
Error relativo de la solución: 9.786918140590463e-09
Tiempo de cálculo en la gpu 0.00024
%%bash
source ~/.profile
nvprof --normalized-time-unit s ./Rcf5.out
Integral de 0.000000 a 1.000000 = 7.468241401215338e-01
Error relativo de la solución: 9.786918140590463e-09
Tiempo de cálculo en la gpu 0.00028
==18401== NVPROF is profiling process 18401, command: ./Rcf5.out
==18401== Warning: Auto boost enabled on device 0. Profiling results may be inconsistent.
==18401== Warning: Profiling results might be incorrect with current version of nvcc compiler used to compile cuda app. Compile with nvcc compiler 9.0 or later version to get correct profiling results. Ignore this warning if code is already compiled with the recommended nvcc version
==18401== Profiling application: ./Rcf5.out
==18401== Profiling result:
Type Time(%) Time Calls Avg Min Max Name
% s s s s
GPU activities: 98.70 1.95e-04 1 1.95e-04 1.95e-04 1.95e-04 Rcf(double*, double, double, int, double*)
1.30 2.56e-06 1 2.56e-06 2.56e-06 2.56e-06 [CUDA memcpy DtoH]
API calls: 99.51 0.258055 2 0.129027 4.82e-06 0.258050 cudaMalloc
0.20 5.14e-04 1 5.14e-04 5.14e-04 5.14e-04 cuDeviceTotalMem
0.10 2.58e-04 101 2.56e-06 7.36e-07 8.51e-05 cuDeviceGetAttribute
0.08 2.00e-04 1 2.00e-04 2.00e-04 2.00e-04 cudaDeviceSynchronize
0.06 1.49e-04 2 7.45e-05 9.64e-06 1.39e-04 cudaFree
0.03 6.99e-05 1 6.99e-05 6.99e-05 6.99e-05 cudaLaunchKernel
0.01 3.26e-05 1 3.26e-05 3.26e-05 3.26e-05 cudaMemcpy
0.01 2.71e-05 1 2.71e-05 2.71e-05 2.71e-05 cuDeviceGetName
0.00 9.56e-06 1 9.56e-06 9.56e-06 9.56e-06 cuDeviceGetPCIBusId
0.00 4.23e-06 3 1.41e-06 9.18e-07 2.18e-06 cuDeviceGetCount
0.00 2.52e-06 2 1.26e-06 8.01e-07 1.72e-06 cuDeviceGet
0.00 9.07e-07 1 9.07e-07 9.07e-07 9.07e-07 cuDeviceGetUuid
Utilicemos más nodos.
Para el siguiente código, incrementamos el número de bloques.
%%file Rcf6.cu
#include<stdio.h>
#include <thrust/reduce.h>
#include <thrust/execution_policy.h>
__global__ void Rcf(double *data, double a, double h_hat, int n, double *sum_res ) {
/*
Compute numerical approximation using rectangle or mid-point method in
an interval.
Nodes are generated via formula: x_i = a+(i+1/2)h_hat for i=0,1,...,n-1 and h_hat=(b-a)/n
Args:
data (double): array that will hold values evaluated in function
a (int): left point of interval
h_hat (double): width of subinterval
n (int): number of subintervals
sum_res (double): pointer to result
Returns:
sum_res (double): pointer to result
*/
double x=0.0;
int idx;
idx = blockIdx.x * blockDim.x + threadIdx.x;
if(idx<=n-1){
x=a+(idx+1/2.0)*h_hat;
data[idx]=std::exp(-std::pow(x,2));
}
if(idx==0){
*sum_res = thrust::reduce(thrust::device, data , data + n, (double)0, thrust::plus<double>());
}
}
int main(int argc, char *argv[]){
double sum_res=0.0;
double *d_data;
double *d_sum;
double a=0.0, b=1.0;
double h_hat;
int n_threads_per_block=1024;
int n_blocks=0;
double obj=0.7468241328124271;
int n=0;
double time_spent;
clock_t begin,end;
cudaDeviceProp properties;
cudaGetDeviceProperties(&properties, 0);
//we choose a multiple of the number of SMs.
n_blocks = 256 * properties.multiProcessorCount;
n = n_blocks*n_threads_per_block;
cudaMalloc((void **)&d_data,sizeof(double)*n);
cudaMalloc((void**)&d_sum,sizeof(double));
h_hat=(b-a)/n;
begin = clock();
Rcf<<<n_blocks,n_threads_per_block>>>(d_data, a,h_hat,n,d_sum);
cudaDeviceSynchronize();
end = clock();
time_spent = (double)(end - begin) / CLOCKS_PER_SEC;
cudaMemcpy(&sum_res, d_sum, sizeof(double), cudaMemcpyDeviceToHost);
sum_res=h_hat*sum_res;
cudaFree(d_data) ;
cudaFree(d_sum) ;
printf("Número de subintervalos: %d\n", n);
printf("Integral de %f a %f = %1.15e\n", a,b,sum_res);
printf("Error relativo de la solución: %1.15e\n", fabs(sum_res-obj)/fabs(obj));
printf("Tiempo de cálculo en la gpu %.5f\n", time_spent);
return 0;
}
Writing Rcf6.cu
%%bash
source ~/.profile
nvcc -gencode arch=compute_37,code=sm_37 --compiler-options -Wall Rcf6.cu -o Rcf6.out
nvcc warning : The 'compute_35', 'compute_37', 'compute_50', 'sm_35', 'sm_37' and 'sm_50' architectures are deprecated, and may be removed in a future release (Use -Wno-deprecated-gpu-targets to suppress warning).
Observación
Mientras se ejecuta la siguiente celda se sugiere en la terminal ejecutar en la línea de comando nvtop.
%%bash
./Rcf6.out
Número de subintervalos: 3407872
Integral de 0.000000 a 1.000000 = 7.468241328124654e-01
Error relativo de la solución: 5.128743524305478e-14
Tiempo de cálculo en la gpu 0.42854
%%bash
source ~/.profile
nvprof --normalized-time-unit s ./Rcf6.out
Número de subintervalos: 3407872
Integral de 0.000000 a 1.000000 = 7.468241328124654e-01
Error relativo de la solución: 5.128743524305478e-14
Tiempo de cálculo en la gpu 0.38611
==18515== NVPROF is profiling process 18515, command: ./Rcf6.out
==18515== Warning: Auto boost enabled on device 0. Profiling results may be inconsistent.
==18515== Warning: Profiling results might be incorrect with current version of nvcc compiler used to compile cuda app. Compile with nvcc compiler 9.0 or later version to get correct profiling results. Ignore this warning if code is already compiled with the recommended nvcc version
==18515== Profiling application: ./Rcf6.out
==18515== Profiling result:
Type Time(%) Time Calls Avg Min Max Name
% s s s s
GPU activities: 100.00 0.386719 1 0.386719 0.386719 0.386719 Rcf(double*, double, double, int, double*)
0.00 3.23e-06 1 3.23e-06 3.23e-06 3.23e-06 [CUDA memcpy DtoH]
API calls: 58.94 0.386743 1 0.386743 0.386743 0.386743 cudaDeviceSynchronize
40.45 0.265420 2 0.132710 1.41e-04 0.265279 cudaMalloc
0.43 2.85e-03 2 1.43e-03 2.51e-04 2.60e-03 cudaFree
0.08 5.46e-04 1 5.46e-04 5.46e-04 5.46e-04 cuDeviceTotalMem
0.04 2.65e-04 101 2.62e-06 7.41e-07 8.77e-05 cuDeviceGetAttribute
0.03 1.72e-04 1 1.72e-04 1.72e-04 1.72e-04 cudaGetDeviceProperties
0.01 7.08e-05 1 7.08e-05 7.08e-05 7.08e-05 cudaMemcpy
0.01 6.56e-05 1 6.56e-05 6.56e-05 6.56e-05 cudaLaunchKernel
0.00 2.80e-05 1 2.80e-05 2.80e-05 2.80e-05 cuDeviceGetName
0.00 8.45e-06 1 8.45e-06 8.45e-06 8.45e-06 cuDeviceGetPCIBusId
0.00 4.07e-06 3 1.36e-06 7.75e-07 2.08e-06 cuDeviceGetCount
0.00 2.56e-06 2 1.28e-06 8.00e-07 1.76e-06 cuDeviceGet
0.00 9.30e-07 1 9.30e-07 9.30e-07 9.30e-07 cuDeviceGetUuid
Incrementamos el número de subintervalos.
%%file Rcf7.cu
#include<stdio.h>
#include <thrust/reduce.h>
#include <thrust/execution_policy.h>
__global__ void Rcf(double *data, double a, double h_hat, int n, double *sum_res ) {
/*
Compute numerical approximation using rectangle or mid-point method in
an interval.
Nodes are generated via formula: x_i = a+(i+1/2)h_hat for i=0,1,...,n-1 and h_hat=(b-a)/n
Args:
data (double): array that will hold values evaluated in function
a (int): left point of interval
h_hat (double): width of subinterval
n (int): number of subintervals
sum_res (double): pointer to result
Returns:
sum_res (double): pointer to result
*/
double x=0.0;
int idx;
idx = blockIdx.x * blockDim.x + threadIdx.x;
if(idx<=n-1){
x=a+(idx+1/2.0)*h_hat;
data[idx]=std::exp(-std::pow(x,2));
}
if(idx==0){
*sum_res = thrust::reduce(thrust::device, data , data + n, (double)0, thrust::plus<double>());
}
}
int main(int argc, char *argv[]){
double sum_res=0.0;
double *d_data;
double *d_sum;
double a=0.0, b=1.0;
double h_hat;
int n_threads_per_block=512;
int n_blocks=0;
double obj=0.7468241328124271;
int n=0;
double time_spent;
clock_t begin,end;
cudaDeviceProp properties;
cudaGetDeviceProperties(&properties, 0);
n_blocks = 1500 * properties.multiProcessorCount;
n = n_blocks*n_threads_per_block;
cudaMalloc((void **)&d_data,sizeof(double)*n);
cudaMalloc((void**)&d_sum,sizeof(double));
h_hat=(b-a)/n;
begin = clock();
Rcf<<<n_blocks,n_threads_per_block>>>(d_data, a,h_hat,n,d_sum);
cudaDeviceSynchronize();
end = clock();
time_spent = (double)(end - begin) / CLOCKS_PER_SEC;
cudaMemcpy(&sum_res, d_sum, sizeof(double), cudaMemcpyDeviceToHost);
sum_res=h_hat*sum_res;
cudaFree(d_data) ;
cudaFree(d_sum) ;
printf("Número de subintervalos: %d\n", n);
printf("Integral de %f a %f = %1.15e\n", a,b,sum_res);
printf("Error relativo de la solución: %1.15e\n", fabs(sum_res-obj)/fabs(obj));
printf("Tiempo de cálculo en la gpu %.5f\n", time_spent);
return 0;
}
Writing Rcf7.cu
%%bash
source ~/.profile
nvcc -gencode arch=compute_37,code=sm_37 --compiler-options -Wall Rcf7.cu -o Rcf7.out
nvcc warning : The 'compute_35', 'compute_37', 'compute_50', 'sm_35', 'sm_37' and 'sm_50' architectures are deprecated, and may be removed in a future release (Use -Wno-deprecated-gpu-targets to suppress warning).
Observación
Mientras se ejecuta la siguiente celda se sugiere en la terminal ejecutar en la línea de comando nvtop.
%%bash
./Rcf7.out
Número de subintervalos: 9984000
Integral de 0.000000 a 1.000000 = 7.468241328124303e-01
Error relativo de la solución: 4.311117745068373e-15
Tiempo de cálculo en la gpu 1.10993
%%bash
source ~/.profile
nvprof --normalized-time-unit s ./Rcf7.out
Número de subintervalos: 9984000
Integral de 0.000000 a 1.000000 = 7.468241328124303e-01
Error relativo de la solución: 4.311117745068373e-15
Tiempo de cálculo en la gpu 1.12291
==18755== NVPROF is profiling process 18755, command: ./Rcf7.out
==18755== Warning: Auto boost enabled on device 0. Profiling results may be inconsistent.
==18755== Warning: Profiling results might be incorrect with current version of nvcc compiler used to compile cuda app. Compile with nvcc compiler 9.0 or later version to get correct profiling results. Ignore this warning if code is already compiled with the recommended nvcc version
==18755== Profiling application: ./Rcf7.out
==18755== Profiling result:
Type Time(%) Time Calls Avg Min Max Name
% s s s s
GPU activities: 100.00 1.121829 1 1.121829 1.121829 1.121829 Rcf(double*, double, double, int, double*)
0.00 2.24e-06 1 2.24e-06 2.24e-06 2.24e-06 [CUDA memcpy DtoH]
API calls: 80.22 1.121856 1 1.121856 1.121856 1.121856 cudaDeviceSynchronize
19.21 0.268620 2 0.134310 1.46e-04 0.268474 cudaMalloc
0.49 6.86e-03 2 3.43e-03 2.98e-04 6.56e-03 cudaFree
0.04 5.16e-04 1 5.16e-04 5.16e-04 5.16e-04 cuDeviceTotalMem
0.02 2.75e-04 101 2.72e-06 7.35e-07 9.35e-05 cuDeviceGetAttribute
0.01 1.89e-04 1 1.89e-04 1.89e-04 1.89e-04 cudaGetDeviceProperties
0.01 8.55e-05 1 8.55e-05 8.55e-05 8.55e-05 cudaLaunchKernel
0.00 6.15e-05 1 6.15e-05 6.15e-05 6.15e-05 cudaMemcpy
0.00 3.98e-05 1 3.98e-05 3.98e-05 3.98e-05 cuDeviceGetName
0.00 9.34e-06 1 9.34e-06 9.34e-06 9.34e-06 cuDeviceGetPCIBusId
0.00 3.96e-06 3 1.32e-06 7.68e-07 1.83e-06 cuDeviceGetCount
0.00 2.41e-06 2 1.20e-06 7.43e-07 1.67e-06 cuDeviceGet
0.00 9.00e-07 1 9.00e-07 9.00e-07 9.00e-07 cuDeviceGetUuid
Incrementamos el número de subintervalos.
Rcf8.cu
%%file Rcf8.cu
#include<stdio.h>
#include <thrust/reduce.h>
#include <thrust/execution_policy.h>
__global__ void Rcf(double *data, double a, double h_hat, long int n, double *sum_res ) {
/*
Compute numerical approximation using rectangle or mid-point method in
an interval.
Nodes are generated via formula: x_i = a+(i+1/2)h_hat for i=0,1,...,n-1 and h_hat=(b-a)/n
Args:
data (double): array that will hold values evaluated in function
a (int): left point of interval
h_hat (double): width of subinterval
n (int): number of subintervals
sum_res (double): pointer to result
Returns:
sum_res (double): pointer to result
*/
double x=0.0;
int idx;
int num_threads=gridDim.x * blockDim.x;
int stride = num_threads;
int i;
idx = blockIdx.x * blockDim.x + threadIdx.x;
for(i=idx; i<=n-1; i+=stride){
if(idx<=n-1){
x=a+(idx+1/2.0)*h_hat;
data[idx]=std::exp(-std::pow(x,2));
}
}
if(idx==0){
*sum_res = thrust::reduce(thrust::device, data , data + n, (double)0, thrust::plus<double>());
}
}
cudaError_t check_error(cudaError_t result) {
if (result != cudaSuccess) {
fprintf(stderr, "Error: %s\n", cudaGetErrorString(result));
}
return result;
}
int main(int argc, char *argv[]){
double sum_res=0.0;
double *d_data;
double *d_sum;
double a=0.0, b=1.0;
double h_hat;
int n_threads_per_block=1024;
long int n_blocks=0;
double obj=0.7468241328124271;
long int n=0;
double time_spent;
clock_t begin,end;
cudaDeviceProp properties;
cudaGetDeviceProperties(&properties, 0);
n_blocks = 100000 * properties.multiProcessorCount;
n = n_blocks*n_threads_per_block;
dim3 dimGrid(n_blocks,1,1);
dim3 dimBlock(n_threads_per_block,1,1);
check_error(cudaMalloc((void **)&d_data,sizeof(double)*n));
check_error(cudaMalloc((void**)&d_sum,sizeof(double)));
h_hat=(b-a)/n;
begin = clock();
Rcf<<<dimGrid,dimBlock>>>(d_data, a,h_hat,n,d_sum);
cudaDeviceSynchronize();
end = clock();
time_spent = (double)(end - begin) / CLOCKS_PER_SEC;
check_error(cudaMemcpy(&sum_res, d_sum, sizeof(double), cudaMemcpyDeviceToHost));
sum_res=h_hat*sum_res;
cudaFree(d_data);
cudaFree(d_sum);
printf("Número de subintervalos: %ld\n", n);
printf("Integral de %f a %f = %1.15e\n", a,b,sum_res);
printf("Error relativo de la solución: %1.15e\n", fabs(sum_res-obj)/fabs(obj));
printf("Tiempo de cálculo en la gpu %.5f\n", time_spent);
return 0;
}
Writing Rcf8.cu
%%bash
source ~/.profile
nvcc -gencode arch=compute_37,code=sm_37 --compiler-options -Wall Rcf8.cu -o Rcf8.out
nvcc warning : The 'compute_35', 'compute_37', 'compute_50', 'sm_35', 'sm_37' and 'sm_50' architectures are deprecated, and may be removed in a future release (Use -Wno-deprecated-gpu-targets to suppress warning).
%%bash
./Rcf8.out
Número de subintervalos: 1331200000
Integral de 0.000000 a 1.000000 = 7.468241328124491e-01
Error relativo de la solución: 2.943452805253579e-14
Tiempo de cálculo en la gpu 130.57445
Observación
En la programación con CUDA-C es importante checar posibles errores de alojamiento de memoria. Una forma es con los tipos cudaError_t y cudaSuccess . Ver why-do-i-have-insufficient-buffer-space-when-i-put-allocation-code-in-a-functi.
Incrementamos el número de subintervalos.
%%file Rcf9.cu
#include<stdio.h>
#include <thrust/reduce.h>
#include <thrust/execution_policy.h>
__global__ void Rcf(double *data, double a, double h_hat, long int n, double *sum_res ) {
/*
Compute numerical approximation using rectangle or mid-point method in
an interval.
Nodes are generated via formula: x_i = a+(i+1/2)h_hat for i=0,1,...,n-1 and h_hat=(b-a)/n
Args:
data (double): array that will hold values evaluated in function
a (int): left point of interval
h_hat (double): width of subinterval
n (int): number of subintervals
sum_res (double): pointer to result
Returns:
sum_res (double): pointer to result
*/
double x=0.0;
int idx;
int num_threads=gridDim.x * blockDim.x;
int stride = num_threads;
int i;
idx = blockIdx.x * blockDim.x + threadIdx.x;
for(i=idx; i<=n-1; i+=stride){
if(idx<=n-1){
x=a+(idx+1/2.0)*h_hat;
data[idx]=std::exp(-std::pow(x,2));
}
}
if(idx==0){
*sum_res = thrust::reduce(thrust::device, data , data + n, (double)0, thrust::plus<double>());
}
}
cudaError_t check_error(cudaError_t result) {
if (result != cudaSuccess) {
fprintf(stderr, "Error: %s\n", cudaGetErrorString(result));
}
return result;
}
int main(int argc, char *argv[]){
double sum_res=0.0;
double *d_data;
double *d_sum;
double a=0.0, b=1.0;
double h_hat;
int n_threads_per_block=1024;
long int n_blocks=0;
double obj=0.7468241328124271;
long int n=0;
double time_spent;
clock_t begin,end;
cudaDeviceProp properties;
cudaGetDeviceProperties(&properties, 0);
n_blocks = 150000 * properties.multiProcessorCount;
n = n_blocks*n_threads_per_block;
dim3 dimGrid(n_blocks,1,1);
dim3 dimBlock(n_threads_per_block,1,1);
check_error(cudaMalloc((void **)&d_data,sizeof(double)*n));
check_error(cudaMalloc((void**)&d_sum,sizeof(double)));
h_hat=(b-a)/n;
begin = clock();
Rcf<<<dimGrid,dimBlock>>>(d_data, a,h_hat,n,d_sum);
cudaDeviceSynchronize();
end = clock();
time_spent = (double)(end - begin) / CLOCKS_PER_SEC;
check_error(cudaMemcpy(&sum_res, d_sum, sizeof(double), cudaMemcpyDeviceToHost));
sum_res=h_hat*sum_res;
cudaFree(d_data);
cudaFree(d_sum);
printf("Número de subintervalos: %ld\n", n);
printf("Integral de %f a %f = %1.15e\n", a,b,sum_res);
printf("Error relativo de la solución: %1.15e\n", fabs(sum_res-obj)/fabs(obj));
printf("Tiempo de cálculo en la gpu %.5f\n", time_spent);
return 0;
}
Writing Rcf9.cu
%%bash
source ~/.profile
nvcc -gencode arch=compute_37,code=sm_37 --compiler-options -Wall Rcf9.cu -o Rcf9.out
nvcc warning : The 'compute_35', 'compute_37', 'compute_50', 'sm_35', 'sm_37' and 'sm_50' architectures are deprecated, and may be removed in a future release (Use -Wno-deprecated-gpu-targets to suppress warning).
%%bash
./Rcf9.out
Número de subintervalos: 1996800000
Integral de 0.000000 a 1.000000 = 0.000000000000000e+00
Error relativo de la solución: 1.000000000000000e+00
Tiempo de cálculo en la gpu 0.06584
Error: out of memory
Error: an illegal memory access was encountered
Ejercicio
Implementar la regla de Simpson compuesta con CUDA-C en una máquina de AWS con las mismas características que la que se presenta en esta nota y medir tiempo de ejecución.
CuPy#
NumPy-like API accelerated with CUDA. CuPy is an implementation of NumPy-compatible multi-dimensional array on CUDA. CuPy consists of the core multi-dimensional array class, cupy.ndarray, and many functions on it. It supports a subset of numpy.ndarray interface.
Un subconjunto de funciones del paquete NumPy de Python están implementadas en CuPy vía la clase cupy.ndarray la cual es compatible en la GPU con la clase numpy.ndarray que utiliza la CPU.
Arrays#
import cupy as cp
import numpy as np
x_gpu = cp.array([1, 2, 3])
Y el array \(1\)-dimensional anterior está alojado en la GPU.
Podemos obtener información del array anterior utilizando algunos métodos y atributos.
print('x_gpu.ndim:',x_gpu.ndim)
print('x_gpu.shape:',x_gpu.shape)
print('x_gpu.size:',x_gpu.size)
print('x_gpu.dtype:',x_gpu.dtype)
x_gpu.ndim: 1
x_gpu.shape: (3,)
x_gpu.size: 3
x_gpu.dtype: int64
Accedemos con corchetes a sus componentes:
print('primer elemento', x_gpu[0])
print('último elemento', x_gpu[-1])
print('segundo elemento', x_gpu[1])
print('penúltimo elemento', x_gpu[-2])
print('del primero al 2º elemento incluyendo este último', x_gpu[:2])
print('del 2º al último elemento sin incluir el 2º', x_gpu[2:])
primer elemento 1
último elemento 3
segundo elemento 2
penúltimo elemento 2
del primero al 2º elemento incluyendo este último [1 2]
del 2º al último elemento sin incluir el 2º [3]
A diferencia de NumPy que nos devuelve un error al ejecutar.
x_cpu = np.array([1,2,3])
print(x_cpu[[3]])
---------------------------------------------------------------------------
IndexError Traceback (most recent call last)
<ipython-input-7-78c8861b3dfe> in <module>
----> 1 print(x_cpu[[3]])
IndexError: index 3 is out of bounds for axis 0 with size 3
Con CuPy se reciclan los índices.
print(x_gpu[[3]])
[1]
Otra forma de generar arrays en NumPy es con la función arange o random para un array pseudo aleatorio.
print(cp.arange(3))
[0 1 2]
cp.random.seed(2000)
print(cp.random.rand(4))
[0.59640368 0.42459851 0.15535147 0.95573683]
Array’s dos dimensionales.
A = cp.array([[1,2,3],[4,5,6]])
print(A)
[[1 2 3]
[4 5 6]]
print('A.ndim:', A.ndim)
print('A.shape:', A.shape)
print('A.size:', A.size)
print('A.dtype', A.dtype)
A.ndim: 2
A.shape: (2, 3)
A.size: 6
A.dtype int64
Accedemos con corchetes a sus componentes
print('elemento en la posición (0,0):', A[0][0])
print('elemento en la posición (1,2):', A[1][2])
#also with:
print('elemento en la posición (0,0):', A[0,0])
print('elemento en la posición (1,2):', A[1,2])
elemento en la posición (0,0): 1
elemento en la posición (1,2): 6
elemento en la posición (0,0): 1
elemento en la posición (1,2): 6
print('primer columna:', A[:,0])
print('tercer columna:', A[:,2])
print('segundo renglón:', A[1,:])
primer columna: [1 4]
tercer columna: [3 6]
segundo renglón: [4 5 6]
Funciones arange o random.
print(cp.arange(6).reshape(2,3))
print(cp.arange(0,1.2,.2).reshape(3,2))
[[0 1 2]
[3 4 5]]
[[0. 0.2]
[0.4 0.6]
[0.8 1. ]]
cp.random.seed(2000)
print(cp.random.rand(2,4))
[[0.59640368 0.42459851 0.15535147 0.95573683]
[0.97054217 0.68966838 0.72790884 0.12783432]]
Operaciones en el álgebra lineal con CuPy#
Producto escalar-vector, suma y punto entre vectores#
v1 = cp.array([6,-3,4])
v2 = cp.array([4,5,0])
scalar = -1/2
print(scalar*v1)
[-3. 1.5 -2. ]
print(v1.dot(v2))
9
print(v1+v2)
[10 2 4]
Producto matriz vector point-wise#
A = cp.array([[2,5,0],[3,6,6],[-6,4,-1],[5,4,9]])
print(A)
[[ 2 5 0]
[ 3 6 6]
[-6 4 -1]
[ 5 4 9]]
v = cp.array([-2,1,4])
print(v)
[-2 1 4]
print(A*v)
[[ -4 5 0]
[ -6 6 24]
[ 12 4 -4]
[-10 4 36]]
Producto matriz-vector#
A = cp.array([[2,5,0],[3,6,6],[-6,4,-1],[5,4,9]])
print(A)
[[ 2 5 0]
[ 3 6 6]
[-6 4 -1]
[ 5 4 9]]
Observación
Obsérvese que las clases de los objetos deben ser del mismo tipo.
v = np.array([-2,1,4])
print(v)
[-2 1 4]
print(A.dot(v))
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-28-1b54d307edad> in <module>
----> 1 print(A.dot(v))
TypeError: Argument 'b' has incorrect type (expected cupy._core.core.ndarray, got numpy.ndarray)
v = cp.array([-2,1,4])
print(v)
[-2 1 4]
print(A.dot(v))
[ 1 24 12 30]
print(A@v)
[ 1 24 12 30]
v = cp.array([7,0,-3,2])
print(v)
[ 7 0 -3 2]
print(v@A)
[42 31 21]
Suma y producto matriz-matriz pointwise#
A = cp.array([[2,5,0],[3,6,6],[-6,4,-1],[5,4,9]])
print(A)
[[ 2 5 0]
[ 3 6 6]
[-6 4 -1]
[ 5 4 9]]
B = cp.array([[2,-2,3],[1,-1,5],[0,-2,1],[0,0,-3]])
print(B)
[[ 2 -2 3]
[ 1 -1 5]
[ 0 -2 1]
[ 0 0 -3]]
print(A+B)
[[ 4 3 3]
[ 4 5 11]
[-6 2 0]
[ 5 4 6]]
print(A*B)
[[ 4 -10 0]
[ 3 -6 30]
[ 0 -8 -1]
[ 0 0 -27]]
Producto matriz-matriz#
A = cp.array([[2,5,0],[3,6,6],[-6,4,-1],[5,4,9]])
print(A)
[[ 2 5 0]
[ 3 6 6]
[-6 4 -1]
[ 5 4 9]]
B = cp.array([[2,-2,3],[1,-1,5],[0,-2,1]])
print(B)
[[ 2 -2 3]
[ 1 -1 5]
[ 0 -2 1]]
print(A@B)
[[ 9 -9 31]
[ 12 -24 45]
[ -8 10 1]
[ 14 -32 44]]
Algunas operaciones básicas del álgebra lineal#
Norma de vectores#
v = cp.array([1,2,3])
print(v)
[1 2 3]
print(cp.linalg.norm(v))
3.7416573867739413
Norma de matrices#
A = cp.array([[2,5,0],[3,6,6],[-6,4,-1]])
print(A)
[[ 2 5 0]
[ 3 6 6]
[-6 4 -1]]
print(cp.linalg.norm(A))
12.767145334803704
Resolver sistema de ecuaciones lineales#
A = cp.array([[8, -6, 2], [-4, 11, -7], [4, -7, 6]])
b = cp.array([28,-40,33])
print('A:')
print(A)
print('b:')
print(b)
A:
[[ 8 -6 2]
[-4 11 -7]
[ 4 -7 6]]
b:
[ 28 -40 33]
x = cp.linalg.solve(A,b)
print('x:')
print(x)
x:
[ 2. -1. 3.]
print('Verificando resultado Ax = b')
print('b:')
print(b)
print('Ax:')
print(A@x)
Verificando resultado Ax = b
b:
[ 28 -40 33]
Ax:
[ 28. -40. 33.]
Transferencia de datos del host al device o viceversa#
x_cpu = np.array([1, 2, 3])
x_gpu = cp.asarray(x_cpu) # move the data to the current device.
print(x_gpu)
[1 2 3]
print(type(x_gpu))
<class 'cupy._core.core.ndarray'>
x_gpu = cp.array([1, 2, 3]) # create an array in the current device
x_cpu = cp.asnumpy(x_gpu) # move the array to the host.
Y estas funciones pueden utilizarse para realizar operaciones dependiendo del tipo de array.
y_cpu = np.array([5,6,7])
print(x_gpu + y_cpu)
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-55-e0e7324dadac> in <module>
----> 1 print(x_gpu + y_cpu)
cupy/_core/core.pyx in cupy._core.core.ndarray.__add__()
cupy/_core/core.pyx in cupy._core.core.ndarray.__array_ufunc__()
cupy/_core/_kernel.pyx in cupy._core._kernel.ufunc.__call__()
cupy/_core/_kernel.pyx in cupy._core._kernel._preprocess_args()
TypeError: Unsupported type <class 'numpy.ndarray'>
print(x_gpu + cp.asarray(y_cpu))
[ 6 8 10]
print(cp.asnumpy(x_gpu) + y_cpu )
[ 6 8 10]
Función ejecutada dependiendo de que sean array’s de NumPy o CuPy#
Es posible ejecutar una función dependiendo de sus argumentos con el módulo get_array_module.
def fun(x):
xp = cp.get_array_module(x)
return xp.exp(-x) + xp.cos(xp.sin(-abs(x)))
print(fun(x_gpu))
[1.03424619 0.74963557 1.03984615]
print(fun(x_cpu))
[1.03424619 0.74963557 1.03984615]
Ejemplo regla compuesta del rectángulo#
f_cp = lambda x: cp.exp(-x**2)
def Rcf_cupy(f,a,b,n):
"""
Compute numerical approximation using rectangle or mid-point
method in an interval.
Nodes are generated via formula: x_i = a+(i+1/2)h_hat for
i=0,1,...,n-1 and h_hat=(b-a)/n
Args:
f (float): function expression of integrand.
a (float): left point of interval.
b (float): right point of interval.
n (int): number of subintervals.
Returns:
sum_res (float): numerical approximation to integral
of f in the interval a,b
"""
h_hat = (b-a)/n
aux_vec = cp.linspace(a, b, n+1)
nodes = (aux_vec[:-1]+aux_vec[1:])/2
return h_hat*cp.sum(f(nodes))
import math
import time
from pytest import approx
from scipy.integrate import quad
n = 10**7
a = 0
b = 1
f=lambda x: math.exp(-x**2) #using math library
obj, err = quad(f, a, b)
res_cupy = Rcf_cupy(f_cp, a, b,n)
print(res_cupy.get() == approx(obj))
True
from cupyx.time import repeat
print(repeat(Rcf_cupy, (f_cp,a,b,n), n_repeat=10))
/home/ubuntu/.local/lib/python3.8/site-packages/cupyx/time.py:115: FutureWarning: cupyx.time.repeat is experimental. The interface can change in the future.
_util.experimental('cupyx.time.repeat')
Rcf_cupy : CPU: 379.885 us +/-64.506 (min: 328.881 / max: 543.411) us GPU-0:21021.779 us +/-768.554 (min:19397.568 / max:22042.303) us
Ver performance.
Observación
Obsérvese que se utiliza mayor cantidad de memoria por CuPy que utilizando la implementación con CUDA-C Rcf8.cu.
n = 10**9
print(repeat(Rcf_cupy, (f_cp,a,b,n), n_repeat=10))
/home/ubuntu/.local/lib/python3.8/site-packages/cupyx/time.py:115: FutureWarning: cupyx.time.repeat is experimental. The interface can change in the future.
_util.experimental('cupyx.time.repeat')
---------------------------------------------------------------------------
NVRTCError Traceback (most recent call last)
~/.local/lib/python3.8/site-packages/cupy/cuda/compiler.py in compile(self, options, log_stream)
622 nvrtc.addAddNameExpression(self.ptr, ker)
--> 623 nvrtc.compileProgram(self.ptr, options)
624 mapping = None
cupy_backends/cuda/libs/nvrtc.pyx in cupy_backends.cuda.libs.nvrtc.compileProgram()
cupy_backends/cuda/libs/nvrtc.pyx in cupy_backends.cuda.libs.nvrtc.compileProgram()
cupy_backends/cuda/libs/nvrtc.pyx in cupy_backends.cuda.libs.nvrtc.check_status()
NVRTCError: NVRTC_ERROR_COMPILATION (6)
During handling of the above exception, another exception occurred:
CompileException Traceback (most recent call last)
<ipython-input-6-33ae1eff6e88> in <module>
----> 1 print(repeat(Rcf_cupy, (f_cp,a,b,n), n_repeat=10))
~/.local/lib/python3.8/site-packages/cupyx/time.py in repeat(func, args, kwargs, n_repeat, name, n_warmup, max_duration, devices)
137 raise ValueError('`devices` should be of tuple type')
138
--> 139 return _repeat(
140 func, args, kwargs, n_repeat, name, n_warmup, max_duration, devices)
141
~/.local/lib/python3.8/site-packages/cupyx/time.py in _repeat(func, args, kwargs, n_repeat, name, n_warmup, max_duration, devices)
156
157 for i in range(n_warmup):
--> 158 func(*args, **kwargs)
159
160 for event, device in zip(events_1, devices):
<ipython-input-3-417a01c1f5d1> in Rcf_cupy(f, a, b, n)
21 """
22 h_hat = (b-a)/n
---> 23 aux_vec = cp.linspace(a, b, n+1)
24 nodes = (aux_vec[:-1]+aux_vec[1:])/2
25 return h_hat*cp.sum(f(nodes))
~/.local/lib/python3.8/site-packages/cupy/_creation/ranges.py in linspace(start, stop, num, endpoint, retstep, dtype, axis)
156 scalar_stop = cupy.isscalar(stop)
157 if scalar_start and scalar_stop:
--> 158 return _linspace_scalar(start, stop, num, endpoint, retstep, dtype)
159
160 if not scalar_start:
~/.local/lib/python3.8/site-packages/cupy/_creation/ranges.py in _linspace_scalar(start, stop, num, endpoint, retstep, dtype)
104 if endpoint:
105 # Here num == div + 1 > 1 is ensured.
--> 106 ret[-1] = stop
107
108 if cupy.issubdtype(dtype, cupy.integer):
cupy/_core/core.pyx in cupy._core.core.ndarray.__setitem__()
cupy/_core/_routines_indexing.pyx in cupy._core._routines_indexing._ndarray_setitem()
cupy/_core/_routines_indexing.pyx in cupy._core._routines_indexing._scatter_op()
cupy/_core/core.pyx in cupy._core.core.ndarray.fill()
cupy/_core/_kernel.pyx in cupy._core._kernel.ElementwiseKernel.__call__()
cupy/_core/_kernel.pyx in cupy._core._kernel.ElementwiseKernel._get_elementwise_kernel()
cupy/_util.pyx in cupy._util.memoize.decorator.ret()
cupy/_core/_kernel.pyx in cupy._core._kernel._get_elementwise_kernel()
cupy/_core/_kernel.pyx in cupy._core._kernel._get_simple_elementwise_kernel()
cupy/_core/core.pyx in cupy._core.core.compile_with_cache()
~/.local/lib/python3.8/site-packages/cupy/cuda/compiler.py in compile_with_cache(source, options, arch, cache_dir, extra_source, backend, enable_cooperative_groups, name_expressions, log_stream, jitify)
430 name_expressions, log_stream, cache_in_memory)
431 else:
--> 432 return _compile_with_cache_cuda(
433 source, options, arch, cache_dir, extra_source, backend,
434 enable_cooperative_groups, name_expressions, log_stream,
~/.local/lib/python3.8/site-packages/cupy/cuda/compiler.py in _compile_with_cache_cuda(source, options, arch, cache_dir, extra_source, backend, enable_cooperative_groups, name_expressions, log_stream, cache_in_memory, jitify)
507 if backend == 'nvrtc':
508 cu_name = '' if cache_in_memory else name + '.cu'
--> 509 ptx, mapping = compile_using_nvrtc(
510 source, options, arch, cu_name, name_expressions,
511 log_stream, cache_in_memory, jitify)
~/.local/lib/python3.8/site-packages/cupy/cuda/compiler.py in compile_using_nvrtc(source, options, arch, filename, name_expressions, log_stream, cache_in_memory, jitify)
269 cu_file.write(source)
270
--> 271 return _compile(source, options, cu_path,
272 name_expressions, log_stream, jitify)
273 else:
~/.local/lib/python3.8/site-packages/cupy/cuda/compiler.py in _compile(source, options, cu_path, name_expressions, log_stream, jitify)
253 name_expressions=name_expressions)
254 try:
--> 255 ptx, mapping = prog.compile(options, log_stream)
256 except CompileException as e:
257 dump = _get_bool_env_variable(
~/.local/lib/python3.8/site-packages/cupy/cuda/compiler.py in compile(self, options, log_stream)
633 except nvrtc.NVRTCError:
634 log = nvrtc.getProgramLog(self.ptr)
--> 635 raise CompileException(log, self.src, self.name, options,
636 'nvrtc' if not runtime.is_hip else 'hiprtc')
637
CompileException: /home/ubuntu/.local/lib/python3.8/site-packages/cupy/_core/include/cupy/carray.cuh(220): error: the size of an array must be greater than zero
detected during instantiation of class "CArray<T, _ndim, _c_contiguous, _use_32bit_indexing> [with T=double, _ndim=0, _c_contiguous=true, _use_32bit_indexing=false]"
/tmp/tmpy38z_fir/80b50dce313ef4bb36a0d424596a2ca1_2.cubin.cu(8): here
/home/ubuntu/.local/lib/python3.8/site-packages/cupy/_core/include/cupy/carray.cuh(221): error: the size of an array must be greater than zero
detected during instantiation of class "CArray<T, _ndim, _c_contiguous, _use_32bit_indexing> [with T=double, _ndim=0, _c_contiguous=true, _use_32bit_indexing=false]"
/tmp/tmpy38z_fir/80b50dce313ef4bb36a0d424596a2ca1_2.cubin.cu(8): here
/home/ubuntu/.local/lib/python3.8/site-packages/cupy/_core/include/cupy/carray.cuh(322): error: the size of an array must be greater than zero
detected during instantiation of class "CArray<T, _ndim, _c_contiguous, _use_32bit_indexing> [with T=double, _ndim=0, _c_contiguous=true, _use_32bit_indexing=false]"
/tmp/tmpy38z_fir/80b50dce313ef4bb36a0d424596a2ca1_2.cubin.cu(8): here
/home/ubuntu/.local/lib/python3.8/site-packages/cupy/_core/include/cupy/carray.cuh(327): error: the size of an array must be greater than zero
detected during instantiation of class "CArray<T, _ndim, _c_contiguous, _use_32bit_indexing> [with T=double, _ndim=0, _c_contiguous=true, _use_32bit_indexing=false]"
/tmp/tmpy38z_fir/80b50dce313ef4bb36a0d424596a2ca1_2.cubin.cu(8): here
/tmp/tmpy38z_fir/80b50dce313ef4bb36a0d424596a2ca1_2.cubin.cu(12): error: no operator "[]" matches these operands
operand types are: CArray<double, 0, true, false> [ const ptrdiff_t * ]
5 errors detected in the compilation of "/tmp/tmpy38z_fir/80b50dce313ef4bb36a0d424596a2ca1_2.cubin.cu".
Ejercicio
Implementar la regla de Simpson compuesta con CuPy en una máquina de AWS con las mismas características que la que se presenta en esta nota y medir tiempo de ejecución.
Referencias de interés#
Para más sobre Unified Memory revisar:
Es importante el manejo de errores por ejemplo en el alojamiento de memoria en la GPU. En este caso es útil revisar:
En las siguientes preguntas encontramos a personas desarrolladoras de CUDA que las resuelven y resultan muy útiles para continuar con el aprendizaje de CUDA C. Por ejemplo:
Otros sistemas de software para el Heterogeneous computing son:
OpenCl. Ver NVIDIA OpenCL SDK Code Samples para ejemplos con NVIDIA GPU’s.
Rth-org/Rth y más reciente matloff/Rth. Ver también rdrr.io matloff/Rth.
Es posible escribir kernels con CuPy. Ver por ejemplo: User-Defined Kernels.
Otro paquete para uso de Python+GPU para cómputo matricial es:
PyCUDA y ver PyCUDA en el repo de la clase para más información.
Un paquete para uso de pandas+GPU:
Ver optional-libraries para librerías que pueden ser utilizadas con CuPy.
Un paquete de R para uso de GPU: gputools: cran.
Ejercicios
1.Resuelve los ejercicios y preguntas de la nota.
Preguntas de comprehensión:
1)¿Qué factores han determinado un mejor performance de una GPU vs una CPU? (contrasta los diseños de una CPU vs una GPU).
2)¿Dentro de qué modelo de arquitectura de máquinas se ubica a la GPU dentro de la taxonomía de Flynn? (tip: tal modelo se le puede comparar con el modelo Single Program Multiple Data (SPMD))
3)¿Qué significan las siglas CUDA y detalla qué es CUDA?.
4)¿Qué es y en qué consiste CUDA C?
5)¿Qué es un kernel?
6)¿Qué pieza de CUDA se encarga de asignar los bloques de cuda-threads a las SM’s?
7)¿Qué características (recursos compartidos, dimensiones, forma de agendar la ejecución en threads) tienen los bloques que se asignan a una SM al lanzarse y ejecutarse un kernel?
8)¿Qué es un warp?
9)Menciona los tipos de memorias que existen en las GPU’s.
10)Supón que tienes una tarjeta GT200 cuyas características son:
Máximo número de threads que soporta una SM en un mismo instante en el tiempo: 1024
Máximo número de threads en un bloque: 512
Máximo número de bloques por SM: 8
Número de SM’s que tiene esta GPU: 30
Responde:
a)¿Cuál es la máxima cantidad de threads que puede soportar esta GPU en un mismo instante en el tiempo?
b)¿Cuál es la máxima cantidad de warps por SM que puede soportar esta GPU en un mismo instante en el tiempo?
c)¿Cuáles configuraciones de bloques y threads siguientes aprovechan la máxima cantidad de warps en una SM de esta GPU para un mismo instante en el tiempo?
1.Una configuración del tipo: bloques de 64 threads y 16 bloques.
2.Una configuración del tipo: bloques de 1024 threads y 1 bloque.
3.Una configuración del tipo: bloques de 256 threads y 4 bloques.
4.Una configuración del tipo: bloques de 512 threads y 8 bloques.
*Debes considerar las restricciones/características de la GPU dadas para responder pues algunas configuraciones infringen las mismas. No estamos considerando registers o shared memory.
Referencias:
N. Matloff, Parallel Computing for Data Science. With Examples in R, C++ and CUDA, 2014.
D. B. Kirk, W. W. Hwu, Programming Massively Parallel Processors: A Hands-on Approach, Morgan Kaufmann, 2010.
NVIDIA,CUDA Programming Guide, NVIDIA Corporation, 2007.
B. W. Kernighan, D. M. Ritchie, The C Programming Language, Prentice Hall Software Series, 1988