3.3 Ejemplos de problemas UCO, introducción a Constrained Inequality and Equality Optimization (CIEO) y puntos interiores
Contents
3.3 Ejemplos de problemas UCO, introducción a Constrained Inequality and Equality Optimization (CIEO) y puntos interiores#
Notas para contenedor de docker:
Comando de docker para ejecución de la nota de forma local:
nota: cambiar <ruta a mi directorio> por la ruta de directorio que se desea mapear a /datos dentro del contenedor de docker y <versión imagen de docker> por la versión más actualizada que se presenta en la documentación.
docker run --rm -v <ruta a mi directorio>:/datos --name jupyterlab_optimizacion -p 8888:8888 -d palmoreck/jupyterlab_optimizacion:<versión imagen de docker>
password para jupyterlab: qwerty
Detener el contenedor de docker:
docker stop jupyterlab_optimizacion
Documentación de la imagen de docker palmoreck/jupyterlab_optimizacion:<versión imagen de docker> en liga.
Nota generada a partir de liga1, liga2, liga3, liga4.
Al final de esta nota la comunidad lectora:
Relacionará las definiciones revisadas en la nota sobre definición de problemas de optimización, conjuntos y funciones convexas y los algoritmos en algoritmos de descenso y búsqueda de línea en UCO con modelos ampliamente utilizados en Machine Learning.
Aprenderá las condiciones que puntos óptimos en un problema estándar de optimización general deben satisfacer, con nombre condiciones de Karush-Kuhn-Tucker de optimalidad, en una forma introductoria y la definición de la función Lagrangiana.
Aprenderá una idea general sobre los métodos de puntos interiores, en específico los de la clase primal-dual para resolver problemas de programación lineal.
Mínimos cuadrados#
Obsérvese que hay una gran cantidad de modelos por mínimos cuadrados, por ejemplo:
Lineales u ordinarios (nombre más usado en Estadística y Econometría).
Mínimos cuadrados lineales#
Se asume en esta sección que \(A \in \mathbb{R}^{m \times n}\) con \(m \geq n\) (más renglones que columnas en \(A\)).
Cada uno de los modelos anteriores tienen diversas aplicaciones y propósitos. Los lineales son un caso particular del problema más general de aproximación por normas:
donde: \(A \in \mathbb{R}^{m \times n}\), \(b \in \mathbb{R}^m\) son datos del problema, \(x \in \mathbb{R}^n\) es la variable de optimización y \(|| \cdot||\) es una norma en \(\mathbb{R}^m\).
Definiciones
\(x^* = \text{argmin}_{x \in \mathbb{R}^n} ||Ax-b||\) se le nombra solución aproximada de \(Ax \approx b\) en la norma \(|| \cdot ||\).
El vector: \(r(x) = Ax -b\) se le nombra residual del problema.
Comentario
El problema de aproximación por normas también se le nombra problema de regresión. En este contexto, las componentes de \(x\) son nombradas variables regresoras, las columnas de \(A\), \(a_j\), es un vector de features o atributos y el vector \(\displaystyle \sum_{j=1}^n x_j^*a_j\) con \(x^*\) óptimo del problema es nombrado la regresión de \(b\) sobre las regresoras, \(b\) es la respuesta.
Si en el problema de aproximación de normas anterior se utiliza la norma Euclidiana o norma \(2\), \(|| \cdot ||_2\), y se eleva al cuadrado la función objetivo se tiene:
que es el modelo por mínimos cuadrados lineales cuyo objetivo es minimizar la suma de cuadrados de las componentes del residual \(r(x)\).
A partir de aquí, la variable de optimización será \(\beta\) y no \(x\) de modo que el problema es:
Supóngase que se han realizado mediciones de un fenómeno de interés en diferentes puntos \(x_i\)’s resultando en cantidades \(y_i\)’s \(\forall i=0,1,\dots, m\) (se tienen \(m+1\) puntos) y además las \(y_i\)’s contienen un ruido aleatorio causado por errores de medición:
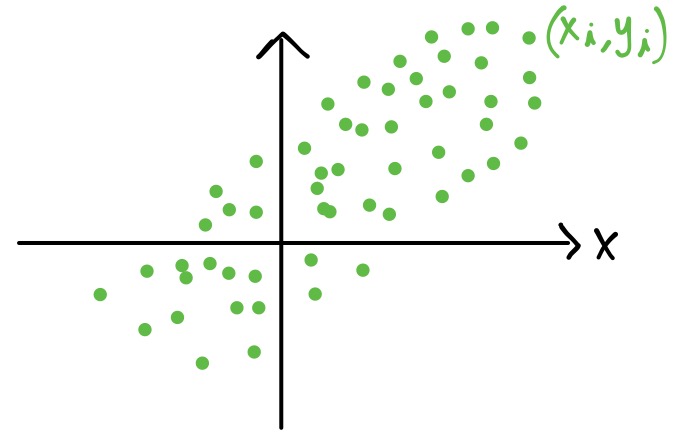
El objetivo de los mínimos cuadrados es construir una curva, \(f(x|\beta)\) que “mejor” se ajuste a los datos \((x_i,y_i)\), \(\forall i=0,1,\dots,m\). El término de “mejor” se refiere a que la suma:
sea lo “más pequeña posible”, esto es, a que la suma de las distancias verticales entre \(y_i\) y \(f(x_i|\beta)\) \(\forall i=0,1,\dots,m\) al cuadrado sea mínima. Por ejemplo:
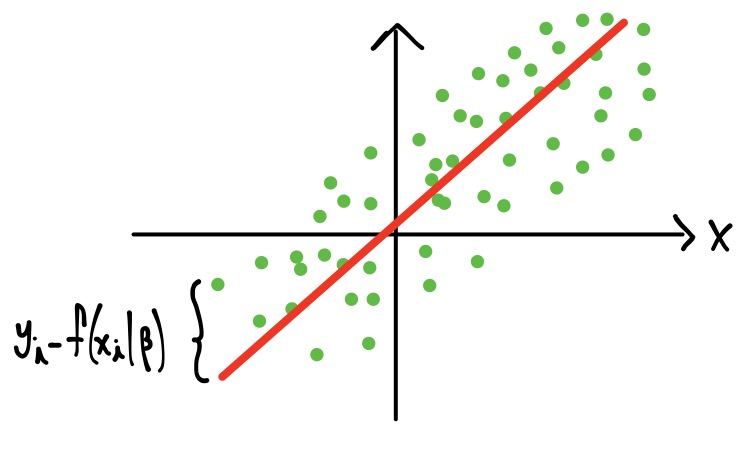
Observación
La notación \(f(x|\beta)\) se utiliza para denotar que \(\beta\) es un vector de parámetros a estimar, en específico \(\beta_0, \beta_1, \dots \beta_n\), esto es: \(n+1\) parámetros a estimar.
Modelo en mínimos cuadrados lineales#
En los mínimos cuadrados lineales se asume un modelo:
con \(\phi_j: \mathbb{R} \rightarrow \mathbb{R}\) funciones conocidas por lo que se tiene una gran flexibilidad para el proceso de ajuste. Con las funciones \(\phi_j (\cdot)\) se construye a la matriz \(A\).
Observación
Si \(n=m\) entonces se tiene un problema de interpolación.
Enfoque geométrico y algebraico para resolver el problema de mínimos cuadrados#
Si \(m=3\) y \(A \in \mathbb{R}^{3 \times 2}\) geométricamente el problema de mínimos cuadrados lineales se puede visualizar con el siguiente dibujo:

En el dibujo anterior:
\(r(\beta) = y-A\beta\),
el vector \(y \in \mathbb{R}^m\) contiene las entradas \(y_i\)’s,
la matriz \(A \in \mathbb{R}^{m \times n}\) contiene a las entradas \(x_i\)’s o funciones de éstas \(\forall i=0,1,\dots,m\).
Por el dibujo se tiene que cumplir que \(A^Tr(\beta)=0\), esto es: las columnas de \(A\) son ortogonales a \(r(\beta)\). La condición anterior conduce a las ecuaciones normales:
donde: \(A\) se construye con las \(\phi_j\)’s evaluadas en los puntos \(x_i\)’s, el vector \(\beta\) contiene a los parámetros \(\beta_j\)’s a estimar y el vector \(y\), la variable respuesta, se construye con los puntos \(y_i\)’s:
Finalmente, considerando la variable de optimización \(\beta\) y al vector \(y\) tenemos: \(A^TA \beta = A^Ty\).
Comentario
Si \(A\) es de \(rank\) completo (tiene \(n+1\) columnas linealmente independientes) una opción para resolver el sistema anterior es calculando la factorización \(QR\) de \(A\): \(A = QR\) y entonces:
\(A^TA\beta = A^Ty\).
Dado que \(A=QR\) se tiene: \(A^TA = (R^TQ^T)(QR)\) y \(A^T = R^TQ^T\) por lo que:
y usando que \(Q\) tiene columnas ortonormales:
Como \(A\) tiene \(n+1\) columnas linealmente independientes, la matriz \(R\) es invertible por lo que \(R^T\) también lo es y finalmente se tiene el sistema de ecuaciones lineales por resolver:
Enfoque utilizando directamente la función objetivo del problema de optimización#
La función objetivo en los mínimos cuadrados lineales puede escribirse de las siguientes formas:
con \(A[i,:]\) \(i\)-ésimo renglón de \(A\) visto como un vector en \(\mathbb{R}^n\). Es común dividir por \(2\) la función objetivo para finalmente tener el problema:
Observación
En cualquier reescritura de la función \(f_o\), el problema de aproximación con normas, o bien en su caso particular de mínimos cuadrados, es un problema de optimización convexa.
Ejemplo#
Planteamos un modelo del tipo: \(f_o(x_i | \beta) = \beta_0\phi_0(x) + \beta_1 \phi_1(x) = \beta_0 + \beta_1 x\)
import numpy as np
import matplotlib.pyplot as plt
import pprint
np.set_printoptions(precision=2, suppress=True)
np.random.seed(1989) #for reproducibility
mpoints = 20
x = np.random.randn(mpoints)
y = -3*x + np.random.normal(2,1,mpoints)
Los datos ejemplo
plt.plot(x,y, 'r*')
plt.xlabel('x')
plt.ylabel('y')
plt.title('Puntos ejemplo')
plt.show()
Utilizamos el paquete cvxpy para resolver el problema de mínimos cuadrados:
import cvxpy as cp
A=np.ones((mpoints,2)) #step 1 to build matrix A
A[:,1] = x #step 2 to build matrix A
n = 2 # number of variables
beta = cp.Variable(n) #optimization variable
fo_cvxpy = (1/2)*cp.quad_form(beta, A.T@A) - cp.sum(cp.multiply(A.T@y, beta)) + 1/2*y.dot(y) #objective function
prob = cp.Problem(cp.Minimize(fo_cvxpy))
print(prob.solve())
10.21773841938797
print("\nThe optimal value is", prob.value)
print("The optimal beta is")
print(beta.value)
print("The norm of the residual is ", cp.norm(A @ beta - y, p=2).value) #also works: cp.norm2(A @ beta - y).value
The optimal value is 10.21773841938797
The optimal beta is
[ 2.03 -2.65]
The norm of the residual is 4.520561562325624
El paquete CVXPY ya tiene una función para resolver el problema anterior, ver least_squares.
fo_cvxpy = 1/2*cp.sum_squares(A@beta -y)
prob = cp.Problem(cp.Minimize(fo_cvxpy))
print(prob.solve())
10.217738419387942
print("\nThe optimal value is", prob.value)
print("The optimal beta is")
print(beta.value)
print("The norm of the residual is ", cp.norm(A @ beta - y, p=2).value) #also works: cp.norm2(A @ beta - y).value
The optimal value is 10.217738419387942
The optimal beta is
[ 2.03 -2.65]
The norm of the residual is 4.520561562325624
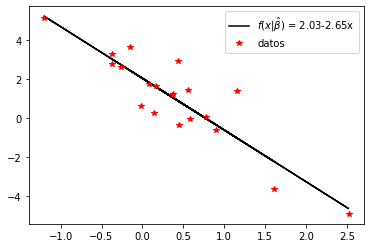
Entonces el vector \(\beta\) ajustado es: \(\hat{\beta_0} \approx 2.03, \hat{\beta_1} \approx -2.65\) y por tanto el modelo es:
y_hat_numpy = beta.value[0] + beta.value[1] * x
plt.plot(x, y_hat_numpy, "k-",
x, y, "r*")
plt.legend(["$f(x|\\hat{\\beta})$ = 2.03-2.65x","datos"], loc="best")
plt.show()
El problema de clasificación en dos clases \(\mathcal{C}_0, \mathcal{C}_1\)#
Sean \(\mathcal{C}_0 , \mathcal{C}_1\) dos clases ajenas y \(x \in \mathbb{R}^n\). El problema de clasificación consiste en clasificar al vector \(x\) en alguna de las dos clases anteriores de modo que se minimice el error de clasificación.
Ejemplos de lo anterior los encontramos en medicina (persona enferma o no dada una serie de mediciones en sangre), finanzas (persona sujeta a un crédito bancario o no dado un historial crediticio) o clasificación de textos (spam o no spam).
Regresión logística: clasificación en \(\mathcal{C}_0, \mathcal{C}_1\)#
El modelo por regresión logística tiene por objetivo modelar las probabilidades de pertenencia a cada una de las clases \(\mathcal{C}_0, \mathcal{C}_1\) dado el vector de features o atributos \(x \in \mathbb{R}^n\): \(p(\mathcal{C}_0|x) , p(\mathcal{C}_1|x)\).
En la regresión logística se utiliza la función sigmoide \(\sigma:\mathbb{R} \rightarrow \mathbb{R}\):
para modelar ambas probabilidades ya que mapea todo el eje real al intervalo \([0,1]\). Además resulta ser una aproximación continua y diferenciable a la función de Heaviside \(H:\mathbb{R} \rightarrow \mathbb{R}\)
mpoints = 100
t = np.linspace(-10, 10, mpoints)
Heaviside = 1*(t>0)
import matplotlib.pyplot as plt
plt.plot(t, Heaviside, '.')
plt.show()
A continuación graficamos a la sigmoide \(\sigma(ht)\) para distintos valores de \(h \in \{-3, -1, -1/2, 1/2, 1, 3\}\):
sigmoid = lambda t_value: 1/(1+np.exp(-t_value))
h = np.array([-3, -1, -1/2, 1/2, 1, 3])
n = len(h)
sigmoids = np.zeros((mpoints, n))
for i in range(len(h)):
sigmoids[:,i] = sigmoid(h[i]*t)
plt.figure(figsize=(7,7))
plt.plot(t, sigmoids[:,0],
t, sigmoids[:,1],
t, sigmoids[:,2],
t, sigmoids[:,3],
t, sigmoids[:,4],
t, sigmoids[:,5])
l = ["h=-3", "h=-1", "h=-1/2", "h=1/2", "h=1", "h=3"]
plt.legend(l, bbox_to_anchor=(1,1))
plt.title("Diferentes funciones sigmoides $\sigma(ht)$")
plt.show()
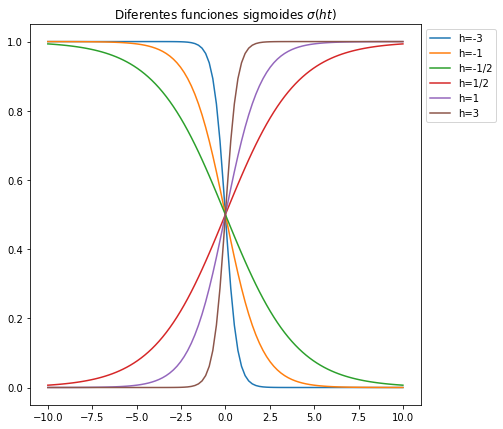
Obsérvese la forma de cada curva al variar \(h\) en la función \(\sigma(ht)\). Una regla de clasificación podría ser clasificar como perteneciente a \(\mathcal{C}_0\) si la probabilidad (modelada por la curva sigmoide) es menor a \(0.25\) (punto de corte) y perteneciente a \(\mathcal{C}_1\) si es mayor o igual a \(0.25\). Para diferentes curvas sigmoides presentadas en la gráfica anterior obsérvese que al fijar el punto de corte y tomar un valor de \(t\) en el eje horizontal, la pertenencia a alguna de las clases es menos sensible al variar \(t\) que en otras curvas.
Así, la función sigmoide permite modelar la probabilidad de pertenencia a la clase \(\mathcal{C}_1:\)
para alguna \(a \in \mathbb{R}\).
Con el teorema de Bayes se obtiene el valor de \(a\):
Por lo tanto:
Comentarios
Algunas propiedades que tiene la función \(\sigma(\cdot)\) se encuentran:
En Estadística a la función:
se le conoce como logit y modela el log momio:
que tiene una interpretación directa en términos de las probabilidades de pertenencia a cada clase \(\mathcal{C}_0,\mathcal{C}_1\).
Modelo en regresión logística de dos clases#
De forma similar como en el modelo por mínimos cuadrados lineales se modeló a la variable respuesta \(y\) con una función lineal en sus parámetros, en el modelo en regresión logística con dos clases e intercepto se propone una función lineal en un vector de parámetros \((\beta_0,\beta) \in \mathbb{R}^{n+1}\) definida por el logit:
Obsérvese que si \(y\) es considerada como variable respuesta que está en función de \(x \in \mathbb{R}^{n+1}\) dado el vector \((\beta_0, \beta)\) se tiene:
que se lee “la probabilidad de pertenencia a la clase \(\mathcal{C}_1\) dado el vector de atributos \(x\) es igual a \(y\)”.
Comentarios
El modelo con \(2\) parámetros \(\beta_0, \beta_1\) se ve como:
con \(x \in \mathbb{R}\).
El modelo puede extenderse utilizando \(n+1\) funciones conocidas \(\phi_j:\mathbb{R} \rightarrow \mathbb{R}\), \(\phi_j(x)\) \(j=0,\dots, n\) por lo que si \(\phi(x)=(\phi_0(x),\phi_1(x),\dots,\phi_n(x))^T\) y \(\beta_0 \in \mathbb{R}\), \(\beta \in \mathbb{R}^n\), entonces se tiene el modelo por regresión logística:
La notación \(y(x | \beta_0, \beta)\) se utiliza para denotar que \((\beta_0, \beta)\) es un vector de parámetros a estimar, en específico \(\beta_0, \beta_1, \dots, \beta_n\), esto es: \(n+1\) parámetros a estimar.
La variable de optimización es \((\beta_0, \beta) \in \mathbb{R}^{n+1}\).
¿Cómo se ajustan los parámetros del modelo por regresión logística de dos clases?#
Dados \((x_0,\hat{y}_0), \dots (x_m, \hat{y}_m)\) puntos se desean modelar \(m+1\) probabilidades de pertenencias a las clases \(\mathcal{C}_0, \mathcal{C}_1\) representadas con las etiquetas \(\hat{y}_i \in \{0,1\} \forall i=0,1,\dots, m\). El número \(0\) representa a la clase \(\mathcal{C}_0\) y el \(1\) a la clase \(\mathcal{C}_1\). El vector \(x_i \in \mathbb{R}^n\) .
Cada probabilidad se modela como \(y_0=y_0(x_0|\beta_0, \beta),y_1=y_1(x_1|\beta_0, \beta),\dots,y_m=y_m(x_n|\beta_0, \beta)\) utilizando:
Los \(n+1\) parámetros \(\beta_0, \beta_1, \dots, \beta_n\) se ajustan maximizando la función de verosimilitud:
donde: \(\hat{y}_i \sim \text{Bernoulli}(y_i)\) y por tanto \(\hat{y}_i \in \{0,1\}\): \(\hat{y}_i = 1\) con probabilidad \(y_i\) y \(\hat{y}_i = 0\) con probabilidad \(1-y_i\). Entonces se tiene el problema:
Lo anterior es equivalente a maximizar la log-verosimilitud:
o a minimizar la devianza:
Comentario
La devianza es una función convexa pues su Hessiana es:
con: \(P\) una matriz diagonal con entradas \(y_i(1-y_i)\) donde: \(y_i\) está en función de \(x_i\): \(y_i(x_i|\beta_0,\beta) = \frac{1}{1+ e^{-(\beta_0 + \beta^T x_i)}} \forall i=0,1,\dots,m\) y la matriz A es:
El valor \(m\) representa el número de observaciones y el valor \(n\) representa la dimensión del vector \(\beta\).
La expresión anterior de la Hessiana se obtiene a partir de la expresión del gradiente:
donde:
Así, la Hessiana de la devianza es simétrica semidefinida positiva y por tanto es una función convexa.
Ejemplo Iris dataset#
Utilizamos el conocido dataset de Iris en el que se muestran tres especies del género Iris. Las especies son: I. setosa, I. virginica y I. versicolor:

Imagen obtenida de Iris Dataset.
!pip install --quiet sklearn
WARNING: You are using pip version 21.2.4; however, version 21.3.1 is available.
You should consider upgrading via the '/usr/bin/python3 -m pip install --upgrade pip' command.
from sklearn import datasets
iris = datasets.load_iris()
data_iris = iris["data"]
print(data_iris[0:10, 0:10])
[[5.1 3.5 1.4 0.2]
[4.9 3. 1.4 0.2]
[4.7 3.2 1.3 0.2]
[4.6 3.1 1.5 0.2]
[5. 3.6 1.4 0.2]
[5.4 3.9 1.7 0.4]
[4.6 3.4 1.4 0.3]
[5. 3.4 1.5 0.2]
[4.4 2.9 1.4 0.2]
[4.9 3.1 1.5 0.1]]
m,n = data_iris.shape
print("número de observaciones:%d, número de atributos: %d" % (m,n))
número de observaciones:150, número de atributos: 4
Columnas en este orden: Sepal.Length, Sepal.Width, Petal.Length, Petal.Width
print(iris["target_names"])
['setosa' 'versicolor' 'virginica']
print(np.unique(iris["target"]))
[0 1 2]
data_iris_setosa_versicolor = data_iris[0:100].copy()
print(np.corrcoef(data_iris_setosa_versicolor, rowvar=False))
[[ 1. -0.21 0.81 0.79]
[-0.21 1. -0.6 -0.57]
[ 0.81 -0.6 1. 0.98]
[ 0.79 -0.57 0.98 1. ]]
classes = iris["target"][0:100].copy()
La clase \(\mathcal{C}_0\) es setosa y \(\mathcal{C}_1\) es versicolor codificadas como \(0, 1\) respectivamente.
La función objetivo como se revisó en la sección anterior está dada por la expresión de la devianza:
donde: \(\hat{y}_i \in \{0,1\}\), \(x_i\) \(i\)-ésimo renglón de matriz \(A \in \mathbb{R}^{100 \times 4}\).
Añadimos la columna que indica uso de intercepto y por tanto de un modelo con \(\beta_0\):
m,n = data_iris_setosa_versicolor.shape
data_iris_setosa_versicolor = np.column_stack((np.ones((m,1)), data_iris_setosa_versicolor))
print(data_iris_setosa_versicolor[0:10, 0:10])
[[1. 5.1 3.5 1.4 0.2]
[1. 4.9 3. 1.4 0.2]
[1. 4.7 3.2 1.3 0.2]
[1. 4.6 3.1 1.5 0.2]
[1. 5. 3.6 1.4 0.2]
[1. 5.4 3.9 1.7 0.4]
[1. 4.6 3.4 1.4 0.3]
[1. 5. 3.4 1.5 0.2]
[1. 4.4 2.9 1.4 0.2]
[1. 4.9 3.1 1.5 0.1]]
Función objetivo:
n = n+1 #number of variables
beta = cp.Variable(n) #optimization variable
fo_cvxpy = 2*cp.sum(
cp.logistic(data_iris_setosa_versicolor @ beta) - cp.multiply(classes, data_iris_setosa_versicolor @ beta)
)
obj = cp.Minimize(fo_cvxpy)
prob = cp.Problem(obj)
print(prob.solve())
2.935191734155412e-07
print("\nThe optimal value is", prob.value)
print("The optimal beta is")
print(beta.value)
The optimal value is 2.935191734155412e-07
The optimal beta is
[ 9.71 -3.97 -13.54 11.16 25.52]
Cálculo de probabilidades de pertenencia a las clases \(\mathcal{C}_0 :\) setosa, \(\mathcal{C}_1 :\) versicolor#
Para individuo \(i\) se tiene:
Por ejemplo, para el renglón \(1\) de data_iris_setosa_versicolor, que sabemos que pertenece a la clase \(\mathcal{C}_0\): setosa:
Estimación de la probabilidad de pertenencia a la clase \(\mathcal{C}_1\), versicolor:
linear_value = -data_iris_setosa_versicolor[0,:].dot(beta.value)
print(1/(1+np.exp(linear_value)))
7.002516747523349e-17
Estimación de la probabilidad de pertenencia a la clase \(\mathcal{C}_0\), setosa:
print(np.exp(linear_value) / (1+np.exp(linear_value)))
0.9999999999999999
Por ejemplo, para el último renglón de data_iris_setosa_versicolor, que sabemos que pertenece a la clase \(\mathcal{C}_1\), versicolor:
Estimación de la probabilidad de pertenencia a la clase \(\mathcal{C}_1\), versicolor:
linear_value = -data_iris_setosa_versicolor[m-1,:].dot(beta.value)
print(1/(1+np.exp(linear_value)))
0.9999999999993738
Estimación de la probabilidad de pertenencia a la clase \(\mathcal{C}_0\), setosa:
print(np.exp(linear_value) / (1+np.exp(linear_value)))
6.261520333516334e-13
Ejercicio
Realiza la clasificación y cálculo de probabilidades anterior para las clases virginica y versicolor.
Introducción a Constrained Inequality and Equality Optimization (CIEO)#
Recuérdese que para Unconstrained Optimization (UO) se dieron condiciones que deben satisfacer puntos para ser óptimos en sobre problemas de optimización. En esta sección se darán ejemplos que ayudarán a describir condiciones que caracterizan las soluciones para un problema estándar de optimización:
con \(f_o\), \(f_i: \mathbb{R}^n \rightarrow \mathbb{R}\) \(\forall i=1,\dots,m\), \(h_i: \mathbb{R}^n \rightarrow \mathbb{R}\), \(\forall i=1,\dots,p\). \(f_i\) son las restricciones de desigualdad, \(h_i\) son las restricciones de igualdad.
Definición
El problema anterior se le nombra problema primal.
En lo que continúa se asume que \(f_i\), \(h_i\) son funciones de clase \(\mathcal{C}^2\) en sus dominios respectivos.
Ejemplo 1#
Considérese el siguiente problema de optimización:
En el cual:
de modo que al evaluar en diferentes puntos los gradientes anteriores se tiene una situación siguiente:
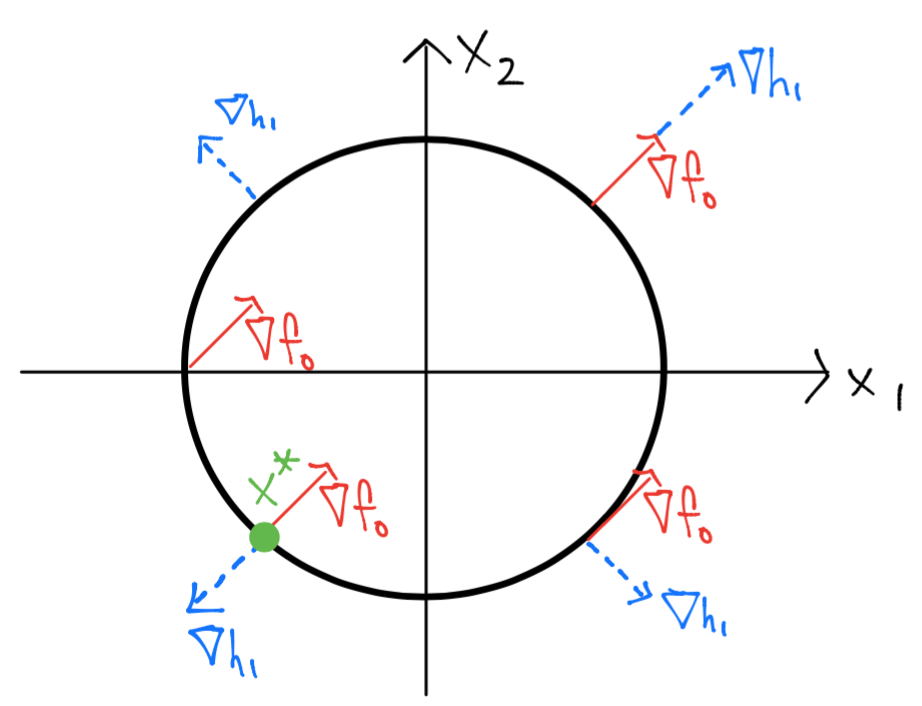
Por el dibujo anterior se tiene que el conjunto de factibilidad para este problema es una circunferencia de radio \(\sqrt{2}\) con centro en el origen. Se puede observar además que \(x^* = \left [ \begin{array}{c}-1 \\ -1 \end{array} \right ]\) pues si estuviéramos en cualquier otro punto, por ejemplo en el punto \(x = \left [ \begin{array}{c}\sqrt{2} \\0 \end{array} \right ]\) entonces cualquier movimiento en dirección en sentido de las manecillas del reloj reducirá el valor de \(f_o\).
También se observa en el dibujo anterior que en la solución \(x^*\), se cumple que:
esto es, son paralelos, de hecho, \(\nu_1^* = \frac{1}{2}\).
Usando el teorema de Taylor aplicado a \(h_1\) y asumiendo que \(x\) es un punto factible, \(\nabla f_o(x) \neq 0\) y \(\Delta x\) una dirección de descenso de longitud pequeña tal que mantiene factibilidad se tiene que:
En resúmen, si el paso \(\Delta x\) mantiene la factibilidad entonces:
Además, como \(\Delta x\) es dirección de descenso:
Si \(x\) no es mínimo local entonces existe tal dirección \(\Delta x\), análogamente si no existe tal dirección entonces \(x\) es un mínimo local. En el dibujo anterior se verifica visualmente esto pues si ambos gradientes no son paralelos entonces podemos elegir una dirección de descenso que satisfaga ambas condiciones anteriores.
Observación
Obsérvese que si \(x^*\) es mínimo local entonces \(\nabla f_o(x^*) = 0\) (condición necesaria de primer orden) por lo que no existen direcciones de descenso.
La función Lagrangiana#
Definición
La función Lagrangiana asociada al problema de optimización (primal) se define como:
con:
y \(\text{dom} \mathcal{L} = \mathcal{D} \times \mathbb{R}^m \times \mathbb{R}^p\) donde: \(\mathcal{D}\) es el dominio del problema de optimización.
En lo que continúa se asume la restricción \(\lambda_i \geq 0 \forall i=1,\dots, m\).
Comentarios
\(\lambda _i\) se le nombra multiplicador de Lagrange asociado con la \(i\)-ésima restricción de desigualdad \(f_i(x) \leq 0\).
\(\nu_i\) se le nombra multiplicador de Lagrange asociado con la \(i\)-ésima restricción de igualdad \(h_i(x)=0\).
Los vectores \(\lambda = (\lambda_i)_{i=1}^m\) y \(\nu = (\nu_i)_{i=1}^p \in \mathbb{R}^p\) se les nombran variables duales o vectores de multiplicadores de Lagrange asociados con el problema de optimización. El vector \(x \in \mathcal{D}\) se le nombra variable primal.
Para el ejemplo anterior se tiene:
Obsérvese que \(\nabla_x \mathcal{L}(x, \nu_1) = \nabla f_o(x) + \nu_1 \nabla h_1(x)\) y en la solución \(x^*\), existe \(\nu_1^*\) tal que \(\nabla_x \mathcal{L} (x^*, \nu_1^*)= 0\).
Observación
La notación \(\nabla_x g(x, y)\) hace referencia al gradiente de \(g(x,y)\) sólo derivando respecto a \(x\).
Comentario
Aunque la condición
es necesaria para \(x^*\) óptimo, ésta no es suficiente pues se satisface en el punto \(x = \left [ \begin{array}{c}1 \\ 1 \end{array} \right ]\) para el ejemplo anterior con \(\nu_1 = -\frac{1}{2}\) pero este punto maximiza \(f_o\) en la circunferencia.
También el signo de \(\nu_1\) no es relevante en este ejemplo pues si se considera la restricción \(2-x_1^2-x_2^2=0\), la solución sigue siendo \((-1, -1)^T\) con \(\nu_1^*=-\frac{1}{2}\).
Ejemplo 2#
Para este ejemplo el conjunto de factibilidad es el interior y frontera del círculo:
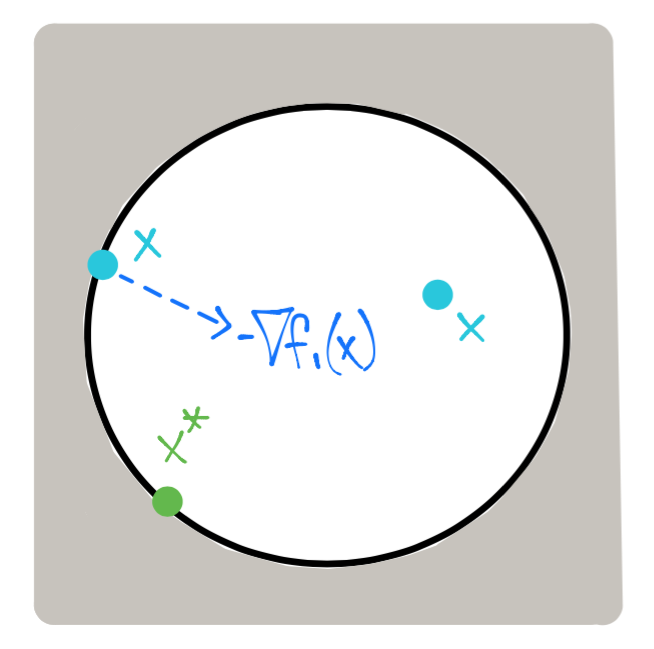
Obsérvese en el dibujo anterior que \(-\nabla f_1(x)\) apunta al interior del conjunto de factibilidad.
La solución de este problema sigue siendo \(x^* = \left [ \begin{array}{c}-1 \\ -1 \end{array} \right ]\) con \(\lambda_1^* = \frac{1}{2}\) al igual que en el ejemplo 1 con \(x_1^2 + x_2^2 -2 = 0\). Sin embargo, la diferencia con el ejemplo anterior es que el signo \(\lambda_1\) es importante como se describirá a continuación.
Si \(x\) no es óptimo entonces como en el ejemplo anterior podemos encontrar una dirección \(\Delta x\) que satisfaga factibilidad, \(f_1(x) \leq 0\), y reduzca \(f_o\).
Usando el teorema de Taylor aplicado a \(f_1\) y asumiendo que \(x\) es un punto factible, \(\nabla f_o(x) \neq 0\) y \(\Delta x\) una dirección de descenso de longitud pequeña tal que mantiene factibilidad se tiene que:
En resúmen, si el paso \(\Delta x\) mantiene la factibilidad entonces:
Además, como \(\Delta x\) es dirección de descenso:
Tenemos que analizar dos casos dependiendo si \(f_1\) es o no activa en \(x\) para la desigualdad \(f_1(x) + \nabla f_1(x)^T \Delta x \leq 0\):
Caso \(f_1\) inactiva en \(x\): \(f_1(x) < 0\), entonces \(x\) está dentro del círculo:
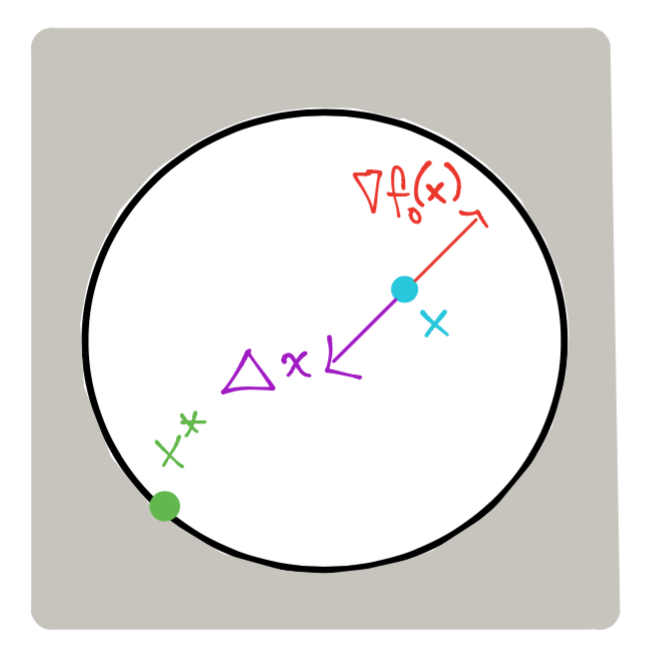
En este caso cualquier dirección \(\Delta x\) cuya longitud sea suficientemente pequeña satisface \(f_1(x) + \nabla f_1(x)^T \Delta x < 0\) si \(\nabla f_o(x) \neq 0\) (por ejemplo tómese \(\Delta x\) como \(-\nabla f_o(x)\) normalizado y suficientemente pequeño). Si \(\nabla f_o(x) = 0\) entonces \(x\) es un punto crítico y no existen direcciones de descenso.
Caso \(f_1\) activa en \(x\): \(f_1(x) = 0\), entonces \(x\) está en la frontera del círculo:
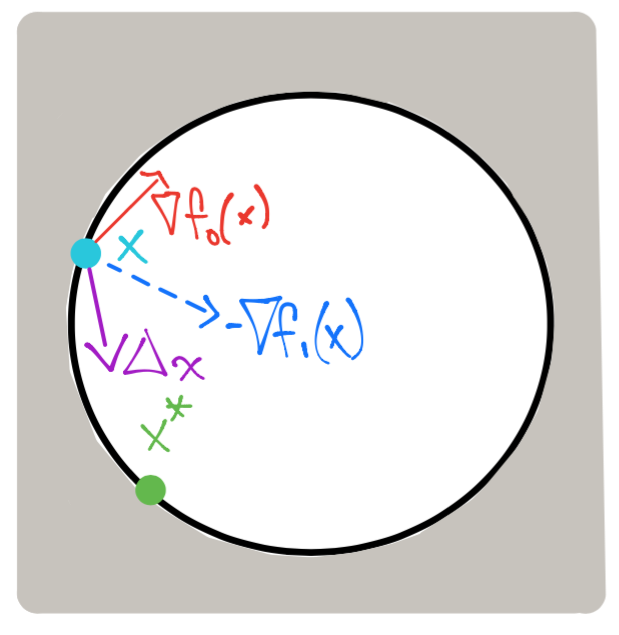
La condición que se debe satisfacer es:
la cual junto con la de descenso: \(\nabla f_o(x) ^T \Delta x < 0\) definen un semi-espacio cerrado y uno abierto respectivamente:
Si \(\nabla f_o(x)\) y \(\nabla f_1(x)\) son paralelos y apuntan en la misma dirección entonces la intersección entre estas dos regiones es vacía:
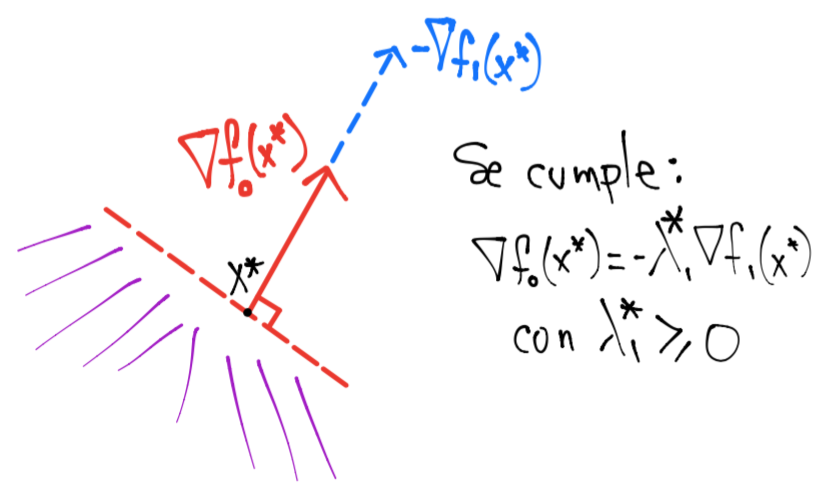
En este caso \(\nabla f_o(x)\) y \(\nabla f_1(x)\) cumplen: \(\nabla f_o(x) = -\lambda_1 \nabla f_1(x)\) para algún \(\lambda_1 \geq 0\). Tal condición se da si \(x\) es mínimo, esto es: \(x=x^*\).
En este caso el signo del multiplicador sí es importante pues si \(\nabla f_o(x) = -\lambda_1 \nabla f_1(x)\) con \(\lambda_1 \leq 0\) entonces \(\nabla f_o(x)\) y \(\nabla f_1(x)\) apuntarían en sentidos contrarios y por tanto el conjunto de direcciones que satisfacen:
construirían un semi-espacio abierto. Esto daría la posibilidad a tener una infinidad de direcciones de descenso:
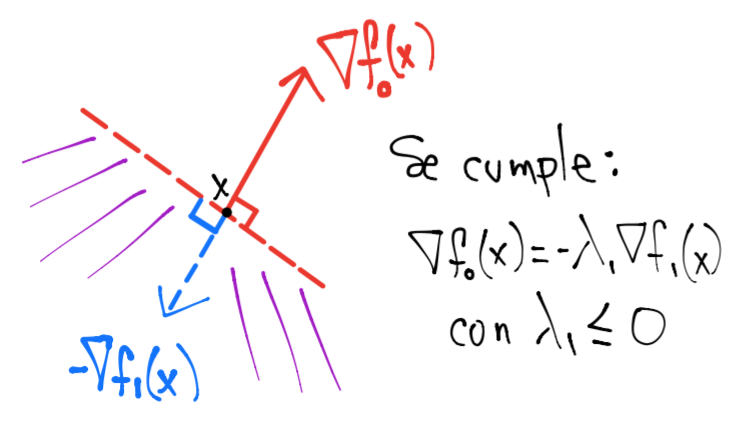
lo cual sería una contradicción si \(x\) es mínimo pues se tendría \(\nabla f_o(x) =0\) por condición necesaria de primer orden y no existiría \(\Delta x\) tal que es dirección de descenso (recuérdese que hemos asumido \(\nabla f_o(x) \neq 0\))
Ambas condiciones para los casos anteriores se pueden obtener a partir de la función Lagrangiana:
Si no existe \(\Delta x\) en un punto \(x^*\) entonces:
Y de acuerdo a los dos casos anteriores es importante el signo de \(\lambda_1^*\).
Además de la condición \(\lambda_1^* \geq 0\) requerimos la condición con nombre condición de complementariedad u holgura complementaria:
Así, para el caso en el que \(f_1\) es inactiva en \(x^*\) entonces por esta condición \(\lambda_1^* = 0\) y por tanto \(\nabla_x \mathcal{L}(x^*, \lambda_1^*) = \nabla f_o(x^*) = 0\). En el caso que \(f_1\) es activa en \(x^*\) entonces \(\lambda_1^*\) puede tomar cualquier valor en \(\mathbb{R}\) pero por los dos dibujos anteriores se debe cumplir que \(\lambda_1^* \geq 0\) para consistencia con que \(x^*\) es mínimo.
Comentario
La condición de holgura complementaria indica que si \(\lambda_1\) es positivo entonces \(f_1\) es activa:
o bien:
Ejemplo 3#
Para este ejemplo el conjunto de factibilidad es el interior de la mitad superior del círculo (incluyendo su frontera):
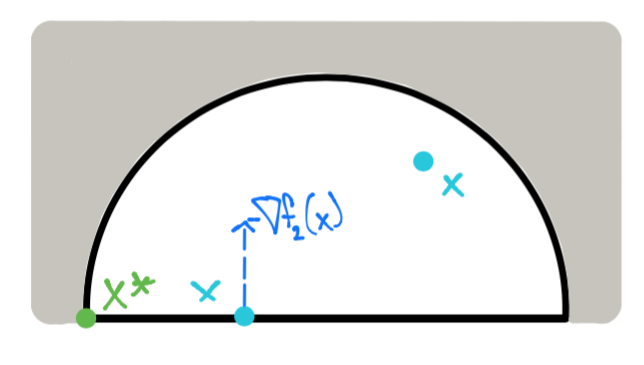
La solución para este ejemplo es \(x^* = \left [ \begin{array}{c}-\sqrt{2} \\ 0 \end{array} \right ]\), un punto en el que ambas restricciones \(f_1(x) = x_1^2 + x_2^2 -2\), \(f_2(x) = -x_2\) son activas.
Siguiendo con el desarrollo del ejemplo 2 de aproximación a primer orden con el teorema de Taylor se tiene que una dirección de descenso \(\Delta x\) debe cumplir (considerando restricciones activas \(f_1, f_2\)):
No existe tal dirección \(\Delta x\) en el mínimo \(x^* = \left [ \begin{array}{c}-\sqrt{2} \\ 0 \end{array} \right ]\):
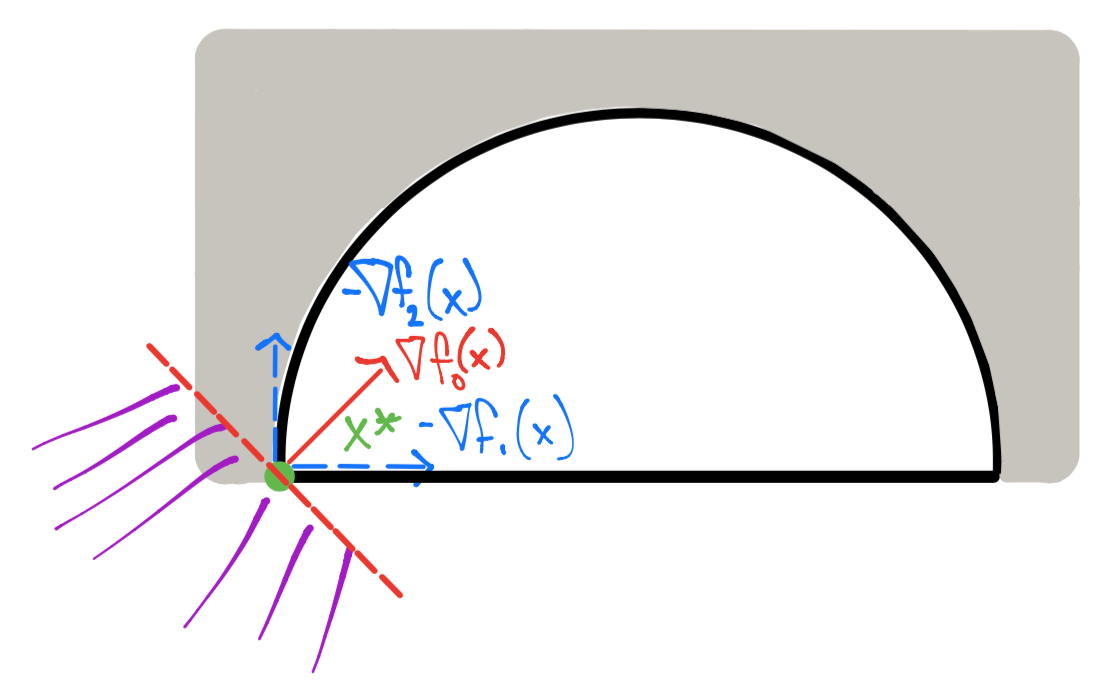
En este caso la función Lagrangiana es: \(\mathcal{L}(x, \lambda_1, \lambda_2) = f_o(x) + \lambda_1 f_1(x) + \lambda_2 f_2(x)\) y por el ejemplo 2 si no existe \(\Delta x\) en un punto \(x^*\) entonces:
considerando \(\lambda^*\) al vector de multiplicadores de Lagrange que contiene \(\lambda_1^*, \lambda_2^*\) y la última desigualdad se refiere a que \(\lambda_1^*, \lambda_2^* \geq 0\). Además la condición de holgura complementaria es:
Para el punto \(x^* = \left [ \begin{array}{c}-\sqrt{2} \\ 0 \end{array} \right ]\) se tiene:
Y con \(\lambda^* = \left [ \begin{array}{c} \frac{1}{2\sqrt{2}} \\ 1 \end{array} \right ]\) se cumple:
Por tanto \(x^*\) es mínimo local y no existe dirección de descenso \(\Delta x\).
Para un punto diferente a \(x^*\) por ejemplo \(x = \left [ \begin{array}{c}\sqrt{2} \\ 0 \end{array} \right ]\) ambas restricciones \(f_1\) y \(f_2\) son activas:
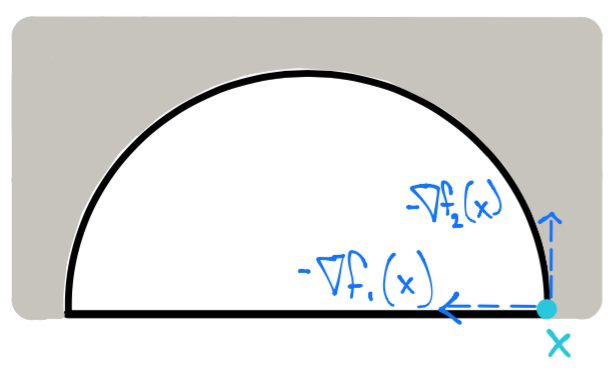
Y el vector \(\Delta x = \left [ \begin{array}{c}-1 \\ 0 \end{array} \right ]\) satisface las restricciones:
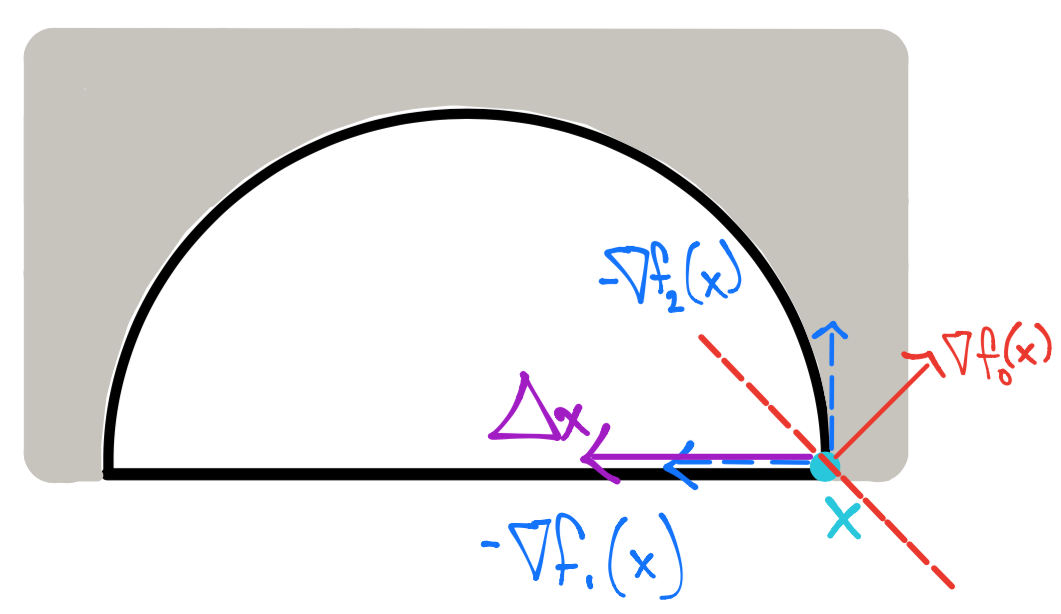
Revisando si tal punto satisface:
Si \(\lambda = \left [ \begin{array}{c}\frac{-1}{2\sqrt{2}} \\ 1 \end{array} \right ]\) entonces \(\nabla_x \mathcal{L}(x, \lambda) = 0\) pero \(\lambda_1 <0\).
Por lo tanto sí existe \(\Delta x\) de descenso y \(x\) no es mínimo.
Para un punto diferente a \(x^*\) en el interior del conjunto de factibilidad por ejemplo \(x = \left [ \begin{array}{c}1 \\ 0 \end{array} \right ]\) sólo la restricción \(f_2\) es activa:
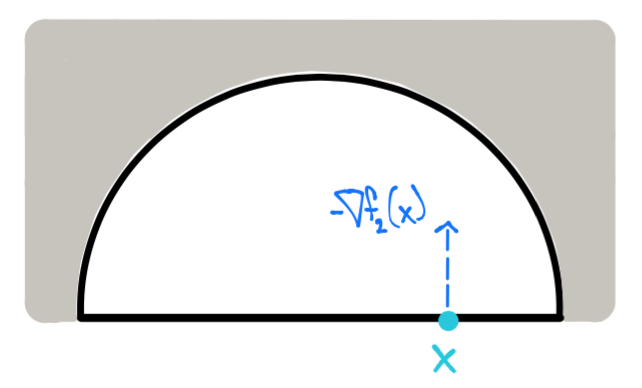
Dado que \(f_1\) sólo restringe a estar en el interior del círculo, el vector \(\Delta x\) en este caso debe cumplir con mantener la factibilidad dada por la restricción \(f_2\) que representa la parte superior del círculo (incluyendo la frontera). Una dirección \(\Delta x\) suficientemente pequeña cumplirá \(f_1\). Entonces \(\Delta x\) debe satisfacer:
para ser de descenso. El vector \(\Delta x = \left [ \begin{array}{c}-\frac{1}{2} \\ \frac{1}{4} \end{array} \right ]\) satisface lo anterior y por tanto es de descenso.
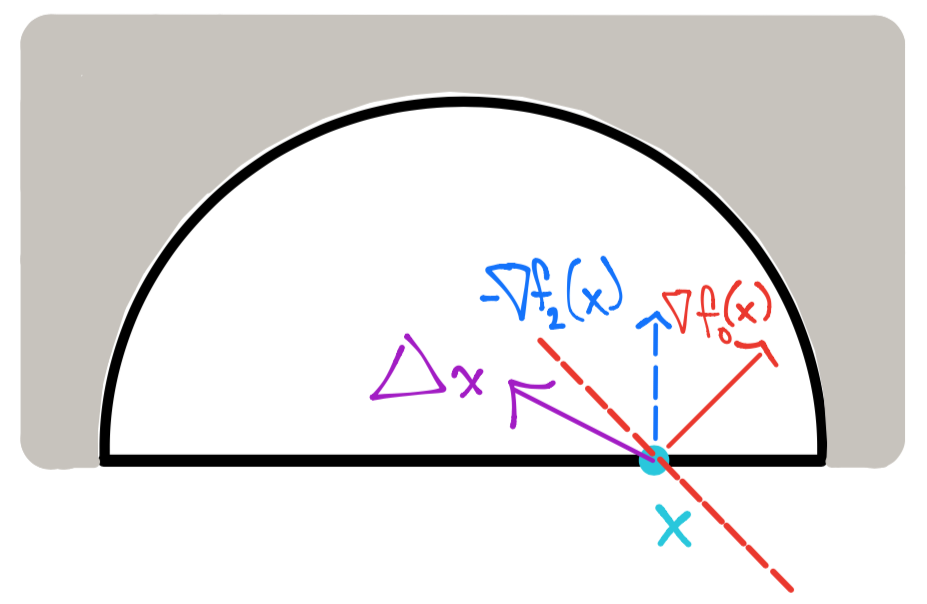
Revisando si tal punto satisface:
Para este punto como \(f_1\) es inactiva entonces \(\lambda_1 = 0\) por holgura complementaria. Si deseamos que \(\nabla_x \mathcal{L}(x, \lambda)=0\) entonces debemos encontrar \(\lambda\) tal que:
No existe \(\lambda_2\) y por tanto \(\lambda\) que satisfaga la ecuación anterior. Por lo tanto sí existe \(\Delta x\) de descenso y \(x\) no es mínimo.
Comentario
En resúmen de los 3 ejemplos anteriores: si \(x^*\) es una solución local del problema estándar de optimización entonces existen vectores multiplicadores de Lagrange \(\nu^*, \lambda^*\) para las restricciones de igualdad y desigualdad respectivamente tales que:
faltan considerar suposiciones importantes para tener completo el resultado pero los ejemplos anteriores abren camino hacia las condiciones de Karush-Kuhn-Tucker, aka KKT, de optimalidad.
Observación
Obsérvese que las condiciones KKT de optimalidad son condiciones necesarias e involucran información de primer orden.
Máquina de Soporte Vectorial (SVM) para datos linealmente separables, ejemplo de Constrained Inequality Convex Optimization (CICO):#
Clasificador lineal#
Considérese dos conjuntos de puntos en \(\mathbb{R}^n\) cuyos atributos o features están dados por \(\{x_1, x_2, \dots, x_N\}\), \(\{y_1, y_2, \dots, y_M\}\) y tales puntos tienen etiquetas \(\{-1, 1\}\) respectivamente.
El objetivo es encontrar una función \(f: \mathbb{R}^n \rightarrow \mathbb{R}\) que sea negativa en el primer conjunto de puntos y positiva en el segundo conjunto de puntos:
Si existe tal función entonces \(f\) o el conjunto \(\{x : f(x) = 0\}\) separa o clasifica los \(2\) conjuntos de puntos.
Observación
La clasificación puede ser débil que significa: \(f(x_i) \leq 0\), \(f(y_i) \geq 0\).
Para el caso en el que los datos son linealmente separables se busca una función afín de la forma \(f(x) = a^Tx - b\) que clasifique los puntos, esto es:
Geométricamente se busca un hiperplano de dimensión \(n-1\) que separe ambos conjuntos:
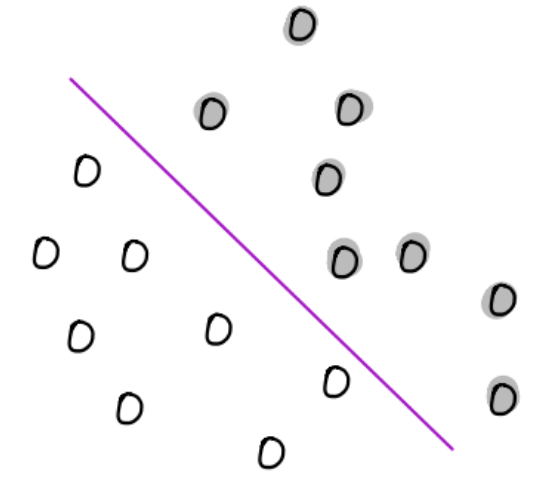
En el dibujo tómese los puntos sin rellenar como los pertenecientes a una clase de \(\{-1, 1\}\).
Si \(x, y\) son puntos en el hiperplano entonces \(f(x) = f(y) = 0\) y además \(a^T(x-y) = b - b = 0\), así \(a\) es ortogonal a todo punto en el hiperplano y determina la orientación de este:
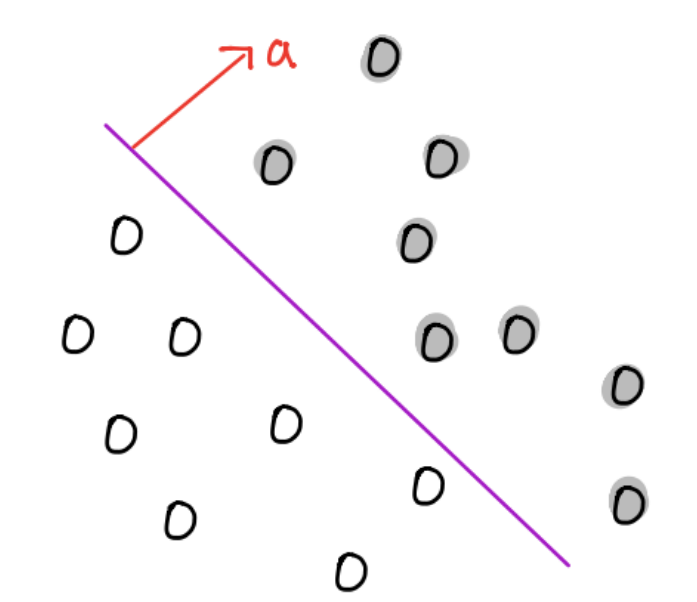
Si \(x\) es un punto en el hiperplano tenemos \(f(x) = 0\) por lo tanto la distancia perpendicular del origen al hiperplano está dada por: \(\frac{|a^Tx|}{||a||_2} = \frac{|b|}{||a||_2}\) y el parámetro \(b\) determina la localización del hiperplano:
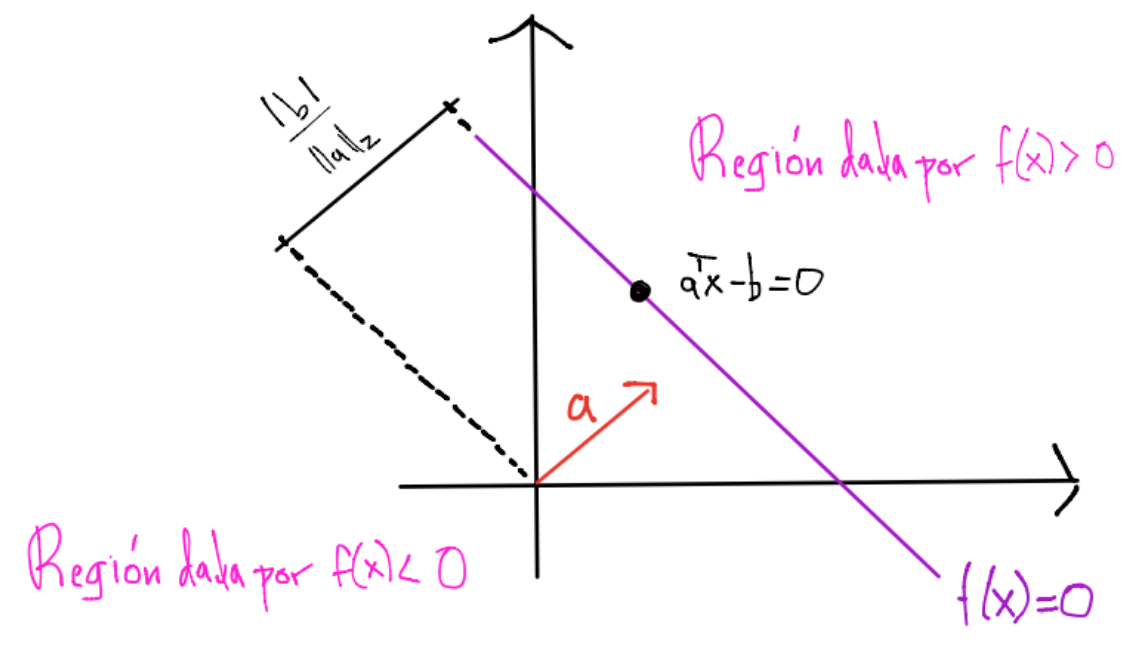
Sean \(x \in \mathbb{R}^n\) y \(x_{\perp} \in \mathbb{R}^n\) la proyección ortogonal en el hiperplano:
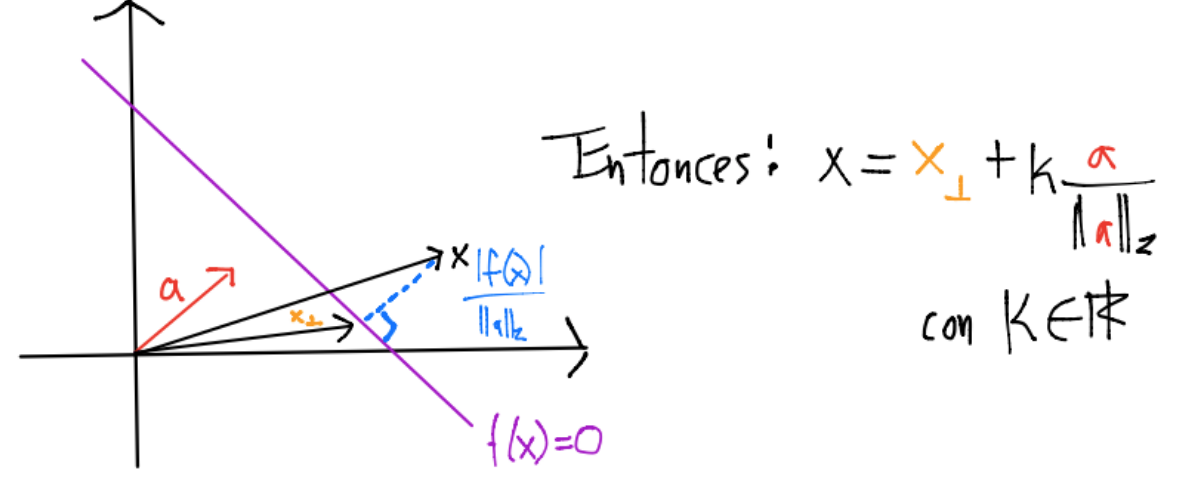
tenemos: \(a^Tx = a^Tx_{\perp} + k||a||_2 = b + k ||a||_2\) por lo que \(a^Tx - b = k||a||_2\) y:
esto es, \(|f(x)|\) da una medida de distancia perpendicular de \(x\) al hiperplano.
Modelo de SVM#
En este modelo se desea obtener:
Observación
El uso de \(\{-1, 1\}\) ayuda a la escritura y formulación matemática del modelo.
para clasificar a datos linealmente separables:

Obsérvese que existen una infinidad de hiperplanos que separan a los datos anteriores:
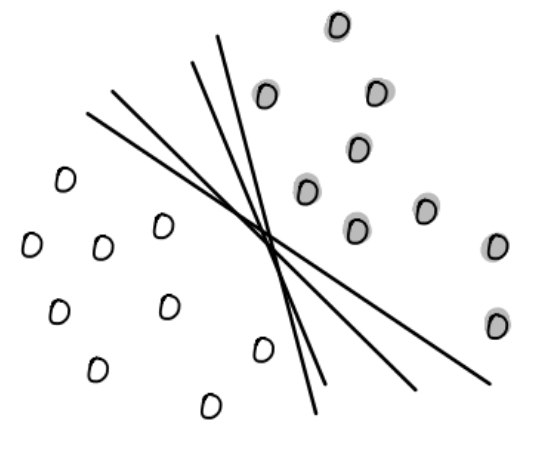
En la SVM buscamos un hiperplano que tenga la máxima separación de cada una de las distancias de los datos al mismo:
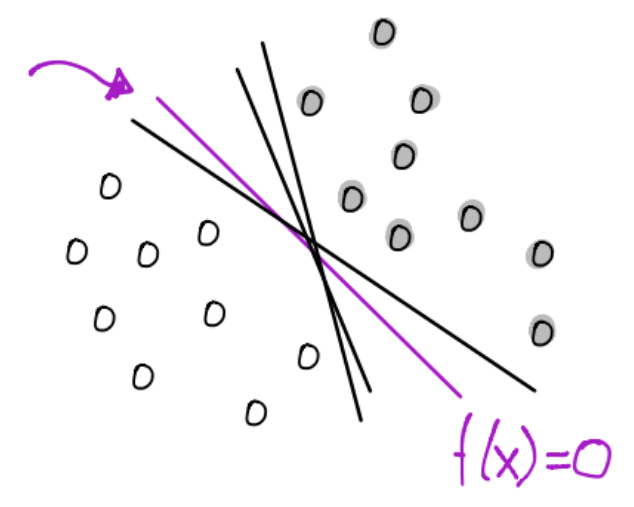
Una distancia al hiperplano para los datos \(x_i, \forall i=1, \dots, N\) y otra distancia para los datos \(y_i \forall i=1, \dots, M\).
Por la sección anterior, la distancia al hiperplano para cada conjunto de datos está dada por:
Entonces encontrar un hiperplano que tenga la máxima separación de cada una de las distancias de los datos al hiperplano se puede escribir como el problema:
Obsérvese que el cociente \(\frac{|f(x_i)|}{||a||_2}\) es invariante ante reescalamientos por ejemplo:
Por tanto, si los índices \(i_1, i_2\) cumplen:
se puede hacer un reescalamiento para obtener:
Esto es, \(|f(x_i)| \geq 1, \forall i=1, \dots, N\), \(|f(y_i)| \geq 1, \forall i=1, \dots, M\).
Problema de optimización en SVM#
El problema canónico o estándar de la máquina de soporte vectorial es:
El cual es equivalente a:
Comentarios
Se ha quitado el valor absoluto \(|f(x_i)|, |f(y_i)|\) pues \(x_i, y_i\) se asumen cumplen \(a^Tx_i-b \geq 1\), \(a^Ty_i-b \leq -1\), esto es, \(x_i, y_i\) son clasificados correctamente.
Este problema es de optimización convexa con restricciones de desigualdad.
Vectores de soporte#
Al encontrar este hiperplano tenemos otros dos hiperplanos paralelos ortogonales al vector \(a\) sin ningún dato entre ellos a una distancia de \(\frac{1}{||a||_2}\):
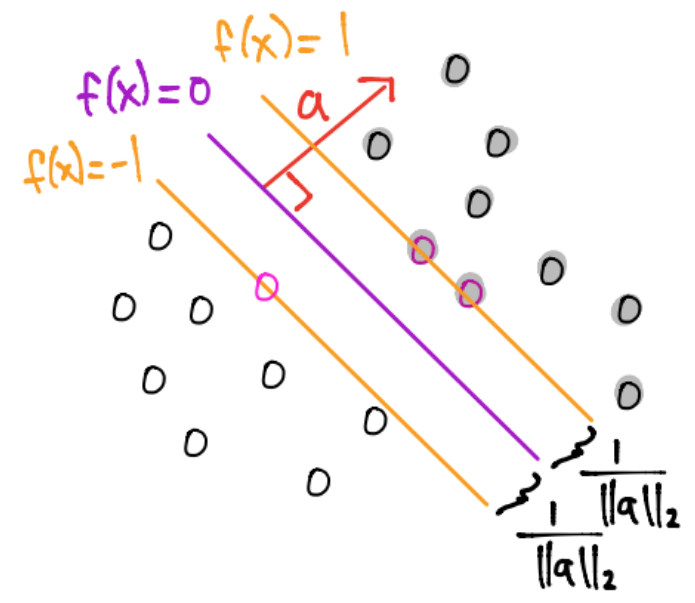
Definición
Aquellas restricciones activas son originadas por puntos con el nombre de vectores de soporte.
Comentarios
Al resolver el problema de optimización siempre existirán al menos \(2\) restricciones activas pues siempre hay una distancia mínima para cada conjunto de puntos.
Las otras dos rectas forman lo que se conoce como margen.
Ejemplo Iris dataset#
Utilizamos el conocido dataset de Iris en el que se muestran tres especies del género Iris. Las especies son: I. setosa, I. virginica y I. versicolor:
Imagen obtenida de Iris Dataset.
La clase \(\mathcal{C}_{-1}\) es setosa y \(\mathcal{C}_1\) es versicolor codificadas como \(-1, 1\) respectivamente.
data_iris_setosa_versicolor = data_iris[0:100].copy()
classes = iris["target"][0:100].copy()
print(classes)
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1]
classes[0:50] = classes[0:50].copy()-1
print(classes)
[-1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1
-1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1
-1 -1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1]
Estandarizamos la matriz de datos:
data_iris_setosa_versicolor = (data_iris_setosa_versicolor-
data_iris_setosa_versicolor.mean(axis=0))/data_iris_setosa_versicolor.std(axis=0)
Añadimos la columna que indica uso de intercepto:
m,n = data_iris_setosa_versicolor.shape
data_iris_setosa_versicolor = np.column_stack((-1*np.ones((m,1)), data_iris_setosa_versicolor))
print(data_iris_setosa_versicolor[0:10, 0:10])
[[-1. -0.58 0.84 -1.01 -1.04]
[-1. -0.89 -0.21 -1.01 -1.04]
[-1. -1.21 0.21 -1.08 -1.04]
[-1. -1.36 0. -0.94 -1.04]
[-1. -0.74 1.05 -1.01 -1.04]
[-1. -0.11 1.68 -0.8 -0.69]
[-1. -1.36 0.63 -1.01 -0.86]
[-1. -0.74 0.63 -0.94 -1.04]
[-1. -1.68 -0.42 -1.01 -1.04]
[-1. -0.89 0. -0.94 -1.22]]
Visualizamos para algunos atributos:
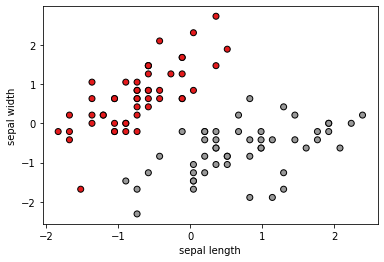
plt.scatter(data_iris_setosa_versicolor[:, 1],
data_iris_setosa_versicolor[:, 2], c=classes, cmap=plt.cm.Set1,
edgecolor='k')
plt.xlabel("sepal length")
plt.ylabel("sepal width")
plt.show()
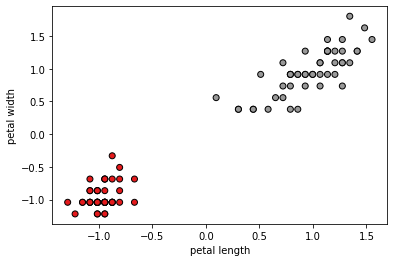
plt.scatter(data_iris_setosa_versicolor[:, 3],
data_iris_setosa_versicolor[:, 4], c=classes, cmap=plt.cm.Set1,
edgecolor='k')
plt.xlabel("petal length")
plt.ylabel("petal width")
plt.show()
Función objetivo:
y restricciones:
n = 5 #number of variables
vec = cp.Variable(n) #optimization variable
fo_cvxpy = 1/2*cp.norm(vec[1:n],2)**2 #fo just includes a not intercept
constraints = [data_iris_setosa_versicolor[0:50,:]@vec <=-1,
data_iris_setosa_versicolor[50:100,:]@vec >= 1]
obj = cp.Minimize(fo_cvxpy)
prob = cp.Problem(obj, constraints)
print(prob.solve())
0.6190278040023801
print("\nThe optimal value is", prob.value)
print("The optimal vector with intercept is")
print(vec.value)
The optimal value is 0.6190278040023801
The optimal vector with intercept is
[-0.24 0.27 -0.34 0.7 0.75]
Los primeros \(50\) renglones pertenecen a la clase \(\mathcal{C}_{-1}:\) I. setosa y los restantes \(50\) renglones pertenecen a la clase \(\mathcal{C}_{1}\): I. versicolor. Se clasifica de acuerdo al signo de: \(a^Tx - b\):
print(np.sign(data_iris_setosa_versicolor[0:50,:]@vec.value))
[-1. -1. -1. -1. -1. -1. -1. -1. -1. -1. -1. -1. -1. -1. -1. -1. -1. -1.
-1. -1. -1. -1. -1. -1. -1. -1. -1. -1. -1. -1. -1. -1. -1. -1. -1. -1.
-1. -1. -1. -1. -1. -1. -1. -1. -1. -1. -1. -1. -1. -1.]
print(np.sign(data_iris_setosa_versicolor[50:100,:]@vec.value))
[1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1.
1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1.
1. 1.]
Visualización utilizando únicamente Sepal.Length y Sepal.Width:
x_min = np.min(data_iris_setosa_versicolor[:,1])
x_max = np.max(data_iris_setosa_versicolor[:,1])
y_min = np.min(data_iris_setosa_versicolor[:,2])
y_max = np.max(data_iris_setosa_versicolor[:,2])
x_plot = np.linspace(x_min, x_max, 100)
b, a = vec.value[0], vec.value[1:n]
y_plot = 1/a[1]*(-a[0]*x_plot + b)
y_plot_minus_1 = 1/a[1]*(-a[0]*x_plot + b -1)
y_plot_plus_1 = 1/a[1]*(-a[0]*x_plot + b + 1)
plt.scatter(data_iris_setosa_versicolor[:, 1],
data_iris_setosa_versicolor[:, 2], c=classes, cmap=plt.cm.Set1,
edgecolor='k')
plt.plot(x_plot,y_plot,'b',
x_plot,y_plot_minus_1, 'm',
x_plot, y_plot_plus_1,'r')
plt.xlabel("sepal length")
plt.ylabel("sepal width")
plt.show()
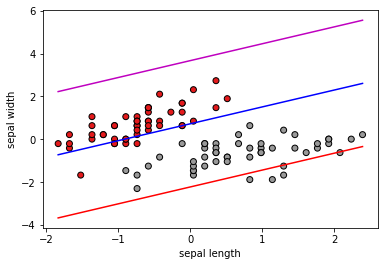
Visualización utilizando únicamente Petal.Length y Petal.Width:
x_min = np.min(data_iris_setosa_versicolor[:,3])
x_max = np.max(data_iris_setosa_versicolor[:,3])
y_min = np.min(data_iris_setosa_versicolor[:,4])
y_max = np.max(data_iris_setosa_versicolor[:,4])
x_plot = np.linspace(x_min, x_max, 100)
y_plot = 1/a[3]*(-a[2]*x_plot + b)
y_plot_minus_1 = 1/a[3]*(-a[2]*x_plot + b -1)
y_plot_plus_1 = 1/a[3]*(-a[2]*x_plot + b + 1)
plt.scatter(data_iris_setosa_versicolor[:, 3],
data_iris_setosa_versicolor[:, 4], c=classes, cmap=plt.cm.Set1,
edgecolor='k')
plt.plot(x_plot,y_plot,'b',
x_plot,y_plot_minus_1, 'm',
x_plot, y_plot_plus_1,'r')
plt.xlabel("petal length")
plt.ylabel("petal width")
plt.show()
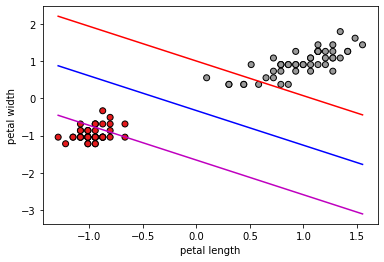
Ejercicio
Realiza la clasificación anterior para las clases virginica y versicolor.
Ajustando el modelo de la SVM sólo para dos atributos: Sepal.Length y Sepal.Width:#
data_iris_setosa_versicolor = data_iris[0:100, 0:2].copy()
Aquí no estandarizamos.
data_iris_setosa_versicolor = np.column_stack((-1*np.ones((m,1)), data_iris_setosa_versicolor))
n = 3 #number of variables
vec = cp.Variable(n) #optimization variable
fo_cvxpy = 1/2*cp.norm(vec[1:n],2)**2 #fo just includes a not intercept
constraints = [data_iris_setosa_versicolor[0:50,:]@vec <=-1,
data_iris_setosa_versicolor[50:100,:]@vec >= 1]
obj = cp.Minimize(fo_cvxpy)
prob = cp.Problem(obj, constraints)
print(prob.solve())
33.79501292632983
print("\nThe optimal value is", prob.value)
print("The optimal vector with intercept is")
print(vec.value)
The optimal value is 33.79501292632983
The optimal vector with intercept is
[17.32 6.32 -5.26]
print(np.sign(data_iris_setosa_versicolor[0:50,:]@vec.value))
[-1. -1. -1. -1. -1. -1. -1. -1. -1. -1. -1. -1. -1. -1. -1. -1. -1. -1.
-1. -1. -1. -1. -1. -1. -1. -1. -1. -1. -1. -1. -1. -1. -1. -1. -1. -1.
-1. -1. -1. -1. -1. -1. -1. -1. -1. -1. -1. -1. -1. -1.]
print(np.sign(data_iris_setosa_versicolor[50:100,:]@vec.value))
[1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1.
1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1.
1. 1.]
b, a = vec.value[0], vec.value[1:n]
print(b)
17.315789240731355
print(a)
[ 6.32 -5.26]
x_min = np.min(data_iris_setosa_versicolor[:,1])
x_max = np.max(data_iris_setosa_versicolor[:,1])
y_min = np.min(data_iris_setosa_versicolor[:,2])
y_max = np.max(data_iris_setosa_versicolor[:,2])
x_plot = np.linspace(x_min, x_max, 100)
y_plot = 1/a[1]*(-a[0]*x_plot + b)
y_plot_minus_1 = 1/a[1]*(-a[0]*x_plot + b -1)
y_plot_plus_1 = 1/a[1]*(-a[0]*x_plot + b + 1)
plt.scatter(data_iris_setosa_versicolor[:, 1],
data_iris_setosa_versicolor[:, 2], c=classes, cmap=plt.cm.Set1,
edgecolor='k')
plt.plot(x_plot,y_plot,'b',
x_plot,y_plot_minus_1, 'm',
x_plot, y_plot_plus_1,'r')
plt.legend(["$17.32 + 6.32x_1 -5.26x_2=0$",
"$17.32 + 6.32x_1 -5.26x_2=-1$",
"$17.32 + 6.32x_1 -5.26x_2=1$"])
plt.xlabel("sepal length")
plt.ylabel("sepal width")
plt.show()
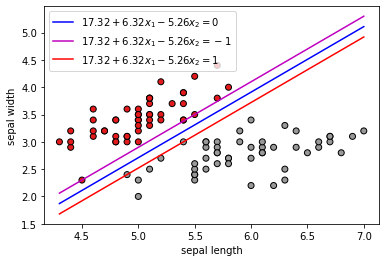
Ejercicio
Determina para este ajuste los vectores de soporte y márcalos en la gráfica.
Realiza el ajuste para los atributos
Petal.Length,Petal.Widthestandarizando la matriz de datos para las mismas clases y la visualización de los datos con la recta que separa y las rectas que forman al margen.¿Es necesario estandarizar si se usan dos atributos para este dataset? realiza el ajuste del ejercicio 2 anterior sin estandarizar la matriz de datos para las mismas clases y la visualización de los datos con la recta que separa y las rectas que forman al margen.
Problemas de programación lineal, ejemplo de CIEO:#
Una gran cantidad de aplicaciones utilizan formulaciones de problemas de programación lineal que involucran igualdades y desigualdades cuya forma estándar está dada por:
donde: \(A \in \mathbb{R}^{m \times n}\) y se asume \(m \leq n\) y tiene rank completo por renglones y la última desigualdad se refiere a que todas las componentes del vector \(x\) son mayores o iguales a cero.
Observación
Obsérvese que la función objetivo \(f_o(x) = c^Tx\) y tanto las restricciones de igualdad como desigualdad son funciones lineales.
Ejemplo: problema de transporte#
La compañía “Brazilian coffee” procesa granos de café en \(m\) plantas de café. El café posteriormente es enviado cada semana a \(n\) almacenes para su retail, distribución y exportación. Supóngase que el costo unitario de envío de la planta \(i\) al almacén \(j\) es \(c_{ij}\). También supóngase que la capacidad de producción en la planta \(i\) es \(a_i\) y que la demanda en el almacén \(j\) es \(b_j\).
Se desea encontrar la cantidad de unidades \(x_{ij}\) de café que serán transportadas de la planta \(i\) al almacén \(j\), \(i=1,\dots, m\), \(j=1, \dots, n\) que minimice el costo total de envío.
Este problema es de programación lineal modelado como:
Introducción a los métodos de puntos interiores#
En los \(80\)’s se descubrió que muchos problemas lineales large scale podían ser resueltos eficientemente utilizando formulaciones y algoritmos de programación no lineal y de ecuaciones no lineales. Una característica de tales métodos era que requerían que todas las iteraciones satisfacieran las restricciones de desigualdad de forma estricta por lo que se les nombró como puntos interiores. A inicios de los \(90\)’s una subclase de métodos de puntos interiores conocidos con el nombre de primal-dual se distinguieron como las metodologías más eficientes en la práctica y probaron ser fuertes compeditores con el método símplex para resolver problemas de programación lineal large scale.
El método símplex resuelve programas lineales utilizando la idea geométrica de probar una secuencia de vértices hasta encontrar el óptimo en la frontera del conjunto factible:
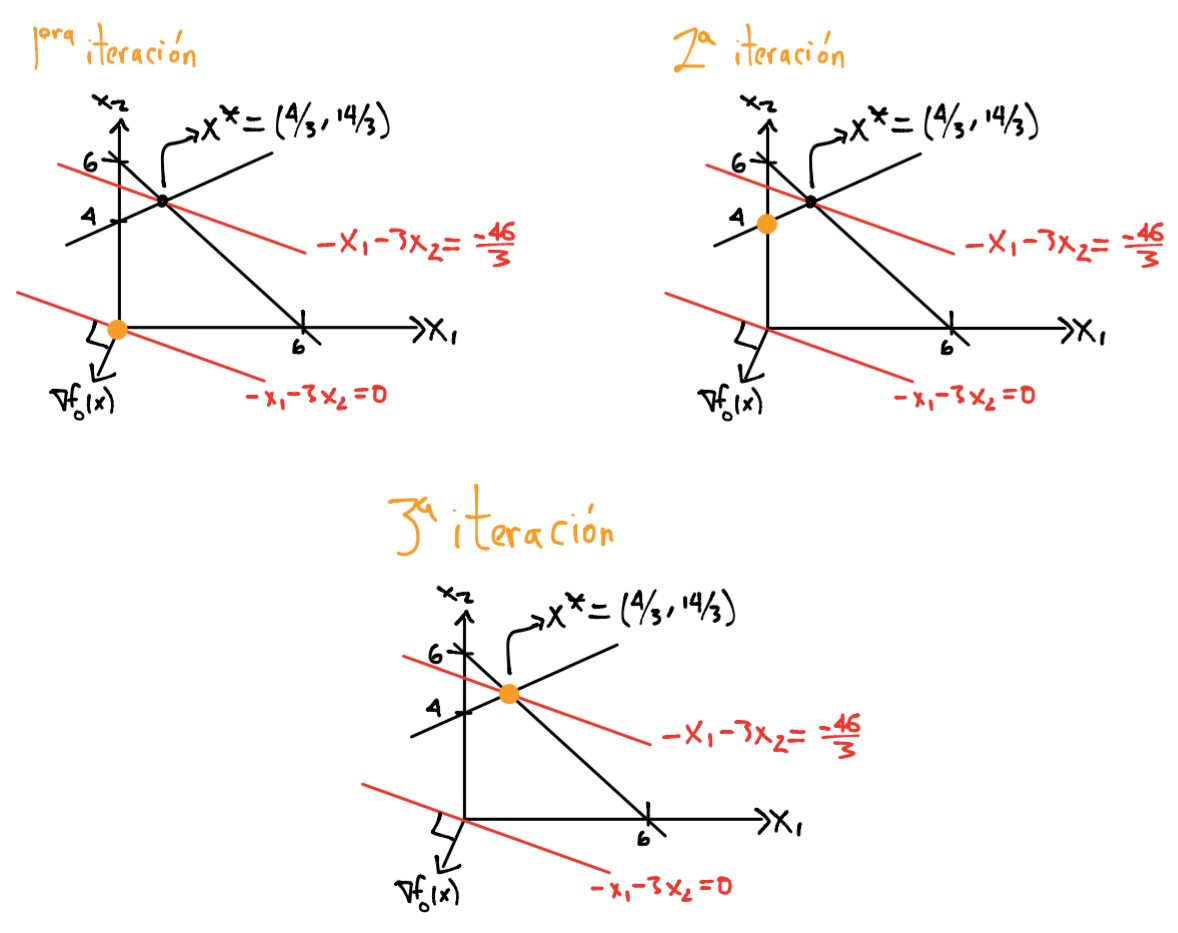
Los métodos de puntos interiores se aproximan a la frontera del conjunto de factibilidad únicamente en el límite. Pueden aproximarse por el interior o exterior del conjunto de factibilidad pero nunca caen en la frontera del mismo:
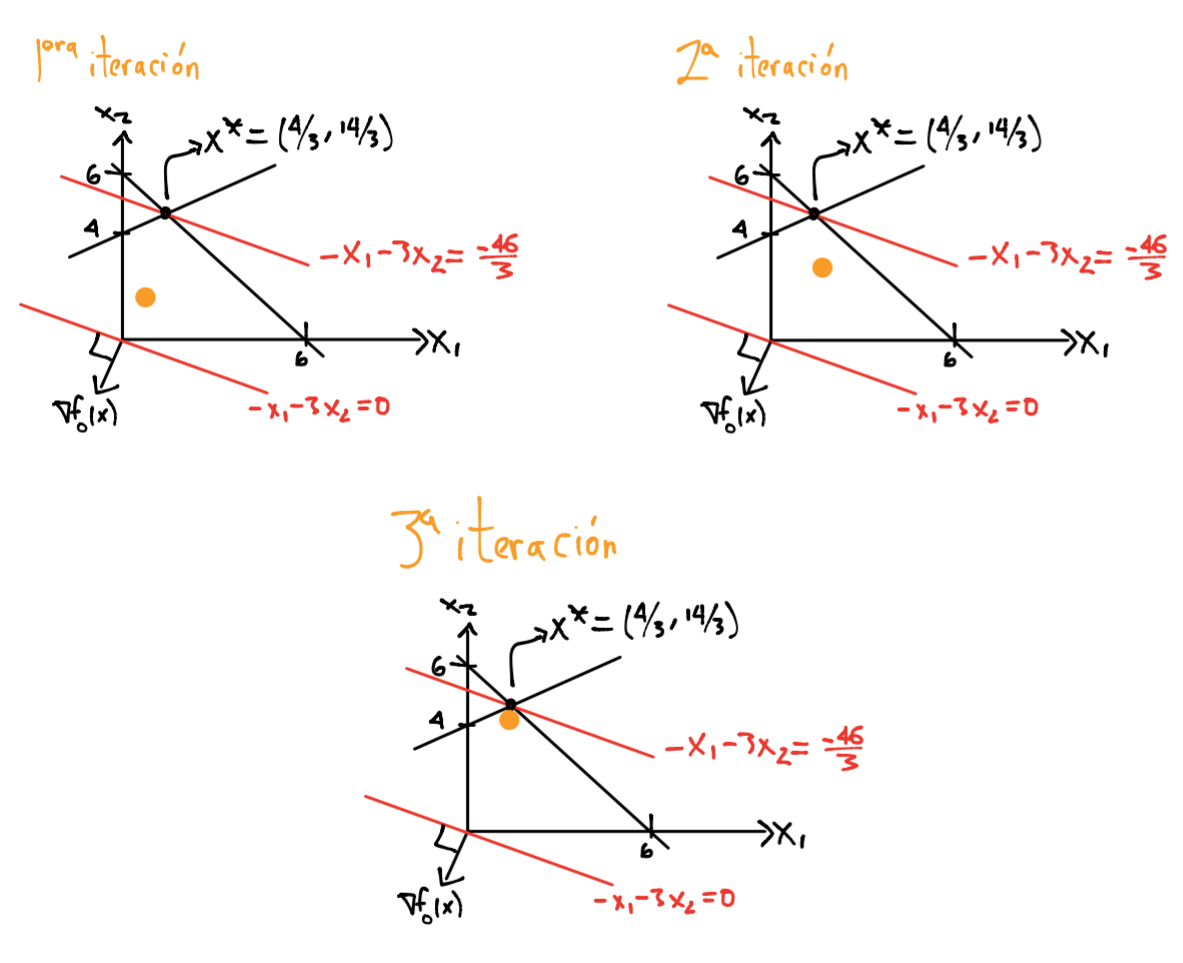
Introducción al método primal-dual#
Considérese el problema de programación lineal en su forma estándar:
donde: \(A \in \mathbb{R}^{m \times n}\) y se asume \(m \leq n\) y tiene rank completo por renglones y la última desigualdad se refiere a que todas las componentes del vector \(x\) son mayores o iguales a cero. Por el desarrollo en introducción a CIEO, las soluciones del problema anterior están caracterizadas por las condiciones KKT:
donde: las últimas dos desigualdades se refieren que todas las componentes de los vectores son mayores o iguales a cero.
Los métodos de la clase primal-dual encuentran soluciones \((x^*, \lambda^*, \nu^*)\) para las igualdades anteriores y modifican las direcciones de búsqueda y tamaños de paso para que las desigualdades se satisfagan de forma estricta en cada iteración.
La idea de los métodos de la clase primal-dual es reescribir las condiciones KKT de optimalidad anteriores mediante una función \(F: \mathbb{R}^{2n + m} \rightarrow \mathbb{R}^{2n+m}\) dada por:
y resolver la ecuación no lineal \(F(x, \lambda, \nu )=0\) para \((x, \lambda) \geq 0\), donde: \(X = \text{diag}(x_1, \dots, x_n)\), \(\Lambda = \text{diag}(\lambda_1, \dots, \lambda_n)\) y \(e\) es un vector de \(1\)’s en \(\mathbb{R}^n\).
Los métodos de la clase primal-dual producen iteraciones \((x^{(k)}, \lambda^{(k)}, \nu^{(k)})\) tales que \(x^{(k)} > 0\) y \(\lambda^{(k)} > 0\), por esto tales métodos son considerados como puntos interiores.
Software para resolver problemas CIEO#
Como ejemplo de funciones, paquetes y sistemas para resolver problemas tipo constrained inequality and equality optimization se encuentran:
Ejercicios
1.Resuelve los ejercicios y preguntas de la nota.
Referencias:
S. P. Boyd, L. Vandenberghe, Convex Optimization, Cambridge University Press, 2009.
J. Dennis, R. B. Schnabel, Numerical Methods for Unconstrained Optimization and Nonlinear Equations, SIAM, 1996.
M. S. Bazaraa, J. J. Jarvis, H. D. Sherali, Linear Programming and Network Flows, Wiley, 2010.
J. Nocedal, S. J. Wright, Numerical Optimization, Springer, 2006.