1.2 Sistema de punto flotante
Contents
1.2 Sistema de punto flotante#
Notas para contenedor de docker:
Comando de docker para ejecución de la nota de forma local:
nota: cambiar <ruta a mi directorio> por la ruta de directorio que se desea mapear a /datos dentro del contenedor de docker y <versión imagen de docker> por la versión más actualizada que se presenta en la documentación.
docker run --rm -v <ruta a mi directorio>:/datos --name jupyterlab_optimizacion -p 8888:8888 -d palmoreck/jupyterlab_optimizacion:<versión imagen de docker>
password para jupyterlab: qwerty
Detener el contenedor de docker:
docker stop jupyterlab_optimizacion
Documentación de la imagen de docker palmoreck/jupyterlab_optimizacion:<versión imagen de docker> en liga.
Nota generada a partir de liga
Al final de esta nota la comunidad lectora:
Relacionará el error por redondeo revisado en la nota de análisis numérico y cómputo científico con el uso de recursos finitos en la máquina.
Comprenderá el por qué la máquina tiene errores en el cálculo de las aproximaciones. En específico conocer cómo se representan a los números reales en la máquina es muy importante.
Aprenderá los componentes de un sistema de punto flotante. En específico la precisión es muy importante.
Aprenderá la interpretación de un error relativo y cómo relacionarlo con la precisión de un sistema de punto flotante.
Aprenderá algunas operaciones que tienen un alto error por redondeo en la aritmética de máquina.
Representación de los números en la computadora#
Las computadoras utilizan una determinada cantidad de cifras de un número real para realizar operaciones. Además, utilizan una representación de los números en bases no usadas por las personas para realizar cálculos comunes, ejemplos son la 2, 8 o 16. En contraste, la mayoría de las personas utilizamos la base 10 para representar a los números y realizar cálculos.
A continuación se muestran construcciones que se han hecho para representar los números en una computadora.
Enteros#
Tenemos distintos métodos para la representación de los enteros en una computadora, pero uno que es más utilizado es el de “magnitud con signo” en el que se utiliza un bit para el signo del número y los bits restantes para almacenar al número. El primer bit se le da el valor de \(0\) para codificar al signo + y el valor \(1\) codifica al bit -. Entonces el número \(-173\) se almacena con la cadena de \(16\) bits:
1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
0 |
1 |
0 |
1 |
1 |
0 |
1 |
Utilizamos la notación posicional para convertir este número binario a base 10: el primer bit es \(1\) por lo que se tiene un signo negativo. Luego:
//%cflags:-lm
#include<stdio.h>
#include<math.h>
int main(){
printf("suma: %f",pow(2,7)+pow(2,5)+pow(2,3)+pow(2,2)+pow(2,0));
return 0;
}
suma: 173.000000
Ejercicio
Determina el rango de enteros de base \(10\) que puede representarse en una computadora de \(16\) bits utilizando el primer bit para el signo
Reales#
Dadas las limitaciones en el almacenamiento de una computadora (hardware), sólo se representa un subconjunto de los números reales en ella, tal conjunto se denota como \(\mathcal{F}\mathcal{l}\) y contiene números racionales:
Sistema de punto flotante (SPF)#
En un sistema de punto flotante se define:
Rango de un exponente definido por un límite inferior y uno superior.
Base del sistema.
Precisión.
Así, un número \(x\) en el SPF, \(x \in \mathcal{F}\mathcal{l}\), se representa de la forma:
donde:
\(n\) es el exponente, \(n \in [L,U] \cap \mathbb{Z}\) con \(L, U\) fijos.
\(k\) es la precisión.
\(\beta\) es la base.
\(d_i \in \{0,1,\dots,\beta-1\} \forall i=1,\dots,k\) son los dígitos.
Definición
A la parte \(\pm 0.d_1d_2 \dots d_k\) se le nombra mantisa. A la porción \(d_2 \dots d_k\) se le nombra fracción \(f\).
Los números reales que tienen una representación exacta en el \(\mathcal{F}\mathcal{l}\) se les conoce como números de máquina.
Ejemplo#
Supóngase un \(\mathcal{F}\mathcal{l}\) con \(\beta = 10, k=4, n\in[-4,3]\cap \mathbb{Z}\) entonces:
pero:
por lo que \(0.333 \times 10^{-1} , 0.3300 \times 10^{3}\) son números de máquina.
SPFN#
Un Sistema de Punto Flotante Normalizado es aquel que cumple:
para números distintos de cero.
Observación
El número cero es el único que tiene dígitos de la mantisa y exponente iguales a cero.
Ejemplo#
\(\beta = 10, k=3\), rango del exponente en \([-3,3] \cap \mathbb{Z}\), entonces algunos números en el SPFN:
Notación de punto flotante |
Mantisa |
Exponente |
Valor de punto fijo |
|---|---|---|---|
\(0.153\times10^0\) |
\(0.153\) |
\(0\) |
\(0.153\) |
\(-0.990\times10^2\) |
\(-0.990\) |
\(2\) |
\(-99.0\) |
\(0.343\times10^{-3}\) |
\(0.343\) |
\(-3\) |
\(0.000343\) |
Ejemplo#
En un SPFN con \(\beta=2, k=3\), rango del exponente en \([0,2] \cap \mathbb{Z}\) se tiene:
a) El número más grande positivo que es posible representar es:
b) El más chico positivo es:
Observación
En un SPFN con \(\beta=2\) no es necesario almacenar el primer bit pues siempre es \(1\) por lo que sólo se almacenará la parte fraccionaria de la forma \(1.f\) (más sobre esto en la siguiente sección).
SPF de doble precisión#
Un SPF de doble precisión utiliza 64 bits para representar un número real. El primero es un indicador de signo denotado por \(s\). Le siguen \(11\) bits para construir al exponente \(n\) y \(52\) bits que construyen a la parte fraccionaria \(f\) de la mantisa. La base es \(\beta=2\).
Si es SPFN entonces aunque se tienen 52 bits, éstos se utilizan para almacenar un dígito más del número (ver observación anterior). Así, en un SPF en general maneja 52 (o 53 por la observación anterior) dígitos binarios, que corresponden a aproximadamente 15 (o 16) dígitos decimales. Ver: Double-precision floating-point format.
//%cflags:-lm
#include<stdio.h>
#include<math.h>
int main(){
printf("52 bits corresponden aproximadamente a: %f dígitos decimales\n", log10(pow(2,52)));
printf("53 bits corresponden aproximadamente a: %f dígitos decimales\n", log10(pow(2,53)));
return 0;
}
52 bits corresponden aproximadamente a: 15.653560 dígitos decimales
53 bits corresponden aproximadamente a: 15.954590 dígitos decimales
Los 11 bits que se utilizan para construir al exponente producen un rango de \(0\) a \(2^{11}-1=2047:\)
//%cflags:-lm
#include<stdio.h>
#include<math.h>
int main(){
int sum = 0;
int n=10;
int i;
for(i=0;i<=n;i++)
sum+=pow(2,i);
printf("Suma de 2^0 + 2^1 + ... + 2^10: %d", sum);
return 0;
}
Suma de 2^0 + 2^1 + ... + 2^10: 2047
pero esto construye un exponente con signo positivo, por lo que se resta (offset) la cantidad de \(-1023\) y se tiene el rango del exponente en \([-1023,1024] \cap \mathbb{Z}\):
Y un valor de \(n=1023\) representa un exponente de \(0\).
Los valores \(-1023\) (todos los bits iguales a \(0\)) y \(1024\) (todos los bits iguales a \(1\)) para el exponente se reservan para números especiales. Por esto, el exponente corre en el rango de \([-1022, 1023] \cap \mathbb{Z}\).
Todos los bits iguales a 0 para el exponente se utiliza para representar al número 0 con signo (si su fracción \(f\) es \(0\)) y a los números subnormales (si su fracción \(f\) es \(\neq0\)). Todos los bits iguales a 1 se utiliza para representar \(\infty\) (si su fracción \(f\) es \(0\)) y NaNs (si su fracción \(f\) \(\neq 0\)).
Entonces un número de máquina binario en un SPFN se representa por:
Y los subnormales como:
Observación
Obsérvese que aunque el exponente para los números subnormales se describió que tiene bits iguales a \(0\) se toma una \(n=1\) para finalmente tener el exponente \(n-1023 = 1-1023 = -1022\). Esto se realiza para tener un gradual underflow, ver Denormal_number. Si se tomara de forma estricta \(n=0\) (bits iguales a \(0\)) y por tanto un exponente \(n-1023=-1023\) habría un hueco entre el número positivo más pequeño normalizado y el más grande positivo subnormal:
respectivamente. Lo anterior extraído de Double precision examples.
Comentario
Hay dos representaciones para el \(0\), una con signo positivo (\(s=0, n=0, f=0\)) y otra con signo negativo (\(s=1,n=0,f=0\)).
Ejemplo#
El valor del exponente más chico para los números normales es: \(2^{1-1023} = 2^{-1022}\).
El valor del exponente más grande es: \(2^{2046-1023} = 2^{1023}\).
Ejemplo#
Considérese el número formado por:
primer bit: \(0\).
bits del exponente: \(10000000011\).
bits de la mantisa: \(1011100100010\dots0\).
Entonces:
1.El número es positivo pues \(s=0\): \((-1)^s = 1\).
2.Los bits del exponente generan al número decimal:
por lo que el exponente es \(4\): \(2^{1027-1023}=2^4\).
3.Los bits de la mantisa generan al número decimal:
//%cflags:-lm
#include<stdio.h>
#include<math.h>
int main(){
printf("Suma de 2^-1 + 2^-3 + 2^-4+2^-5+2^-8+2^-12: %f", pow(2,-1)+pow(2,-3)+pow(2,-4)+pow(2,-5)+pow(2,-8)+pow(2,-12));
return 0;
}
Suma de 2^-1 + 2^-3 + 2^-4+2^-5+2^-8+2^-12: 0.722900
Entonces el número de máquina binario \(0\) \(10000000011\) \(1011100100010\dots0\) es el número decimal:
//%cflags:-lm
#include<stdio.h>
#include<math.h>
int main(){
printf("2^4(1.7229): %f",pow(2,4)*1.7229);
return 0;
}
2^4(1.7229): 27.566400
Valores interesantes en un SPFN de doble precisión#
El número de máquina más grande positivo normalizado es:
#include<stdio.h>
#include<float.h>
int main(){
printf("Numéro más grande positivo: %e\n", DBL_MAX);
return 0;
}
Numéro más grande positivo: 1.797693e+308
Números que rebasen este límite superior resultan en un overflow:
//%cflags:-lm
#include<stdio.h>
#include<float.h>
#include<math.h>
int main(){
printf("overflow: %e\n", DBL_MAX + 0.0000000000000001*pow(10,308));
return 0;
}
overflow: inf
Comentario
Un resultado que puede verificarse de forma teórica es que el nivel de overflow es: \(\beta^{U+1}(1 - \beta^{-k})\).
Ejercicio
Utilizando lenguajes de programación da más ejemplos de ejecuciones como la anterior que resulten en overflow.
El número de máquina normalizado más pequeño positivo es:
#include<stdio.h>
#include<float.h>
int main(){
printf("Numéro normalizado más chico positivo: %e\n", DBL_MIN);
return 0;
}
Numéro normalizado más chico positivo: 2.225074e-308
Comentario
Un resultado que puede verificarse de forma teórica es que el número de máquina normalizado más pequeño positivo es: \(\beta^L\).
El número de máquina no normalizado, denormalizado o subnormalizado más chico positivo es del orden de
//%cflags:-lm
#include<stdio.h>
#include<float.h>
#include<math.h>
int main(){
printf("Numéro más chico positivo: %e\n", pow(2,-52)*DBL_MIN);
return 0;
}
Numéro más chico positivo: 4.940656e-324
Números con magnitud más chica que el valor anterior resultan en un underflow:
//%cflags:-lm
#include<stdio.h>
#include<float.h>
#include<math.h>
int main(){
printf("Underflow: %e\n",(1-.5)*pow(2,-52)*DBL_MIN);
return 0;
}
Underflow: 0.000000e+00
Ejercicio
Utilizando lenguajes de programación da más ejemplos de ejecuciones como la anterior que resulten en underflow.
Epsilon de la máquina \(\epsilon_{maq}\)#
//%cflags:-lm
#include<stdio.h>
#include<float.h>
#include<math.h>
int main(){
printf("Epsilon de la máquina equivale aproximadamente a 2^(-53): %e\n", DBL_EPSILON/2);
return 0;
}
Epsilon de la máquina equivale aproximadamente a 2^(-53): 1.110223e-16
El valor anterior representa el máximo error relativo en la representación de un número real en su número de máquina. Como se observa en la ejecución anterior \(\epsilon_{maq} = 2^{-53} \approx 1.11 \times 10 ^{-16}\) por lo que tenemos alrededor de \(15\) o \(16\) dígitos de precisión para un número real en el SPFN de doble precisión.
Fórmulas para calcular errores absolutos y relativos#
Definición
Si aprox es mi cantidad con la que aproximo a mi objetivo obj entonces el error absoluto de aprox y el error relativo de aprox es:
En la definición anterior de error relativo se asume obj es diferente de \(0\).
Si \(ErrRel(aprox) \approx 10^{-k}\) se dice que aprox aproxima a obj con alrededor de \(k\) dígitos correctos.
Si obj es un vector entonces los errores absolutos y relativos se calculan con las normas cuya definición se revisa en la nota 1.3 Normas vectoriales y matriciales, por ejemplo para el error relativo de aprox:
Comentarios
Otras definiciones para \(\epsilon_{maq}\) son:
\(\epsilon_{maq}\) es el número más chico positivo tal que: \(1 + \epsilon_{maq} \neq 1\) a precisión de la máquina.
\(\epsilon_{maq}\) es la distancia del número \(1\) al siguiente número de máquina.
Aunque las tres definiciones pueden diferir ligeramente, las tres pretenden dar la medida de granularidad de un SPF. Una representación gráfica para números positivos de un SPF es la siguiente:
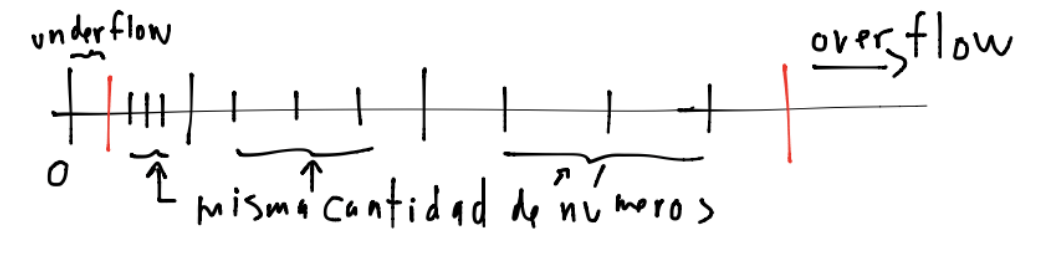
Para una discusión pequeña sobre las definiciones del \(\epsilon_{maq}\) ver variant definitions
Se tienen las siguientes afirmaciones:
El intervalo \([1,2]\) en un SPFN de doble precisión está formado por la secuencia de números de máquina: \(1, 1+ 2^{-52}, 1 + 2\times 2^{-52}, 1+ 3\times2^{-52}, \dots, 2\).
El intervalo \([2,4]\) en tal sistema está formado por: \(2, 2+ 2^{-51}, 2 + 2\times 2^{-51}, 2+ 3\times2^{-51}, \dots, 4\).
Por lo que el intervalo \([2^j, 2^{j+1}]\) se obtiene multiplicando \(2^j\) veces la secuencia en \([1,2]\) y los huecos entre un número de máquina y otro número de máquina no son en términos relativos más grandes que \(2^{-52} \approx 2.22 \times 10^{-16}\).
Asimismo, el intervalo \([\frac{1}{2}, 1]\) en tal sistema está formado por: \(\frac{1}{2}, \frac{1}{2}+2^{-53},\frac{1}{2}+2\times2^{-53},\frac{1}{2}+3\times2^{-53},\dots , 1\).
Si continuamos con esta idea puede verificarse que el cociente \(\frac{\text{número de máquina}_{j+1} - \text{número de máquina}_{j}}{2^{j+1}}\) es igual a \(\frac{2^{j-52}}{2^{j+1}} = 2^{-53}\). Entonces el espaciado entre cada número de máquina en el intervalo \([2^j, 2^{j+1}]\) siempre es menor o igual a \(2^{-53} = \epsilon_{maq}\).
Una forma computacional de obtener al \(\epsilon_{maq}\) de forma sencilla es con el cálculo:
#include<stdio.h>
#include<float.h>
int main(){
printf("Epsilon de la máquina: %e\n", 1/2.0*(1-3.0*(4/3.0-1)));
return 0;
}
Epsilon de la máquina: 1.110223e-16
Pregunta
¿Por qué funciona esto? tip: imprímase el cálculo \(3.0*(4/3.0-1)\) con el especificador de formato de la función printf %.16f o bien %.15e.
Reglas de corte y redondeo#
Al ver el diagrama anterior de la representación gráfica de un SPF se observa que existen huecos entre cada número de máquina. Lo anterior implica que al ingresar un número real \(x\) en la computadora, ésta realiza una aproximación a \(x\) que se encuentre en el SPF. Esta aproximación genera errores conocidos con el nombre de errores por redondeo.
Entre las reglas que una computadora realiza para dar las aproximaciones a un número \(x \in \mathbb{R}\) están: la regla de corte y la de redondeo y se pueden representar con funciones matemáticas:
Regla de corte: sea \(fl_c : \mathbb{R} \rightarrow \mathcal{F}\mathcal{l}\) una función cuya regla de correspondencia es: \(x \in \mathbb{R}\) con \(x\) en el rango de valores del SPFN, entonces: \(x = \pm 0.d_1d_2 \dots d_kd_{k+1}\dots \times \beta^n\) y la regla de corte a \(k\) dígitos es: \(fl_c(x) = \pm 0.d_1d_2 \dots d_k \times \beta^n\).
Regla de redondeo: sean \(\beta=10\) y \(fl_r : \mathbb{R} \rightarrow \mathcal{F}\mathcal{l}\) una función cuya regla de correspondencia es: \(x \in \mathbb{R}\) con \(x\) en el rango de valores del SPFN, entonces: \(x = \pm 0.d_1d_2 \dots d_kd_{k+1}\dots \times \beta^n\) y la regla de redondeo es:
Observación
La regla \(fl_r(\cdot)\) también suele definirse como antes y añadiendo la restricción que considera si es par o impar el último dígito en caso de empate, entonces se almacena el par. Lo anterior se conoce como round half to even.
Ejemplo#
\(\pi=3.141592\dots = 0.3141592\dots \times 10^1\). Si un SPFN usa \(k=5\) entonces:
Ejemplo#
Supóngase que \(fl_r(\cdot)\) hace diferencia entre el último dígito almacenado es par e impar (round half to even). Entonces para \(k=2\):
Número: x |
Corte: \(fl_c(x)\) |
Redondeo: \(fl_r(x)\) |
|---|---|---|
0.1649 |
0.16 |
0.16 |
0.1650 |
0.16 |
0.16 |
0.1651 |
0.16 |
0.17 |
0.1749 |
0.17 |
0.17 |
0.1750 |
0.17 |
0.18 |
0.1751 |
0.17 |
0.18 |
En la tabla anterior el empate lo encontramos en los casos en los que \(x=0.1650\) y \(x=0.1750\) pues están a la mitad del intervalo \([0.16, 0.17]\) y \([0.17, 0.18]\) respectivamente. Por lo anterior, la regla \(fl_r\) con el round half to even realiza la siguiente asignación:
Para el caso \(x=0.1650\) resulta en \(fl_r(x) = 0.16\) pues \(k=2\) y entonces se almacena el dígito \(6\) (par) y no el \(7\).
Para el caso \(x=0.1750\) resulta en \(fl_r(x) = 0.18\) pues \(k=2\) y entonces se almacena el dígito \(8\) (par) y no el \(7\).
Para los casos \(0.1649,0.1651,0.1749,0.1751\) como no hay empate se aplica la regla \(fl_r\) sin la restricción con lo que resulta en los valores \(0.16,0.17,0.17,0.18\) respectivamente.
Pregunta
Para el caso en el que \(k=3\) teniendo el punto \(x = 0.16550\) que está a la mitad del intervalo \([0.165,0.166]\) (hay empate) ¿cuál es el resultado de \(fl_r(x)\) con round half to even?
Por los ejemplos anteriores se puede comprobar que la regla de redondeo tiene menor error que la de corte:
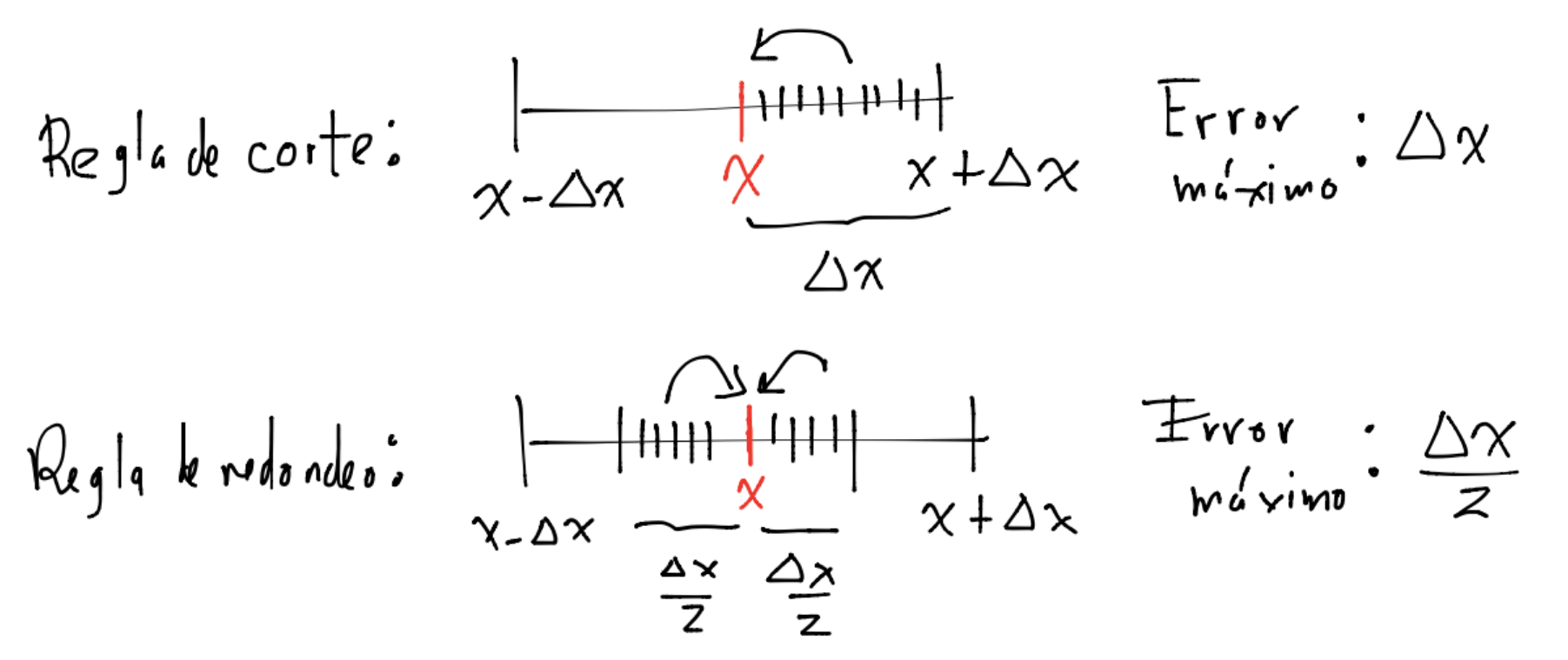
En el dibujo anterior considérese como números de máquina \(x, x-\Delta x, x - \frac{\Delta x}{2}, x+ \frac{\Delta x}{2}, x + \Delta x\).
Definición
Otra expresión utilizada para la regla \(fl(\cdot)\) es a partir de la definición de error relativo: \(aprox = obj(1+ErrRel(aprox))\) (si \(aprox \geq obj\) y \(obj > 0\)):
cuya interpretación es: la diferencia entre \(x\) con \(fl(x)\) es un término (en magnitud) de a lo más \(\epsilon_{maq}\) relativo a \(|x|\).
Comentario
Un resultado que puede verificarse de forma teórica es:
Para el caso de un sistema de punto flotante de doble precisión se tiene \(1-k = -52\) esto es: \(k=53\).
Ejemplo#
Considérese un SPFN con \(\beta=2, k=3\) entonces si se utiliza la regla de corte:
si se utiliza la regla de redondeo:
Aritmética de máquina.#
Además de representar números reales en la máquina otro objetivo es el de realizar operaciones entre ellos. Si la representación de números tiene un error asociado (error por redondeo) entonces es natural pensar que las operaciones aritméticas también tendrán errores por redondeo. Las razones de los errores son nuevamente el uso de precisión finita y la conversión entre bases: al ingresar números a la computadora se convierte a base \(2\) (por ejemplo), se realizan operaciones y el resultado se presenta en base \(10\).
Para analizar los errores por redondeo que se presentan en la aritmética de máquina es suficiente considerar la base \(10\), no conversiones entre bases (por ejemplo de la base \(2\) a la base \(10\)) y utilizar los siguientes operadores y suposiciones:
Supongamos que se tiene un SPFN y \(fl(\cdot)\) regla de corte o redondeo a una precisión \(k\) dada. Sean \(a,b \in \mathbb{R}\), se definen los siguientes operadores en el SPFN:
Ejercicio
Considérese \(x = \frac{5}{7} \approx \overline{0.714285}\), \(y=\frac{1}{3} = \overline{.3}\), \(u=0.714251, v=98765.9, w=0.111111 \times 10^{-4}\) y un SPFN con \(\beta=10, k=5\). Entonces llenar la siguiente tabla de acuerdo a las instrucciones:
En la columna “Aritmética de máquina con k=8” se realiza aritmética a \(8\) dígitos con las operaciones definidas previamente \(\oplus, \ominus, \otimes, \oslash\) con la regla de corte \(fl_c(\cdot)\).
En la columna “Aritmética de máquina con k=5” se realiza aritmética a \(5\) dígitos con las operaciones definidas previamente \(\oplus, \ominus, \otimes, \oslash\) con la regla de corte \(fl_c(\cdot)\).
Para el cálculo de errores absoluto y relativo tomar como valor real u objetivo el valor a \(8\) dígitos.
Operación |
Aritmética de máquina con k=8 |
Aritmética de máquina con k=5 |
Error Absoluto de aprox |
Error Relativo de aprox |
|---|---|---|---|---|
x \(\oplus\)y |
||||
x\(\ominus\)y |
||||
x\(\otimes\)y |
||||
x\(\oslash\)y |
||||
x\(\ominus\)u |
||||
(x\(\ominus\)u)\(\oslash\)w |
||||
(x\(\ominus\)u)\(\otimes\) v |
||||
u\(\oplus\)v |
Ejemplo#
El resultado del primer renglón con aritmética exacta es:
Para el llenado de las columnas:
Aritmética de máquina a \(8\) dígitos usamos \(k=8\): \(x \oplus_8 y = fl_c(0.71428571 + 0.33333333) = 0.10476190 \times 10^1\).
Aritmética de máquina usamos \(k=5\): \(x \oplus_5 y = fl_c(fl_c(x)+fl_c(y)) = fl_c(0.71428 + 0.33333) = fl_c(0.104761\times10^1) = 0.10476 \times10^1\).
Error absoluto de aprox: \(ErrAbs(x \oplus_5 y) = |(x \oplus_8 y) - (x \oplus_5 y)| = |0.10476190 \times 10^1 - 0.10476 \times10^1| = |0.00000190| = .190 \times 10^{-5}\).
Error relativo de aprox: \(ErrRel(x \oplus_5 y) = \frac{ErrAbs(x \oplus_5 y)}{|x \oplus_8 y|} =\frac{.190 \times 10^{-5}}{0.10476190 \times 10^1} \approx 1.81 \times 10^{-6} = 0.181 \times 10^{-5}\).
//%cflags:-lm
#include<stdio.h>
#include<stdlib.h>
#include<math.h>
double fl_c_k(double a, int k){
return (double)((int)(pow(10,k)*a)*pow(10,-k));
}
double err_abs(double aprox, double obj){
return fabs(obj-aprox);
}
double err_rel(double errabs, double obj){
return errabs/fabs(obj);
}
int main(){
double x = 5/7.0;
double y = 1/3.0;
double res1=0;
double res2=0;
int k;
k=8; //precisión 8
printf("valor x a 8 dígitos: %0.7e\n", fl_c_k(x,k));
printf("valor y a 8 dígitos: %0.7e\n", fl_c_k(y,k));
res1 = fl_c_k(fl_c_k(x,k)+fl_c_k(y,k),k-1); //k-1 para seguir manteniendo 5 dígitos pues la suma aumenta un dígito
printf("x+y a 8 dígitos %0.7e\n", res1);
k=5; //precisión 5
printf("valor x a 5 dígitos: %0.4e\n", fl_c_k(x,k));
printf("valor y a 5 dígitos: %0.4e\n", fl_c_k(y,k));
res2 = fl_c_k(fl_c_k(x,k)+fl_c_k(y,k),k-1); //k-1 para seguir manteniendo 5 dígitos pues la suma aumenta un dígito
printf("x+y a 5 dígitos %0.4e\n", res2);
printf("--------\n");
printf("Error absoluto de aprox: %e\n",err_abs(res2,res1));
printf("Error relativo de aprox: %e\n",err_rel(err_abs(res2,res1),res1));
return 0;
}
valor x a 8 dígitos: 7.1428571e-01
valor y a 8 dígitos: 3.3333333e-01
x+y a 8 dígitos 1.0476190e+00
valor x a 5 dígitos: 7.1428e-01
valor y a 5 dígitos: 3.3333e-01
x+y a 5 dígitos 1.0476e+00
--------
Error absoluto de aprox: 1.900000e-05
Error relativo de aprox: 1.813636e-05
Listando algunos problemas típicos que se presentan en la aritmética de máquina se tienen:#
Problema de cancelación: pérdida de cifras significativas a partir de la resta de números similares.
Suma entre un número de magnitud grande y un número de magnitud pequeña.
Sumas con términos que involucren signos alternados.
Multiplicación por un número de magnitud grande.
División por un número de magnitud pequeña.
Posibles soluciones:#
Usar mayor precisión.
Reordenar operaciones.
Reescribir expresiones matemáticas para obtener expresiones equivalentes.
Escalar las variables. También funciona estandarizarlas.
Ejercicios
1.Resuelve los ejercicios y preguntas de la nota.
2.Utiliza la notación posicional para representar al número \(86409\) y \((1001.1)_2\) en base \(10\).
3.¿Cuáles de los siguientes números son números de máquina en un SPFN con \(\beta=2\)?
a. \((2.125)_{10}\).
b. \((3.1)_{10}\).
tip: escribe los números anteriores como sumas de potencias de \(2\).
4.Considérese un SPFN con \(\beta=2, k=3\). En este sistema se tienen \(7\) bits para almacenar números. El primer bit se utiliza para el signo del número, el segundo bit se utiliza para el signo del exponente, los dos siguientes bits para construir al exponente y el último bit para construir a la mantisa. Entonces el número positivo normalizado más pequeño que es posible representar en este SPFN es:
a. Escribe los siguientes números más grandes a este número que forman al SPFN hasta el valor más grande positivo que es posible representar en este SPFN.
b. Calcula las distancias entre los números con mismo valor de exponente.
c. Verifica que el error relativo para \(x=0.156249\) utilizando la regla de corte es menor o igual a \(\epsilon_{maq}=.25\) y el error relativo para \(x=0.14\) utilizando la regla de redondeo es menor o igual a \(\epsilon_{maq}=0.125\).
Preguntas de comprehensión.
1)¿Cuáles componentes definen a un sistema de punto flotante?
2)Si un número tiene una representación exacta en la máquina, ¿qué nombre recibe?
3)¿Qué es un sistema de punto flotante normalizado?
4)Menciona algunas propiedades de un sistema de punto flotante normalizado.
5)¿Cuántos bits se utilizan en el hardware de una máquina para almacenar un número en un sistema de doble precisión?
6)¿Qué nombre reciben los errores que se generan por utilizar un sistema de punto flotante?
7)¿Cuáles reglas utiliza la máquina para dar aproximaciones a un número?
8)Explica con palabras la diferencia entre el epsilon de la máquina y el nivel de underflow:
a.¿Cuál de ellos depende únicamente del número de dígitos de la mantisa?
b.¿Cuál de ellos depende únicamente del número de dígitos del exponente?
c.¿Cuál de ellos no depende de la reglas usadas que se preguntaron en la pregunta 7?
9)Si calculamos un error relativo para una aproximación y resulta ser del orden de \(10^{-8}\) ¿alrededor de cuántos dígitos correctos tengo en mi aproximación?
10)Menciona algunos problemas típicos de la aritmética de máquina y algunas formas de resolverlos.
Referencias:
R. L. Burden, J. D. Faires, Numerical Analysis, Brooks/Cole Cengage Learning, 2005.
M. T. Heath, Scientific Computing. An Introductory Survey, McGraw-Hill, 2002.