5.1 Introducción a optimización de código
Contents
5.1 Introducción a optimización de código#
Notas para contenedor de docker:
Comando de docker para ejecución de la nota de forma local:
nota: cambiar <ruta a mi directorio> por la ruta de directorio que se desea mapear a /datos dentro del contenedor de docker y <versión imagen de docker> por la versión más actualizada que se presenta en la documentación.
docker run --rm -v <ruta a mi directorio>:/datos --name jupyterlab_optimizacion_2 -p 8888:8888 -d palmoreck/jupyterlab_optimizacion_2:<versión imagen de docker>
password para jupyterlab: qwerty
Detener el contenedor de docker:
docker stop jupyterlab_optimizacion_2
Documentación de la imagen de docker palmoreck/jupyterlab_optimizacion_2:<versión imagen de docker> en liga.
Nota generada a partir de la liga
Al final de esta nota la comunidad lectora:
Conocerá razones del por qué algunas implementaciones de algoritmos son ineficientes a diferentes niveles. Uno es al nivel de lenguajes de programación utilizados. Otro es al nivel de componentes de un sistema computacional.
Conocerá herramientas para analizar y escribir programas para un alto rendimiento.
Conocerá rediseños que se han hecho a las unidades computacionales de un sistema computacional para resolver bottlenecks.
Conocerá la jerarquía de almacenamiento en el sistema de memoria de un sistema computacional.
Conocerá lo que significa vectorizar una operación y su relación con los niveles de BLAS.
Conocerá la diferencia entre programas secuenciales y en paralelo.
Aprenderá una metodología y enfoques utilizados para escribir programas con cómputo en paralelo.
La implementación de los métodos o algoritmos en el contexto de grandes cantidades de datos o big data es crítica al ir a la práctica pues de esto depende que nuestra(s) máquina(s) tarde meses, semanas, días u horas para resolver problemas que se presentan en este contexto. Así, la optimización de código o de software nos ayuda a la eficiencia.
Temas a considerar para escribir un programa de máquina de alto rendimiento#
Para tener un alto performance en un programa de máquina, deben considerarse las siguientes preguntas:
¿Qué tanto aprovecha mi programa aspectos como data reuse y data locality?
La respuesta nos lleva a pensar en el número de instrucciones por ciclo y el número de ciclos que realiza el procesador. Entiéndase un ciclo por los pasos de leer una instrucción, determinar acciones a realizar por tal instrucción y ejecutar las acciones, ver liga.
¿Cómo es mi data layout en el almacenamiento? (forma en la que están almacenados o dispuestos los datos)
Dependiendo de la respuesta podemos elegir una arquitectura de computadoras u otra y así también un algoritmo u otro.
¿Cuánto data movement o data motion realiza mi programa? (flujo de datos entre los distintos niveles de jerarquía de almacenamiento o entre las máquinas en un clúster de máquinas, por ejemplo)
La respuesta implica analizar el tráfico de datos entre las jerarquías de almacenamiento (o máquinas si estamos en un clúster de máquinas) y potenciales bottlenecks.
Herramientas que tenemos a nuestra disposición para analizar y escribir programas de máquina para un alto rendimiento#
Vectorización que pueden realizar los procesadores.
Perfilamiento de código para lograr la eficiencia deseada.
Programación en lenguajes compilados en lugar de intérpretes (o combinando intérpretes con lenguajes compilados)
Conocimiento de los propósitos con los que fueron diseñados los procesadores para explotar su capacidad. Aquí decidimos si usamos código secuencial o código en paralelo.
…además necesitamos conocer las diferentes arquitecturas que pueden utilizarse para cómputo en paralelo.
¿Alguien ya resolvió mi bottleneck?
Experiencia en el lenguaje de programación seleccionado.
Vectorización, BLAS: Basic Linear Algebra Subprograms y el uso del caché eficientemente.#
Para comprender lo que la vectorización y finalmente las operaciones de la especificación BLAS en sus diferentes niveles tienen por objetivo resolver, revisemos de forma general el sistema de una computadora.
Un poco de historia y generalidades del sistema en una computadora#
Las componentes fundamentales de un sistema en una computadora pueden simplificarse en:
Unidades computacionales. En éstas unidades nos interesa la pregunta ¿cuántos cálculos pueden realizar por segundo?
Unidades de memoria. En éstas unidades nos interesa la pregunta ¿cuántos datos pueden alojar y qué tan rápido puede leerse desde y escribirse hacia las distintas jerarquías?
Conexiones entre las unidades anteriores. Nos interesa ¿qué tan rápido pueden moverse datos de un lugar a otro?
Con esta simplificación tenemos como ejemplo a la CPU como unidad de cómputo conectada tanto a la RAM y a un disco duro como dos unidades de memoria y un bus que provee las conexiones entre estas partes. Otro ejemplo es considerar que la CPU tiene diferentes unidades de memoria en ella: los cachés tipo L1, L2, L3 y L4 conectadas a la CPU a través de otro bus. También la GPU es ejemplo de una unidad de cómputo conectada a una unidades de memoria como RAM y cachés.
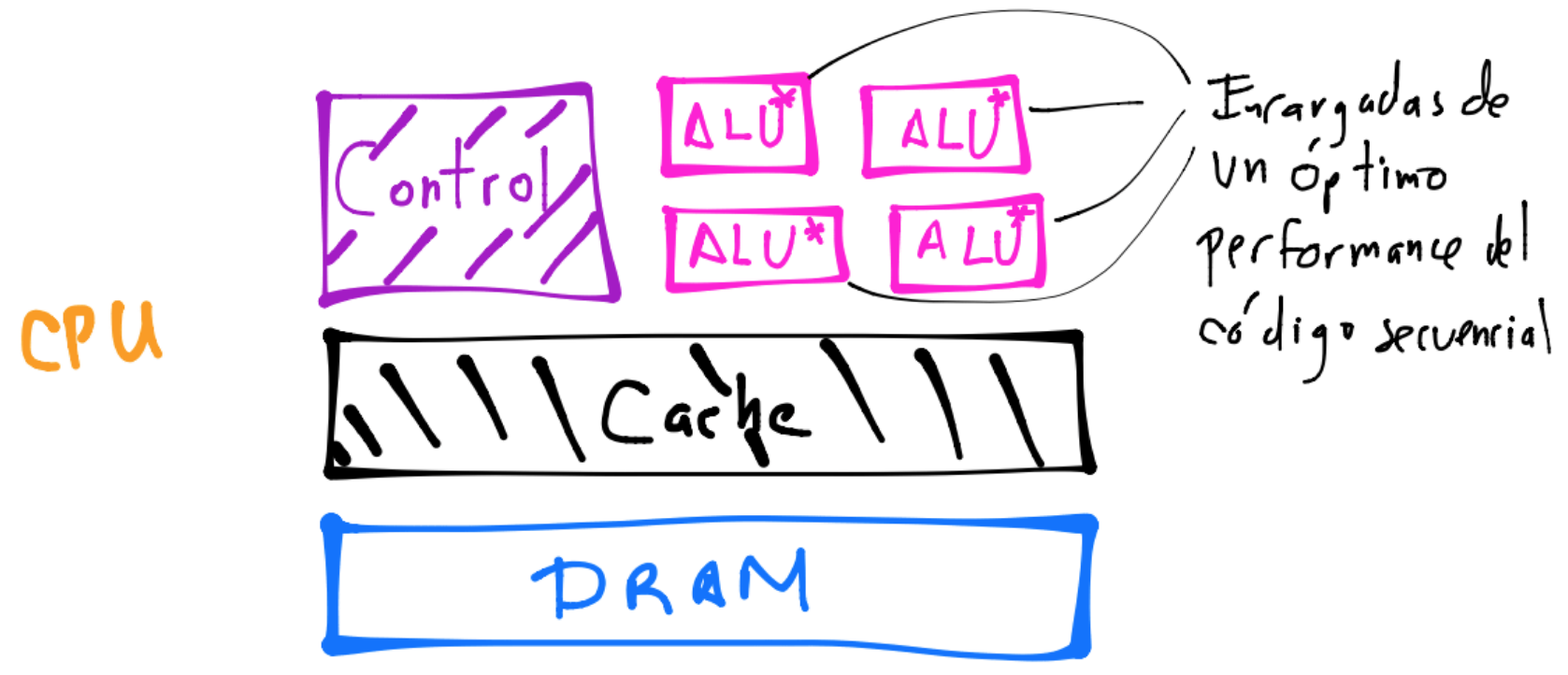
Un dibujo simplificado y basado en una arquitectura de computadoras con nombre Von Neumann que nos ayuda a visualizar lo anterior en la CPU es el siguiente:
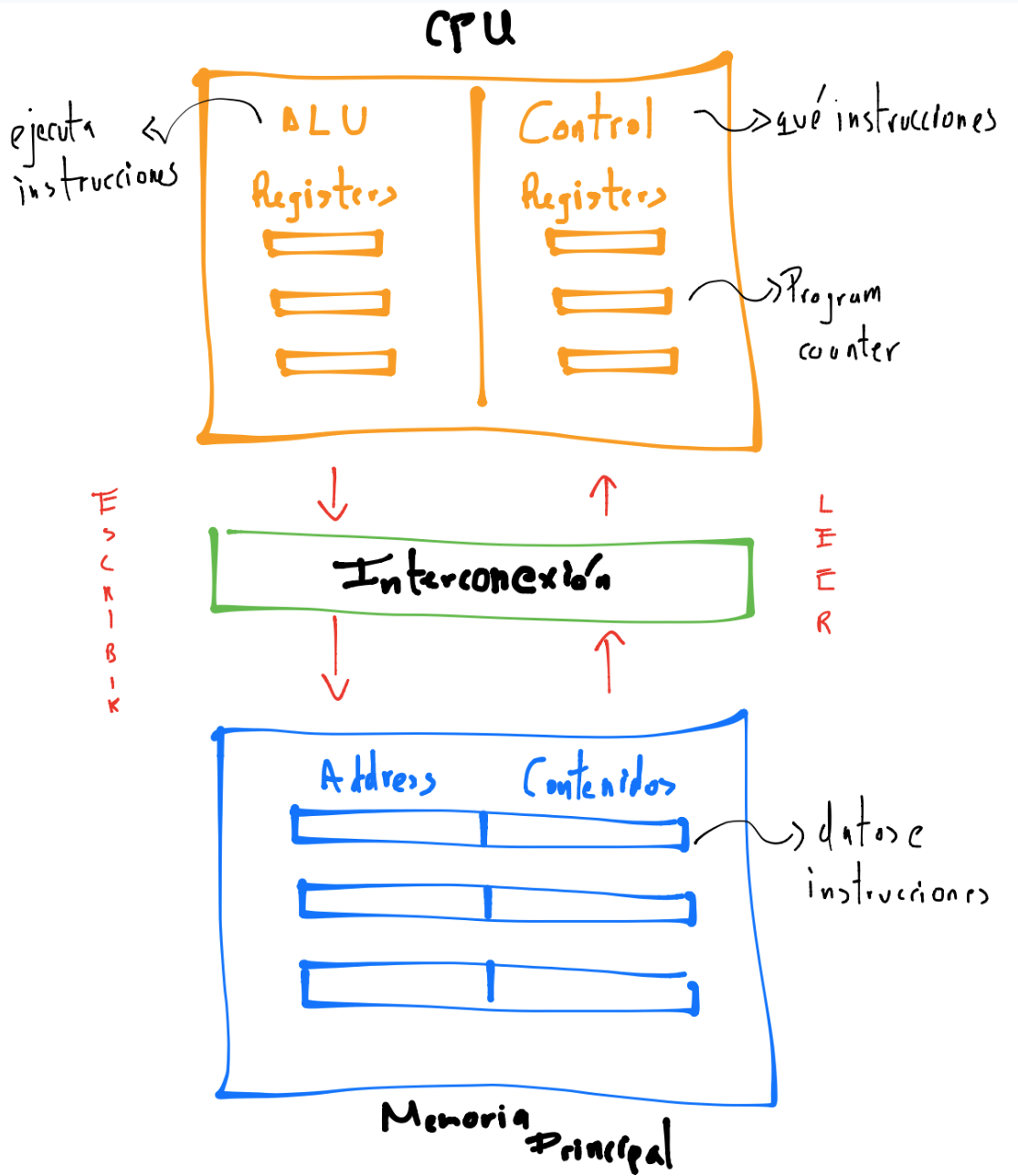
La memoria principal es una colección de ubicaciones que almacenan datos e instrucciones. Cada ubicación consiste de una dirección (address) que se utiliza para accesar a la ubicación y a sus contenidos.
La CPU está dividida en la unidad de control y la unidad aritmética y lógica. Aquí encontramos registers que son áreas o ubicaciones de almacenamiento (de datos, direcciones de memoria e información del estado de ejecución de un programa) de rápido acceso.
La interconexión o bus ayuda a la transferencia de datos e instrucciones entre la CPU y la memoria.
Comentarios
En el dibujo no se está presentando los dispositivos de input y output pero sí aparecen en la arquitectura de Von Neumann.
También no se presentan en el dibujo unidades de almacenamiento como los discos duros pero también aparecen en la arquitectura de Von Neumann. Los discos duros se consideran dentro de las unidades de memoria y la CPU se conecta a ellos mediante un bus.
Si los datos se transfieren de la memoria a la CPU se dice que los datos o instrucciones son leídas y si van de la CPU a la memoria decimos que son escritos a memoria.
La separación entre la memoria y la CPU genera lo que se conoce como Von Neumann bottleneck y tiene que ver con la lectura/escritura y almacenamiento de datos e instrucciones. La interconexión determina la tasa a la cual se accede a éstos.
Unidades de memoria#
Su objetivo es el almacenamiento de bits de información. Como ejemplos tenemos la memoria RAM, discos duros o el caché. La principal diferencia entre cada tipo de unidad de memoria es la velocidad a la que pueden leer/escribir datos. Ésta velocidad depende enormemente de la forma en que se leen/escriben los datos. Por ejemplo, la mayoría de las unidades de memoria tienen un mejor performance al leer un gran pedazo de información que al leer muchos pedacitos.
Comentario
Desde el punto de vista de los lenguajes de programación como Python o R, un resultado del manejo automático de memoria en estos lenguajes, es la fragmentación de datos o data fragmentation que surge al no tener bloques contiguos de memoria. Esto causa que en lugar de mover todo un bloque contiguo de datos en una sola transferencia a través del bus se requieran mover pedazos de memoria de forma individual lo que causa un mayor tiempo de lectura.
Las unidades de memoria tienen latencia que típicamente cambia dependiendo de una jerarquía de almacenamiento mostrada en el dibujo siguiente:
Comentario
Entiéndase por latencia el tiempo que le toma a la unidad o dispositivo para encontrar los datos que serán usados por el proceso.
Jerarquías de almacenamiento#

En el dibujo anterior se representan típicos dispositivos de almacenamiento en una máquina. La capacidad de almacenamiento disminuye conforme nos movemos hacia arriba en el dibujo: mientras que en disco podemos almacenar terabytes de información, en los registers sólo podemos almacenar bytes o kilobytes. Por el contrario, la velocidad de lectura/escritura disminuye conforme nos movemos hacia abajo: la lectura y escritura en disco es órdenes de veces más tardado que en los registers (que físicamente están en el procesador).
Caché#
Entre las técnicas que tenemos a nuestro alcance para que un algoritmo pueda aprovechar el data layout de la información se encuentra el caching: el eficiente uso del caché.
El caché es una memoria que está físicamente localizada más cercana a los registers del procesador para almacenar datos e instrucciones por lo que pueden ser accesados en menor tiempo que en otras unidades de memoria (como la RAM).
El caché se diseñó para resolver el Von Neumann bottleneck al existir un límite de tasa de transferencia entre la memoria RAM y el procesador (CPU o GPU). Si pudiéramos mover datos de una forma infinitamente rápida, no necesitaríamos al caché pues el procesador podría obtener los datos en cualquier instante, en esta situación no existiría tal bottleneck.
Aunque no tenemos en nuestros lenguajes de programación instrucciones del tipo “carga los datos en el caché” podemos usar los principios de localidad y temporalidad para mejorar la eficiencia de nuestros algoritmos. Los principios de localidad y temporalidad consisten en que el sistema de memoria tiende a usar los datos e instrucciones que físicamente son cercanos (localidad) y los datos e instrucciones que recientemente fueron usados (temporalidad).
¿Cómo funciona el acceso a la memoria en un sistema de computadora?#
Si el procesador requiere un conjunto de datos para ejecutar instrucciones, el sistema de memoria carga un bloque de datos (aunque pueden ser también instrucciones), conocido como cache blocks o cache lines para que el procesador opere en ellos.
Ejemplo#
En C al declarar un arreglo con la línea: float z[20]; se le solicita al sistema de memoria que se alojen \(20\) bloques contiguos de ubicaciones de memoria en la RAM, esto es: la ubicación para el almacenamiento de z[1] está inmediatamente después de la de z[0]. Si además tenemos un programa como el siguiente:
...
float z[20];
float sum=0;
int i=0;
for(i=0;i<20;i++)
sum+=z[i];
...
y nuestro cache line permite almacenar \(16\) floats, entonces el sistema de memoria leerá los datos z[0],...,z[15] de la RAM al caché y el procesador realizará la suma.
Posteriormente el procesador (que en este caso es la CPU) al accesar a los datos checa primero el caché, si las encontró se le conoce como cache hit, si no lo encontró sería un cache miss y el sistema de memoria tendría que leer nuevamente desde la RAM.
Ejemplo#
C almacena los arreglos de dos dimensiones en una forma row major, esto es, aunque en papel representamos tales arreglos como un bloque rectangular, en la implementación en este lenguaje se están almacenando como un arreglo de una dimensión: el renglón \(0\) es almacenado primero, a continuación el renglón \(1\) y así sucesivamente.
Observemos los siguientes códigos que realizan una multiplicación secuencial entre una matriz A y un vector x para obtener al vector y:
Algoritmo: multiplicación matriz vector secuencial
double A[MAX][MAX], x[MAX], y [MAX]; //MAX es un valor constante definido previamente
...
//bloque de código para inicializar A,x
//bloque de código para inicializar y con ceros
//Algoritmo 1:
for(i=0;i<MAX;i++)
for(j=0;j<MAX;j++)
y[i]+=A[i][j]*x[j];
//volver a asignar a y con ceros
//Algoritmo 2:
for(j=0;j<MAX;j++)
for(i=0;i<MAX;i++)
y[i]+=A[i][j]*x[j];
Supongamos que MAX=4 y los elementos de A están almacenados en memoria como sigue:
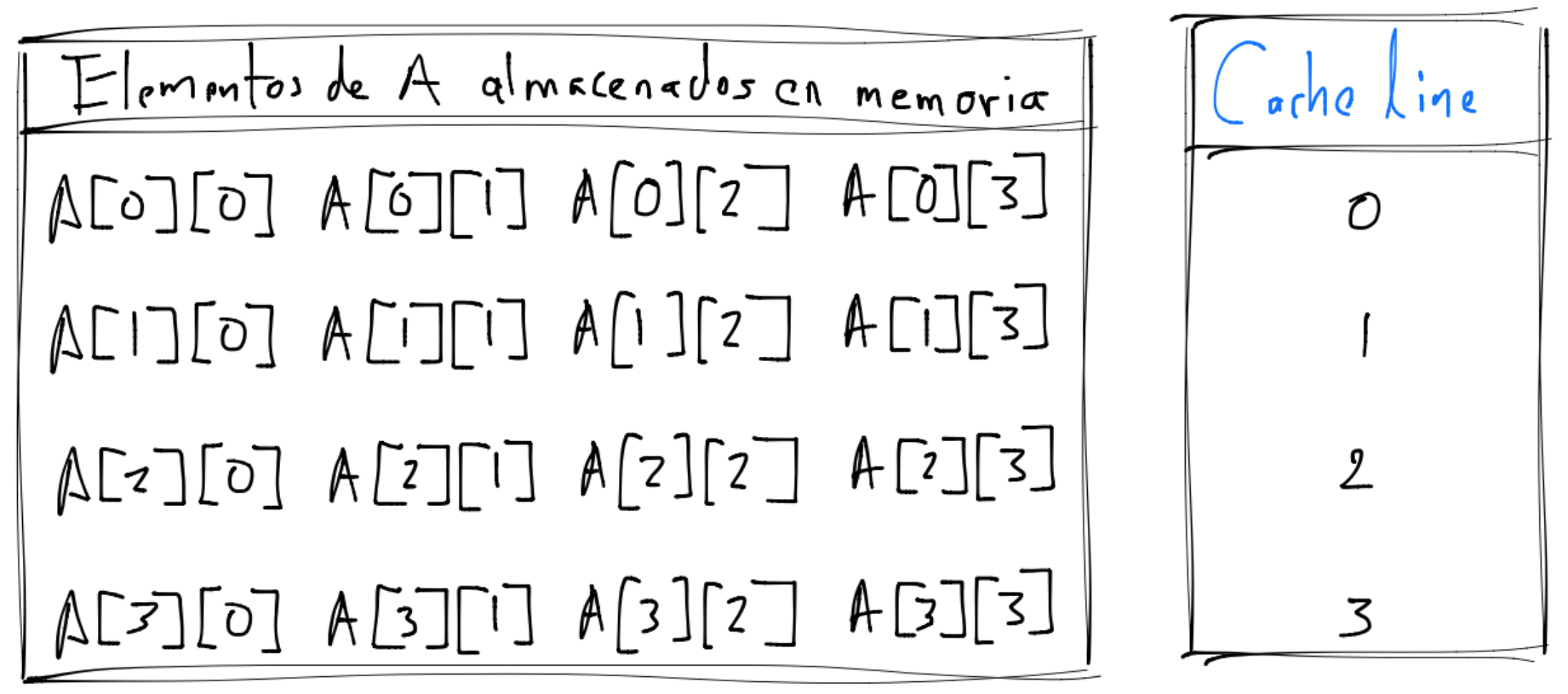
para simplificar el siguiente análisis supóngase que:
Ninguno de los elementos de
Aestán en el caché al iniciar el par de loops.Un cache line consiste de \(4\) elementos de
AyA[0][0]es el primer elemento del cache line.Cada cache line le corresponde una única úbicación en el caché al que será asignado.
El caché sólo puede almacenar \(4\) elementos de
Ao un cache line.
Entonces para el algoritmo \(1\) se tiene que la CPU y el sistema de memoria:
La CPU requiere
A[0][0]que no se encuentra en el caché por lo que tenemos un cache miss y el sistema de memoria lee de RAM el cache line:A[0][0] A[0][1] A[0][2] A[0][3]y al estar en caché la CPU puede operar conA[0][0].La CPU requiere
A[0][1]que sí se encuentra en el caché por lo que tenemos un cache hit y la CPU opera con éste dato. Posteriormente la CPU requiereA[0][2],A[0][3]yA[0][4]que se encuentran en caché y se tienen otros tres cache hits.La CPU requiere
A[1][0]que resulta en un cache miss y el sistema de memoria lee de RAM el cache line:A[1][0] A[1][1] A[1][2] A[1][3]y al estar en caché la CPU puede operar conA[1][0].
…
Finalmente para el algoritmo \(1\) tenemos \(4\) cache misses, uno por cada renglón.
Observación
¿Cuál es el número de cache misses para el algoritmo 2?.
Mayor número de cache misses incrementa el tiempo de ejecución de las instrucciones por el procesador pues no solamente el procesador espera mientras se transfieren los datos de la RAM hacia el caché sino también se interrumpe el flujo de la ejecución del pipeline (transferencia de datos y ejecución de instrucciones). Por ello es importante que los algoritmos trabajen con un buen data layout de la información en memoria y utilicen el data reuse y data locality.
Comentarios
El pipelining es un mecanismo utilizado por un procesador para la ejecución de instrucciones. Obstáculos al pipelining se encuentran los cache misses o el llamado mispredicted branching. El branch prediction, relacionado con el branching en un código (para el branching piénsese por ejemplo en una línea de código del tipo
if...then), es otro mecanismo del procesador para tratar de predecir la siguiente instrucción a ejecutar y cargar las porciones relevantes de memoria en el caché mientras se trabaja en la instrucción actual. El procesador al toparse con un branching en el código trata de hacer una suposición de qué dirección se tomará en el branching y precargar las instrucciones relevantes, si falla tiene branch-misses. Aunque también son importantes estos aspectos al considerar la implementación de un algoritmo, la herramienta más rápida que tenemos para resolver los bottlenecks en este contexto, son trabajar en la localidad y temporalidad de los datos.Un factor que incrementa el número de cache-misses es la fragmentación de datos, ver Fragmentation. La fragmentación incrementa el número de transferencias de memoria hacia la CPU y además imposibilita la vectorización porque el caché no está lleno. El caché puede llenarse sólo al tener bloques contiguos de memoria alojados para los datos (la interconexión o bus sólo puede mover chunks de memoria contigua). Python en su implementación común CPython, tiene data fragmentation por ejemplo al usar listas. Las listas de Python alojan locaciones donde se pueden encontrar los datos y no los datos en sí. Al utilizar listas para operaciones matriciales el runtime de Python tiene overhead en la transferencia de datos pues debe realizar lookups por índices, al no encontrarse de forma contigua los datos se tendrán un mayor número de cache-misses y también los cores deberán esperar hasta que los datos estén disponibles en el caché. Por lo anterior las listas no se recomiendan para operaciones vectoriales o matriciales pero sí se utilizarían para almacenar diferentes tipos de valores en una sola estructura de datos.
En Python se tiene el paquete de NumPy para almacenamiento de bloques de memoria contiguos de arreglos y uso de la capacidad de la CPU para operaciones en un modo vectorizado. Sin extensiones a Python con paquetes como
numpyno sería posible en este lenguaje aprovechar la vectorización (capaz de realizar un procesador actual) ni alojar bloques de memoria contiguos. El no soporte para operaciones vectorizadas tiene que ver con que el bytecode de Python no está optimizado para vectorización. En el caso del alojamiento de bloques de memoria contiguos, Python es un garbage-collected language que permite que la memoria sea automáticamente alojada y liberada. No obstante tal característica causa problemas del tipo memory fragmentation que afecta la transferencia al caché de datos usables o relevantes para las operaciones (ver ejemplo del algoritmo 2 anterior).
Observación
Los archivos con extensión .pyc en Python contienen el bytecode. Ver if-python-is-interpreted-what-are-pyc-files. Ver bytecode para una explicación más general.
Interconexión, bus o capas de comunicación y transferencia de datos#
Hay distintos bus que permiten la comunicación entre las unidades computacionales y las de memoria:
El backside bus que permite la conexión entre el caché y el procesador. Tiene la tasa de transferencia de datos más alta.
El frontside bus permite la conexión entre la RAM y los L’s cachés. Mueve los datos para ser procesados por el procesador (CPU o GPU) y mueve los datos de salida (resultados) entre estas regiones de memoria.
El external bus cuya acción se realiza en los dispositivos de hardware como los discos duros y tarjetas de memoria hacia la CPU y el sistema de memoria. Este bus típicamente es más lento que el frontside bus.
Entonces los datos se mueven del disco hacia la RAM con el external bus, luego de la RAM hacia el caché vía el frontside bus y finalmente del caché hacia la CPU con el backside bus.
Comentarios
La GPU está conectada en un dispositivo periférico y se comunica através del PCI bus, (ver PCI) el cual es más lento que el frontside bus. Como resultado, la transferencia de datos hacia la GPU y fuera de ésta es una operación costosa. Un diseño que atiende este problema es tener tanto a la CPU como a la GPU en el frontside bus para reducción de costos de transferencia hacia la GPU para grandes cantidades de información.
Otra capa de comunicación en un sistema de computadora es la red o network. Un dispositivo de red puede conectarse a una unidad de memoria u a otra unidad de computación. Típicamente la comunicación por red es mucho más lenta que las comunicaciones con el backside, frontside, external bus descritos antes.
La propiedad principal de un bus es su velocidad: ¿cuántos datos pueden moverse en un periodo de tiempo? Esta propiedad se obtiene combinando el bus width entendido como ¿cuántos datos se pueden mover en una transferencia? (físicamente se puede observar por el número de cables del bus) y el bus frequency ¿cuántas transferencias se pueden hacer por segundo? (físicamente se ve en la longitud de los cables que unen a las unidades de cómputo o memoria).
Es importante notar que el movimiento de los datos en una transferencia siempre es secuencial: un pedazo de datos es leído de memoria y es movido a otro lugar: no es posible leer un pedazo de datos y moverlo a distintos lugares o leer divisiones del pedazo de datos que estén en distintos lugares.
Un bus width grande ayuda a la vectorización pues en una sola transferencia se mueven los datos importantes. Un bus frequency alto puede ayudar al código a realizar una gran candidad de lecturas de diferentes lugares de la memoria. Depende qué operación es la que se desea realizar lo que en un caso u otro convendrá. Por ejemplo, si el problema a resolver se relaciona con la cantidad de lecturas que se deben hacer, podríamos tener un bus frequency alto y un bus width pequeño para resolver un bottleneck de lecturas.
Unidades computacionales#
Sea una CPU o una GPU, las unidades computacionales toman como input un conjunto de bits (que representan números por ejemplo) y producen otro conjunto de bits (por ejemplo la suma de los números). El performance de éstas unidades se mide en instrucciones por ciclo (IPC) y en ciclos por segundo, nombrado clock rate o clock speed. La IPC puede incrementarse vía la vectorización pues piénsese que en una misma carga de datos en el caché se pueden realizar más operaciones que hacen referencia al bloque de datos en cuestión.
Entre los rediseños que se han hecho para las unidades computacionales de un modelo clásico de Von Neumman con el objetivo de resolver los bottlenecks, mejorar la velocidad y el performance se encuentran:
Múltiples CPU’s o cores#
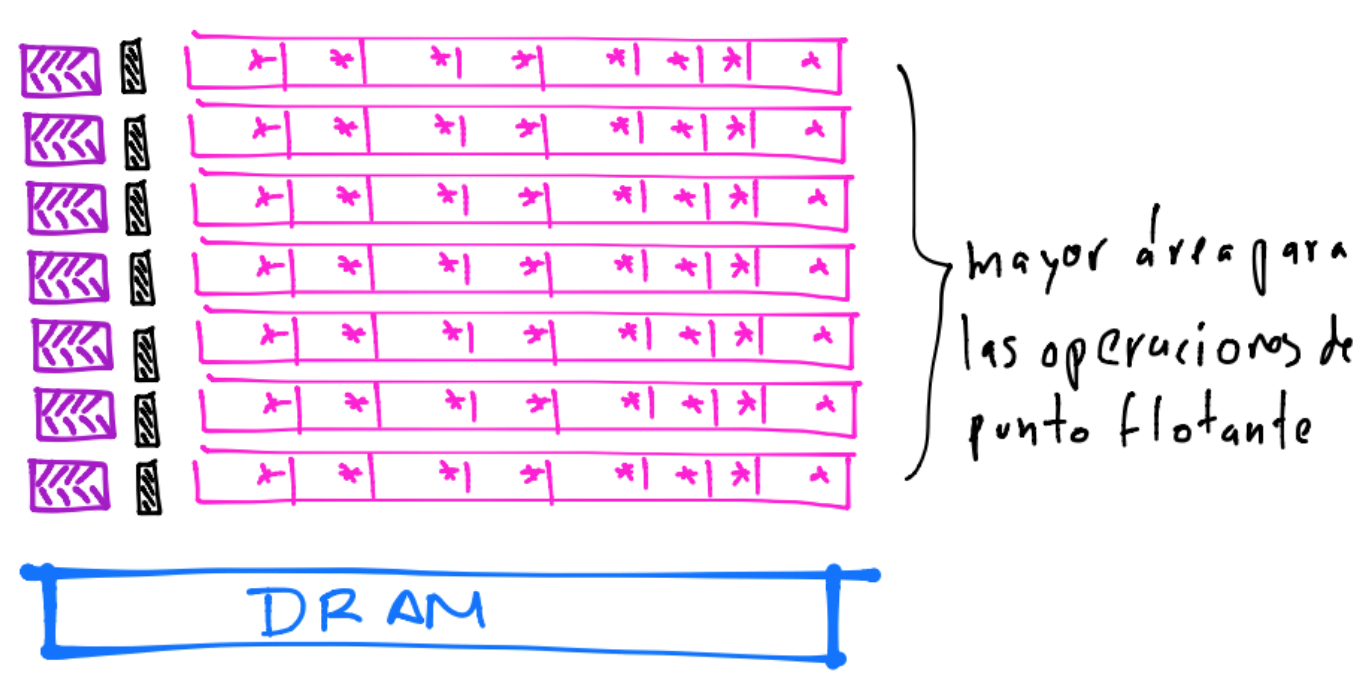
Incrementar el clock speed en una unidad computacional hace más rápido a un programa y también es importante la medida de IPC. La IPC se puede incrementar vía la vectorización y es típico en procesadores que soportan las instrucciones llamadas Single Instruction Multiple Data (SIMD). La vectorización consiste en que dados múltiples datos, el procesador puede trabajar sobre ellos en un instante o tiempo (ejecución en paralelo):
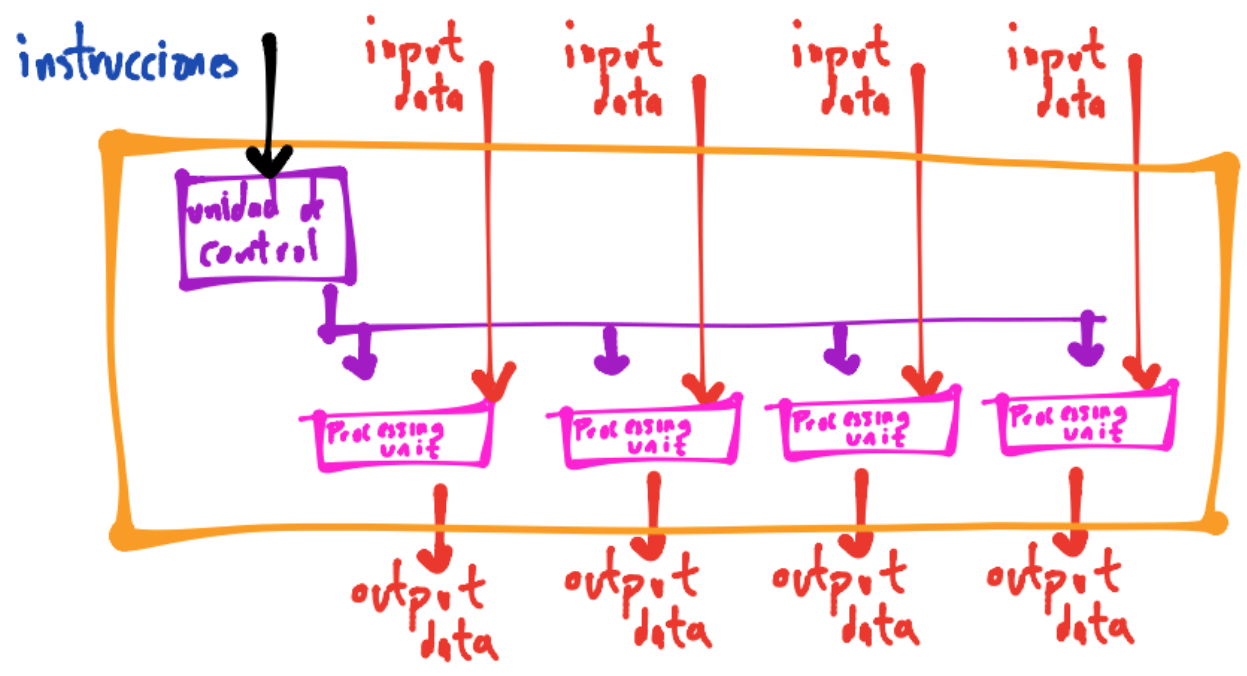
Observación
El término core hoy en día lo usamos como sinónimo de procesador.
Comentarios
Este tipo de procesadores reemplazaron al modelo de Von Neumann clásico Single Instruction Single Data (SISD):
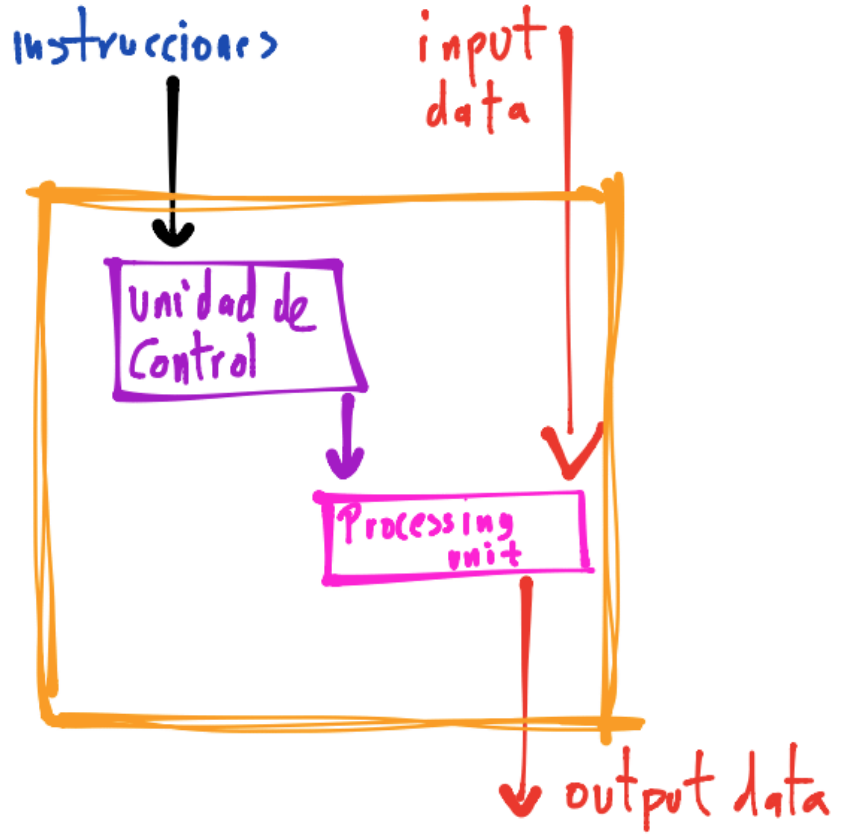
en el que un conjunto de datos se procesaban en un tiempo determinado y no de forma simultánea o en paralelo. Así, se transitó de un diseño de hardware secuencial hacia un hardware paralelo.
Un ejemplo de procesadores SIMD son los procesadores vectoriales o en arreglo, ver liga.
En la práctica se ha visto que simplemente añadir más CPU’s o cores al sistema no siempre aumenta la velocidad de ejecución en un programa. Existe una ley que explica lo anterior, la ley de Amdahl, la cual indica que si un programa está diseñado para ejecutarse en múltiples cores y tiene algunas secciones de su código que pueden sólo ejecutarse en un core, entonces éste será el bottleneck del programa. Por ejemplo, si tuviéramos que realizar una encuesta que tarda \(1\) min a \(100\) personas y tenemos una sola persona, entonces nos tardaríamos \(100\) minutos (proceso secuencial). Si tenemos a \(100\) personas entonces nos tardaríamos \(1\) minuto en completar todas las encuestas (proceso en paralelo). Pero si tenemos más de \(100\) personas, entonces no nos tardaremos menos de \(1\) minuto pues las personas “extras” no podrán participar en realizar la encuesta. En este punto la única forma de reducir el tiempo es reducir el tiempo que le toma a una persona encuestar a otra (esta es la parte secuencial del programa).
Los sistemas SISD, SIMD y Multiple Instruction Multiple Data (MIMD), presentado a continuación:
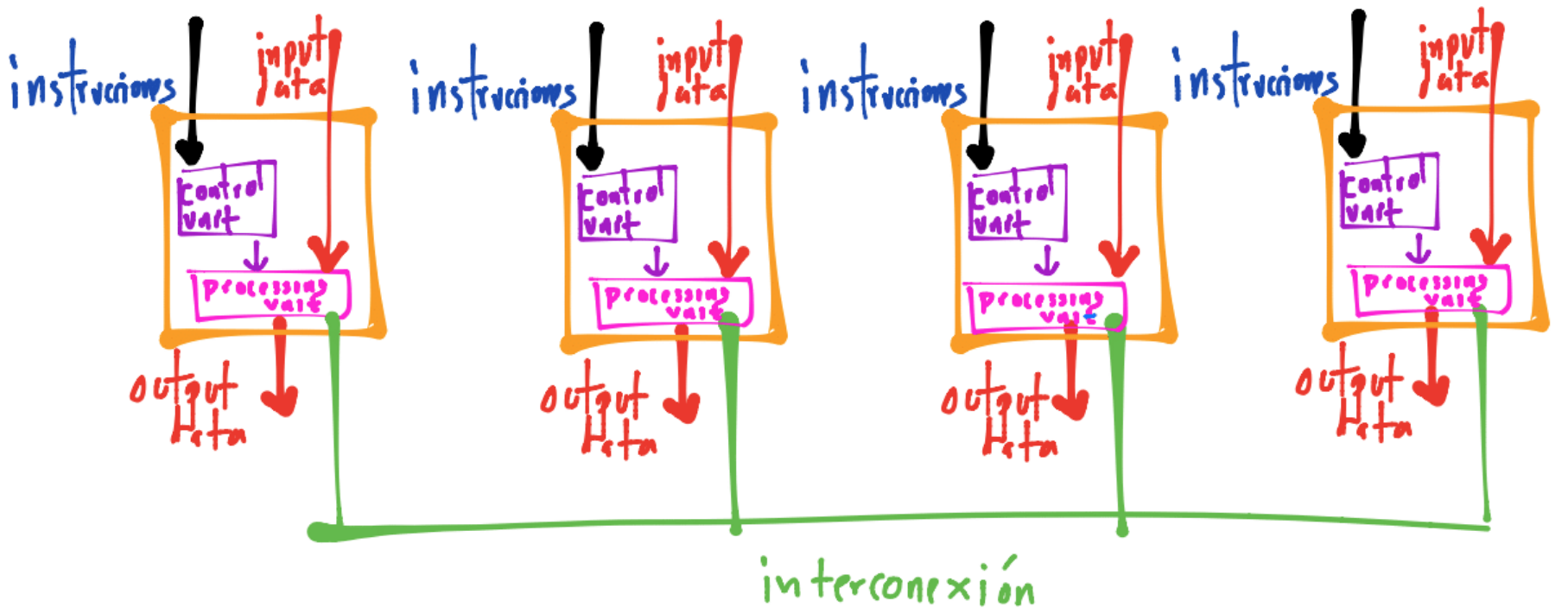
son parte de la taxonomía de Flynn que clasifica a los sistemas dependiendo del stream de datos e instrucciones que puede procesar. Ejemplos de sistemas MIMD son máquinas multicore y clústers de máquinas.
En la taxonomía de Flynn hay una división más, la del sistema Simple Program Multiple Data (SPMD) en el que un mismo programa se ejecuta en múltiples datos, éste sistema lo encontramos en la GPU por ejemplo.
Hoy en día la industria continúa desarrollando y creando procesadores capaces de ejecutar instrucciones basadas en operaciones vectorizadas. Ver por ejemplo Streaming SIMD Extensions 2: SSE2 y Advanced Vector Extensions: AVX.
El incremento en IPC vía la vectorización se enfoca a que las instrucciones tiendan a completar trabajo útil por ciclo pues podría darse la situación en la que se tiene: a high rate of instructions, but a low rate of actual work completed.
Threading o Hyperthreading#
Otra funcionalidad que se les añadió a los procesadores para incrementar la velocidad de ejecución de un proceso y resolver el bottleneck de Von Neumann fue la capacidad de crear hilos, threads, de ejecución en un programa contenidos en un proceso. Esto es nombrado threading o hyperthreading en una CPU o en un core. Básicamente el threading permite la ejecución de más de una instrucción en un mismo core “virtualizando” un procesador adicional (el sistema operativo “cree” que en lugar de haber un core hay dos).
Definiciones
Un proceso es una instancia de un programa que se ejecuta en el procesador y está compuesto por elementos como por ejemplo los bloques de memoria que puede utilizar (los llamados stack y heap) e información de su estado, entre otros.
Un thread, al igual que un proceso, es una instancia de un programa, se ejecuta en el procesador pero está contenido en el proceso del que salió. Al estar contenido en el proceso, comparte elementos de éste, tienen distinto stack de memoria (variables locales creadas en funciones) y en sistemas multicore es posible definir variables que sean accesadas por todos los threads (variables compartidas).
La creación de threads a partir de un proceso se le nombra fork y su unión al proceso se le nombra join:
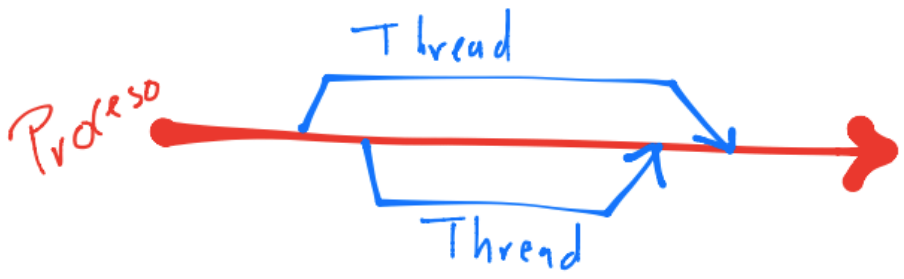
Ambas acciones constituyen al threading que realiza un core, ver multithreading, thread.
Vectorización y niveles de BLAS#
En términos simples vectorizar una operación significa realizar la operación de forma independiente al mismo tiempo sobre diferentes pedazos de datos. La vectorización sólo puede realizarse si se llena el caché con los datos usables o relevantes para la operación. Para lograr esto el bus moverá pedazos de memoria contiguos lo cual será posible sólo si los datos están almacenados secuencialmente en la memoria. Si se tiene data fragmentation causará memory fragmentation pues se tendrán los datos esparcidos en la memoria. Aún si se llenara la capacidad del bus width si no se tienen los datos usables o relevantes para la operación se tendrán cache misses.
Los múltiples cores junto con la funcionalidad del threading permiten a la CPU o GPU la vectorización. Análogamente la vectorización puede realizarse en un clúster de máquinas con el cómputo distribuido: cada máquina procesa un pedazo de los datos de un arreglo de una o más dimensiones.
Para lograr la vectorización los paquetes de software utilizan el hecho que el cómputo matricial está construído sobre una jerarquía de operaciones del álgebra lineal:
Productos punto involucran operaciones escalares de suma y multiplicación (nivel BLAS 1).
La multiplicación matriz-vector está hecha de productos punto (nivel BLAS 2).
La multiplicación matriz-matriz utiliza colecciones de productos matriz-vector (nivel BLAS 3).
Las operaciones anteriores se describen en el álgebra lineal con la teoría de espacios vectoriales pero también es posible describirlas en una forma algorítmica. Ambas descripciones se complementan una a la otra.
Comentario
El acrónimo BLAS es el nombre de la especificación que prescribe el conjunto de rutinas para realizar las operaciones del álgebra lineal. Hay diferentes implementaciones de tal especificación como se verá más adelante. Ver Basic Linear Algebra Subprograms.
Ejemplo de operación nivel BLAS 1: producto interno estándar o producto punto#
Consideramos \(x,y \in \mathbb{R}^n\). El producto punto entre \(x\) y \(y\) es \(c = x^Ty = \displaystyle \sum_{i=1}^n x_iy_i\).
c=0
n=5
x=[-1]*n
y=[1.5]*n
for i in range(n):
c += x[i]*y[i]
print(c)
-7.5
Implementaciones de la API standard de BLAS y LAPACK#
En Handle different versions of BLAS and LAPACK se explica que BLAS: Basic Linear Algebra Subprograms y Linear Algebra Package: LAPACK además de ser implementaciones, también son API standard para operaciones básicas del álgebra lineal. Muchas implementaciones de la API existen. Un ejemplo de implementaciones son las incluidas al instalar R o Python. Otras son las que se pueden instalar vía línea de comando:
sudo apt-get install -y libblas3 libblas-dev liblapack3 liblapack-dev
en un sistema operativo Ubuntu por ejemplo.
Sin embargo existen otras implementaciones de la API que están optimizadas para la arquitectura de nuestras máquinas, por ejemplo:
Comentario
Ver Building from source-Prerequisites para información sobre diferentes librerías de álgebra lineal que se pueden utilizar para NumPy al instalarlas en nuestras máquinas.
¿Qué es el perfilamiento y por qué es necesario?#
Programmers waste enormous amounts of time thinking about, or worrying about, the speed of noncritical parts of their programs, and these attempts at efficiency actually have a strong negative impact when debugging and maintenance are considered
—D. Knuth
We should forget about small efficiencies, say about 97% of the time: premature optimization is the root of all evil. Yet we should not pass up our opportunities in that critical 3%”. A good programmer … will be wise to look carefully at the critical code; but only after that code has been identified
—D. Knuth
El perfilamiento de código nos ayuda a encontrar bottlenecks de nuestro código ya sea en el uso de CPU, RAM, network bandwidth u operaciones hacia el disco de Input/Output (I/O).
Una mala práctica que es común al iniciar en la programación es intentar optimizar el código (y por optimización piénsese en algún caso, por ejemplo mejorar el tiempo de ejecución de un bloque de código) a ciegas, intentando cambiar líneas de código por intuición y no por evidencias o mediciones. Esto aunque puede funcionar en algunas ocasiones no conduce la mayoría de las veces a corregir los problemas de los bottlenecks del código (o bien en programas o ¡sistemas enteros!). La optimización guiada por la intuición conduce a un mayor tiempo en el desarrollo para un pequeño incremento en el performance.
Si bien es importante que el código resuelva un problema definido, también es importante perfilarlo. Considérese el caso en el que un código resuelve bien un problema en un día completo, es importante entonces perfilarlo para realizar mediciones (CPU, memoria p.ej.) de los lugares en los que el código gasta la mayor parte de tiempo (en general recursos).
A largo plazo el perfilamiento de código te dará las decisiones más pragmáticas posibles con el menor esfuerzo total.
Al perfilar tu código no olvides lo siguiente:
Medir el tiempo total de tus códigos para decidir si se requiere optimizarlos.
Perfilar tus códigos para decidir en dónde se iniciará con la optimización. También ayuda definir hipótesis para decidir en qué bloques perfilar primero.
Escribir tests para asegurarse que se resuelve el problema de forma correcta al igual que antes de perfilarlo y optimizarlo.
Cualquier recurso medible puede ser perfilado (no sólo el uso de CPU p.ej.).
Perfilar típicamente añade overhead en la ejecución del código (aumento de tiempo de 10x o 100x es común).
También considera el tiempo que inviertes para optimizar tu código y si vale la pena la inversión de tiempo que realizas en esto pues hay códigos que casi no son utilizados y otros que sí. No pierdas de vista:

Principalmente porque es tentativo caer en la mala práctica de tratar de remover todos los bottlenecks. Sé una persona práctica, define un tiempo objetivo para tu código y optimiza sólo para llegar a ese objetivo.
Algunas strategies to profile your code successfully extraídas de high performance python para un perfilamiento de código exitoso:
Disable TurboBoost in the BIOS (a cool CPU may run the same block of code faster than a hot CPU).
Disable the operating system’s ability to override the SpeedStep (you will find this in your BIOS if you’re allowed to control it).
Only use mains power (never battery power) <- a laptop on battery power is likely to more agressively control CPU speed than a laptop on mains power.
Disable background tools like backups and Dropbox while running experiments.
Run the experiments many times to obtain a stable measurement.
Possibly drop to run level 1 (Unix) so that no other tasks are running.
Reboot and rerun the experiments to double-confirm the results.
Otras estrategias las encuentran en Reproducible benchmarking in Linux-based environments.
Unit testing#
Además del perfilamiento del código, el unit testing ayuda a validar que cada unidad del software trabaje y se desempeñe como fue diseñada (una unidad puede ser una función, programa, procedimiento, método). El unit testing es importante pues se debe cuidar que el código genere resultados correctos. Puede realizarse independientemente del perfilamiento y si se ha hecho perfilamiento es muy indispensable que se haga un unit testing.
Unit testing during optimization to maintain correctness: … after spending a day optimizing her code, having disabled unit tests because they were inconvenient, only to discover that her significant speedup result was due to breaking a part of the algorithm she was improving…
…If you try to performance test code deep inside a larger project without separating it from the larger project, you are likely to witness side effects that will sidetrack your efforts. It is likely to be harder to unit test a larger project when you’re making fine-grained changes, and this may further hamper your efforts. Side effects could include other threads and processes impacting CPU and memory usage and network and disk activity, which will skew your results.
¿Por qué compilar a código de máquina?#
De las opciones que tenemos a nuestra disposición para resolver bottlenecks en nuestro programa es hacer que nuestro código haga menos trabajo. Compilando nuestro código a código de máquina para que el código en los lenguajes tipo intérpretes ejecuten menos instrucciones es una opción a seguir.
¿Por qué puede ser lenta la ejecución de un bloque de código en Python (o en algún otro lenguaje tipo intérprete)?#
Verificación de tipo de valores: si son
int,doubleostringu otros.Los objetos temporales que se crean por tipo de dato causa overhead .
Las llamadas a funciones de alto nivel. Por ejemplo las que ayudan a almacenar al objeto en memoria.
son tres de las fuentes que hacen a un lenguaje tipo intérprete como Python R o Matlab lento. También otras fuentes son:
Desde el punto de vista de la memoria de la máquina, el número de referencias a un objeto y las copias entre objetos.
No es posible vectorizar un cálculo sin el uso de extensiones (por ejemplo paquetes como
numpy).
Comentarios
Hay paquetes que permiten la compilación hacia lenguajes más eficientes como Fortran o C (lenguajes que deben realizar compilación), por ejemplo cython o rcpp.
Escribir directamente en el lenguaje C en un equipo para un proyecto de desarrollo de software indudablemente cambiará la velocidad de su trabajo si no conocen tal lenguaje. En este caso se recomienda ver ganancias y pérdidas para los tiempos de entrega del proyecto.
En la práctica si se tiene un bottleneck que no ha podido resolverse con herramientas como el cómputo en paralelo o vectorización, se recomienda utilizar paquetes para compilación hacia lenguajes más eficientes en regiones pequeñas del código y así resolver el bottleneck del programa. En ocasiones también puede ser la opción más viable a seguir si escribir un programa con cómputo en paralelo no es una opción.
Sobre los términos concurrencia, paralelo y distribuido#
La distinción entre los términos de paralelo y distribuido es borrosa y en ocasiones es díficil de distinguir.
Paralelo#
El término paralelo típicamente se relaciona con programas cuya ejecución involucra cores o nodos que físicamente son cercanos y comparten memoria o están conectados por una red (network) para ejecución de instrucciones en un mismo tiempo o instante.
Distribuido#
Los programas distribuidos son ejecutados por nodos o máquinas separadas a distancia y una de sus características es que no necesariamente fueron iniciados por un nodo central o scheduler por lo que su ejecución es independiente de los demás nodos. Así como con el término paralelo, existirán instrucciones en los programas que se ejecutarán en un mismo tiempo o instante.
Concurrencia#
El término de concurrencia se refiere a que las múltiples tareas que debe realizar un programa pueden estar en progreso en cualquier instante.
Por ejemplo: cada vez que tu código lee un archivo o escribe a un dispositivo (memoria, disco, network), debe pausar su ejecución para contactar al kernel del sistema operativo, solicitar que se ejecute tal operación, y esperar a que se complete, por ejemplo: alojamiento de memoria. Estas operaciones son órdenes de magnitud más lentas que las instrucciones u operaciones ejecutadas en la CPU y el tiempo que el programa espera a que se completen tales operaciones se le nombra I/O wait. La concurrencia nos ayuda a utilizar este tiempo perdido al permitir ejecutar operaciones mientras que una operación I/O se complete.
Un programa concurrente en lugar de ejecutarse de forma secuencial, esto es, pasar de una línea a otra línea, tiene código escrito para ejecutar distintas líneas conforme sucedan “eventos”. Aquí se involucra una forma de programación llamada asíncrona, por ejemplo si una operación tipo I/O es solicitada, el programa ejecuta otras funciones mientras espera que se complete la operación I/O.
Comentario
Cambiar de función a función en un programa asíncrono también genera costo pues el kernel debe invertir tiempo en hacer todo el set up para ejecutar a la función. La concurrencia funciona bien en programas con alto I/O wait.
¿Por qué el cómputo en paralelo?#
La industria entre los años \(2003-2005\) en lugar de fabricar procesadores monolíticos (clásico Von Neumann) que fueran más rápidos y complejos, decidió fabricar múltiples, simples procesadores, cores, en un sólo chip para incrementar el poder de procesamiento, disminuir el Von Neumann bottleneck y aumentar el clock speed.
Esto fue motivado pues desde el año \(2002\) el incremento del performance de los procesadores con un sólo CPU fue de un \(20\%\) por año vs un \(50\%\) por año entre \(1986\) y \(2002\). Lo anterior se debió a los problemas de la construcción de procesadores monolíticos o de un core relacionados con la disipación del calor por un mayor consumo de energía al hacer más pequeños los transistores.
Hoy en día podemos encontrar en nuestros celulares, laptops, computadoras de escritorio y servidores arquitecturas que cuentan con múltiples cores para procesamiento. Por lo anterior es indispensable explotar tal tecnología para tener programas de máquina más eficientes. Muchos de los dispositivos anteriores además tienen un(os) procesador(es) gráficos.
En una buena cantidad de aplicaciones tenemos que implementar algoritmos considerando tal disponibilidad de cores para reducir el tiempo de procesamiento. Esto conduce a reimplementar o en otros casos a repensar al algoritmo en sí.
Y otro aspecto a tomar en cuenta en esta implementación es la transferencia de datos que existe en la jerarquía de memoria de una máquina.
Definición
Los algoritmos que utilizan un sólo core para procesamiento les nombramos secuenciales, los que utilizan múltiples cores son paralelos.
Programas cuya ejecución es en paralelo#
La decisión de reescribir tu programa secuencial en un programa en paralelo depende mucho de considerar cuatro situaciones:
Tener el hardware para ejecución en paralelo del programa.
Comunicarle al programa que está en un hardware para ejecución en paralelo de instrucciones.
Tener un método que aproveche el hardware paralelo de forma eficiente.
Tiempo invertido en la reescritura de un código secuencial a uno en paralelo vs ganancias en tiempo de ejecución.
Lo primero es fácilmente alcanzable pues hoy en día tenemos celulares con múltiples cores o procesadores. Lo segundo es más dependiente del lenguaje e implementación de éste lenguaje en el que se esté programando. El tercer punto es quizás el más complicado de lograr pues en ocasiones implica repensar el método, disminuir la comunicación lo más posible entre los procesadores, el balanceo de carga o load balancing debe evaluarse y el perfilamiento o el debugging es más difícil en la programación en paralelo que en la forma secuencial. El cuarto punto es esencial para la decisión.
¿Cuando es recomendable pensar en ejecutar en paralelo tu programa?#
Si tus instrucciones a realizar pueden ser divididas en múltiples cores o nodos sin tanto esfuerzo de ingeniería (levantar un clúster de cero es difícil…) o no te lleva mucho tiempo el rediseño de tus métodos para decisiones prácticas (paralelizar el método de despomposición en valores singulares, SVD, es difícil de realizar…) entonces es una opción a considerar. Se recomienda mantener el nivel de paralelización lo más simple posible (aunque no se esté utilizando el 100% de todos tus cores) de modo que el desarrollo de software sea rápido.
Si tengo n procesadores ¿espero un speedup de \(nx\)?#
Normalmente no se tiene un mejoramiento en la velocidad de \(n\) veces (\(nx\)) (por ejemplo, si tienes una máquina de \(8\) cores es poco probable que observes un \(8x\) speedup).
Las razones de esto tienen que ver con que al paralelizar instrucciones típicamente se tiene overhead por la comunicación entre los procesos o threads y decrece la memoria RAM disponible que puede ser usada por subprocesos o threads.
También dentro de las razones se encuentran la ley de Amdahl que nos dice que si sólo una parte del código puede ser paralelizado, no importa cuántos cores tengas, en términos totales el código no se ejecutará más rápido en presencia de secciones secuenciales que dominarán el tiempo de ejecución.
¿A qué nos referimos al escribir overhead en un programa cuya ejecución es en paralelo?#
A todo lo que implica ejecutar el programa en paralelo que no está presente en la ejecución en una forma secuencial. Por ejemplo, iniciar procesos implica comunicación con el kernel del sistema operativo y por tanto, tiempo.
¿Cuáles enfoques puedo utilizar para escribir programas en paralelo?#
Hay \(2\) enfoques muy utilizados para escribir programas en paralelo:
Paralelizar las tareas entre los cores. Su característica principal es la ejecución de instrucciones distintas en los cores. Por ejemplo: al llegar la persona invitada a casa, María le ofrecerá de tomar y Luis le abrirá la puerta.
Paralelización de los datos entre los cores. Su característica principal es la ejecución de mismas instrucciones en datos que fueron divididos por alguna metodología previa. Por ejemplo: tú repartes la mitad del pastel a las mesas 1,2 y 3, y yo la otra mitad a las mesas 4,5 y 6.
Comentarios
No son enfoques excluyentes, esto es, podemos encontrar ambos en un mismo programa. La elección de alguno de éstos enfoques depende del problema y del software que será usado para tal enfoque.
Obsérvese que en el ejemplo de María y Luis necesitan coordinarse, comunicarse y sincronizarse para tener éxito en recibir a la invitada.
Obsérvese que en el ejemplo de repartir el pastel se requiere un buen load balancing pues no queremos que yo le reparta a \(5\) mesas y tú le repartas a ¡sólo una!.
¿A qué nos referimos con el término embarrassingly parallel problem?#
A los problemas en los que la comunicación entre procesos o threads es cero. Por ejemplo sumar un array a con un array b.
Y en general si evitamos compartir el estado (pensando a la palabra “estado” como un término más general que sólo comunicación) en un sistema paralelo nos hará la vida más fácil (el speedup será bueno, el debugging será sencillo, el perfilamiento será más fácil de realizar…).
¿Cómo inicio en la programación en paralelo de mi código?#
Ian Foster en su libro Designing and Building Parallel Programs da una serie de pasos que ayudan a la programación en paralelo:
Partitioning. Divide the computation to be performed and the data operated on by the computation into small tasks. The focus here should be on identifying tasks that can be executed in parallel.
Communication. Determine what communication needs to be carried out among the tasks identified in the previous step.
Agglomeration or aggregation. Combine tasks and communications identified in the first step into larger tasks. For example, if task A must be executed before task B can be executed, it may make sense to aggregate them into a single composite task.
Mapping. Assign the composite tasks identified in the previous step to processes/threads. This should be done so that communication is minimized, and each process/thread gets roughly the same amount of work.
Comentario
En ocasiones es mejor dejar las tareas simples y redundantes que complicarlas y no redundantes. Por ejemplo, si en el programa en paralelo varios procesadores o threads hacen tarea redundante pero me evitan la comunicación, prefiero este programa a uno en el que haga trabajo no redundate y muy específico a cada procesador o thread pero que la comunicación a realizar sea muy complicada o compleja.
Ejemplo en la regla del rectángulo compuesta en una máquina multicore#
1.Partitioning: la tarea a realizar es el cálculo de un área de un rectángulo para un subintervalo.
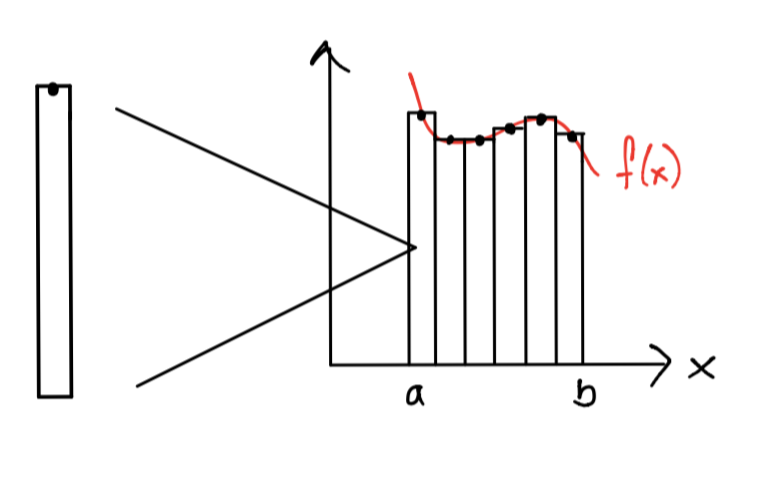
2.Communication y mapping: los subintervalos deben repartirse entre los cores y se debe comunicar esta repartición por algún medio (por ejemplo con variables en memoria).
3.Aggregation: un core puede calcular más de un área de un rectángulo si recibe más de un subintervalo.
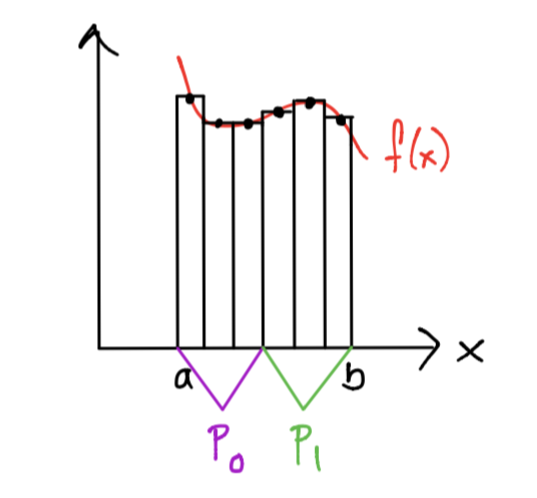
4.Communication y mapping: el área de los rectángulos calculados por cada procesador deben sumarse para calcular la aproximación a la integral.
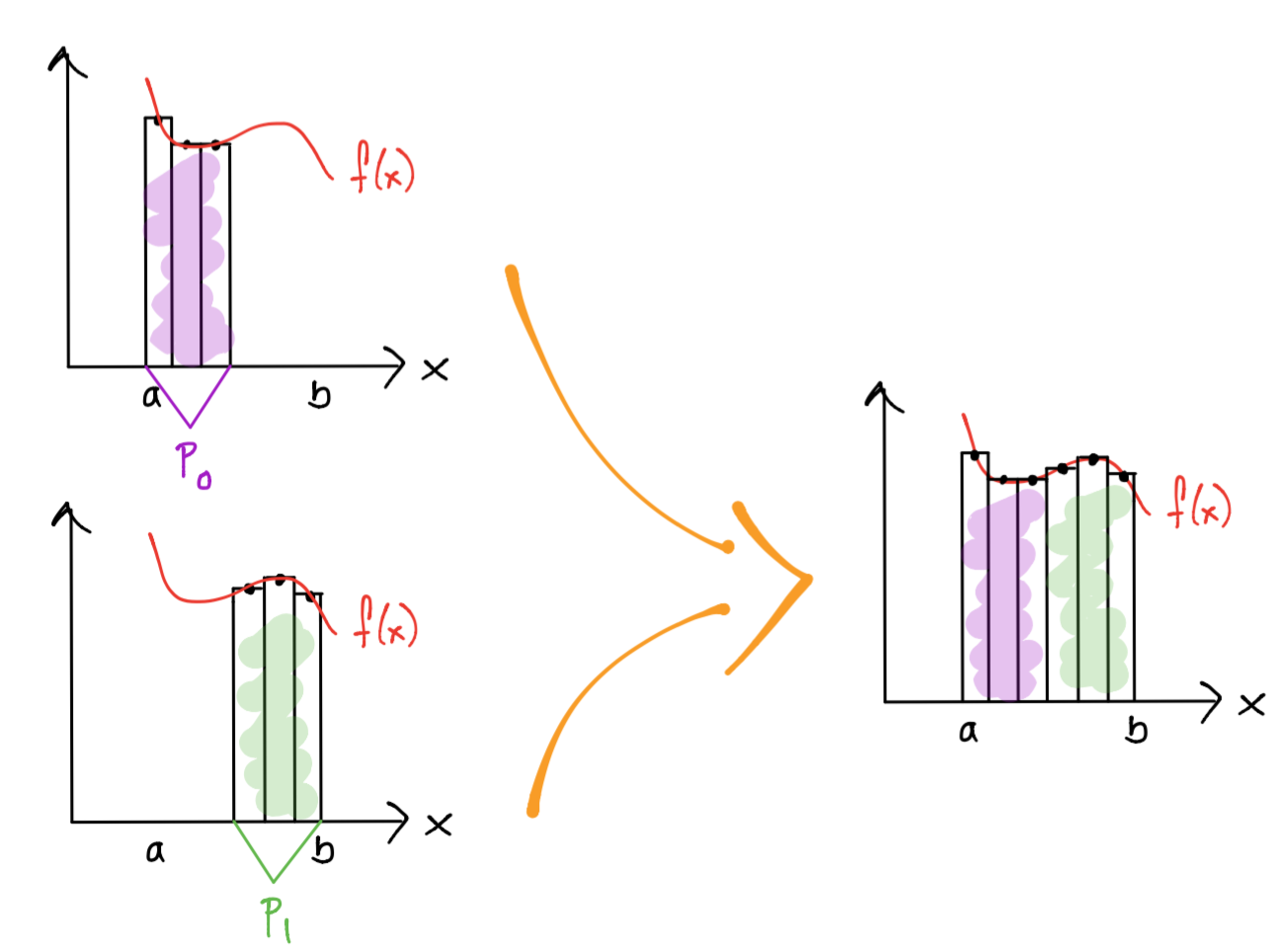
¿Software?#
Nota: las listas de herramientas de software que se presentan son no exhaustivas.
Depende del procesador y arquitectura a utilizar. Si lo que deseamos usar son cores de una CPU en una máquina tenemos:
Cython (que además provee compilación a C)
Numba (que además provee compilación a C)
RcppParallel (que además provee compilación a C++)
Si deseamos usar cores en una GPU y cómputo multi-GPU tenemos:
Numba (que además provee compilación a C)
Rth-org/Rth y más reciente matloff/Rth. Ver también rdrr.io matloff/Rth.
Para cómputo distribuido se encuentran:
Para áreas como deep learning en el uso de la GPU y que también permiten cómputo distribuido y multigpu se tienen:
Varios de los paquetes anteriores están habilitadas con oneDNN para un buen performance en el uso de la CPU/GPU.
Y un estándar para cómputo en sistemas heterogéneos: OpenCL, OpenCL-c-programming-language, OpenCL-Wikipedia
Referencias de interés#
Numerical Linear Algebra on Emerging Architectures: the PLASMA and MAGMA Projects
Para monitoreo de número de instrucciones por ciclo, número de ciclos por segundo, branch misses, cache references (o hits) y misses se recomiendan las herramientas de perf, valgrind, ver también: Valgrind.
Algunas ligas que explican lo que es el garbage collector en Python son: python-garbage-collector, Basics of Memory Management in Python, python-garbage-collection y python-garbage-collector-documentation.
Ver python-vs-cpython para una breve explicación de implementaciones de Python.
Preguntas de comprehensión:
1)¿Qué beneficios se pueden obtener al utilizar operaciones vectorizadas, en qué situaciones podríamos usarlas y cómo se relaciona con la especificación BLAS?
2)¿Qué factores han influido en que desde el 2002-2003 a la fecha, el performance de los procesadores se esté incrementando en un 20% por año vs el 50% de incremento por año que se tenía entre 1986 y 2002?
3)Menciona los componentes y realiza un esquema de una arquitectura von Neumann y descríbelas.
4)Menciona la ley de Amdahl.
5)¿Qué es un proceso y de qué consta?
6)¿Qué es un thread?
7)¿Qué es el threading? ¿qué ventajas nos da para la programación en un sistema de memoria compartida?
8)¿Qué es el caché?
9)Nosotros como programadores o programadoras, ¿cómo podemos obtener ventajas del caché?
10)¿Qué es un cache hit? ¿un cache miss?
11)De acuerdo a la taxonomía de Flynn, ¿qué tipos de arquitecturas existen? Menciona sus características, ventajas /desventajas y ejemplos.
12)Menciona algunos ejemplos de:
a.Sistemas de memoria distribuida.
b.Sistemas de memoria compartida.
13)¿Qué es el pipelining y el branch prediction?
14)Menciona los distintos bus o interconexiones en un sistema de computadora y su propiedad principal o lo que nos interesa medir en un bus.
15)¿Qué significan los términos concurrencia, paralelo, distribuido?
16)¿Cuáles son los enfoques que se utilizan para escribir programas en paralelo?
17)Define a cuál enfoque corresponde (de acuerdo a la pregunta anterior) cada uno de los siguientes incisos:
a)Supón que tienes 2 cores y un arreglo de tamaño 100
if(rango_core módulo 2 == 0 ) operar en los elementos 50 a 99 else operar en los elementos 0 a 49
donde módulo es una operación que nos devuelve el residuo al dividir un número entre otro.
b)Tenemos tres trabajadores: Aurora, Pedro, Daniel
if(mi_nombre es Pedro) lavo el baño else voy de compras
18)En el cómputo en paralelo debemos realizar coordinación entre procesos o threads y considerar el load balancing. Menciona tipos de coordinación que existen y ¿a qué se refiere el load balancing?
19)¿Cuáles son los pasos a seguir, que de acuerdo a Ian Foster, se puede seguir para el diseño de programas en paralelo?
Referencias:
M. Gorelick, I. Ozsvald, High Performance Python, O’Reilly Media, 2014.
E. Anderson, Z. Bai, C. Bischof, L. S. Blackford, J. Demmel, J. Dongarra, J. Du Croz, A. Greenbaum, S. Hammarling, A. Mckenney and D. Sorensen, LAPACK Users Guide, Society for Industrial and Applied Mathematics, Philadelphia, PA, third ed., 1999.
P. Pacheco, An Introduction to Parallel Programming, Morgan Kaufmann, 2011.