1.7 Integración Numérica
Contents
1.7 Integración Numérica#
Notas para contenedor de docker:
Comando de docker para ejecución de la nota de forma local:
nota: cambiar <ruta a mi directorio> por la ruta de directorio que se desea mapear a /datos dentro del contenedor de docker y <versión imagen de docker> por la versión más actualizada que se presenta en la documentación.
docker run --rm -v <ruta a mi directorio>:/datos --name jupyterlab_optimizacion -p 8888:8888 -d palmoreck/jupyterlab_optimizacion:<versión imagen de docker>
password para jupyterlab: qwerty
Detener el contenedor de docker:
docker stop jupyterlab_optimizacion
Documentación de la imagen de docker palmoreck/jupyterlab_optimizacion:<versión imagen de docker> en liga.
Nota generada a partir de la liga1 y liga2.
Al final de esta nota la comunidad lectora:
Aprenderá que el método de integración numérica por Newton-Cotes es un método estable numéricamente respecto al redondeo.
Aprenderá a aproximar integrales de forma numérica por el método de Monte Carlo y tendrá una alternativa a los métodos por Newton-Cotes para el caso de más de una dimensión.
Reutilizará los métodos revisados en esta nota de integración numérica más adelante en el capítulo de optimización de código para uso de herramientas en Python de perfilamiento de código: uso de cpu y memoria y para cómputo en paralelo.
En lo siguiente consideramos que las funciones del integrando están en \(\mathcal{C}^2\) en el conjunto de integración (ver Definición de función, continuidad y derivada para definición de \(\mathcal{C}^2\)).
Las reglas o métodos por cuadratura nos ayudan a aproximar integrales con sumas de la forma:
donde: \(w_i\) es el peso para el nodo \(x_i\), \(f\) se llama integrando y \([a,b]\) intervalo de integración. Los valores \(f(x_i)\) se asumen conocidos.
Una gran cantidad de reglas o métodos por cuadratura se obtienen con interpoladores polinomiales del integrando (por ejemplo usando la representación de Lagrange) o también con el teorema Taylor (ver nota Polinomios de Taylor y diferenciación numérica para éste teorema).
Se realizan aproximaciones numéricas por:
Desconocimiento de la función en todo el intervalo \([a,b]\) y sólo se conoce en los nodos su valor.
Inexistencia de antiderivada o primitiva del integrando. Por ejemplo:
con \(a,b\) números reales.
Observación
Si existe antiderivada o primitiva del integrando puede usarse el cómputo simbólico o algebraico para obtener el resultado de la integral y evaluarse. Un paquete de Python que nos ayuda a lo anterior es SymPy.
Dependiendo de la ubicación de los nodos y pesos es el método de cuadratura que resulta:
Newton-Cotes si los nodos y pesos son equidistantes como la regla del rectángulo, trapecio y Simpson (con el teorema de Taylor o interpolación es posible obtener tales fórmulas).
Cuadratura Gaussiana si se desea obtener reglas o fórmulas que tengan la mayor exactitud posible (los nodos y pesos se eligen para cumplir con lo anterior). Ejemplos de este tipo de cuadratura se tiene la regla por cuadratura Gauss-Legendre en \([-1,1]\) (que usa polinomos de Legendre) o Gauss-Hermite (que usa polinomios de Hermite) para el caso de integrales en \([-\infty, \infty]\) con integrando \(e^{-x^2}f(x)\).
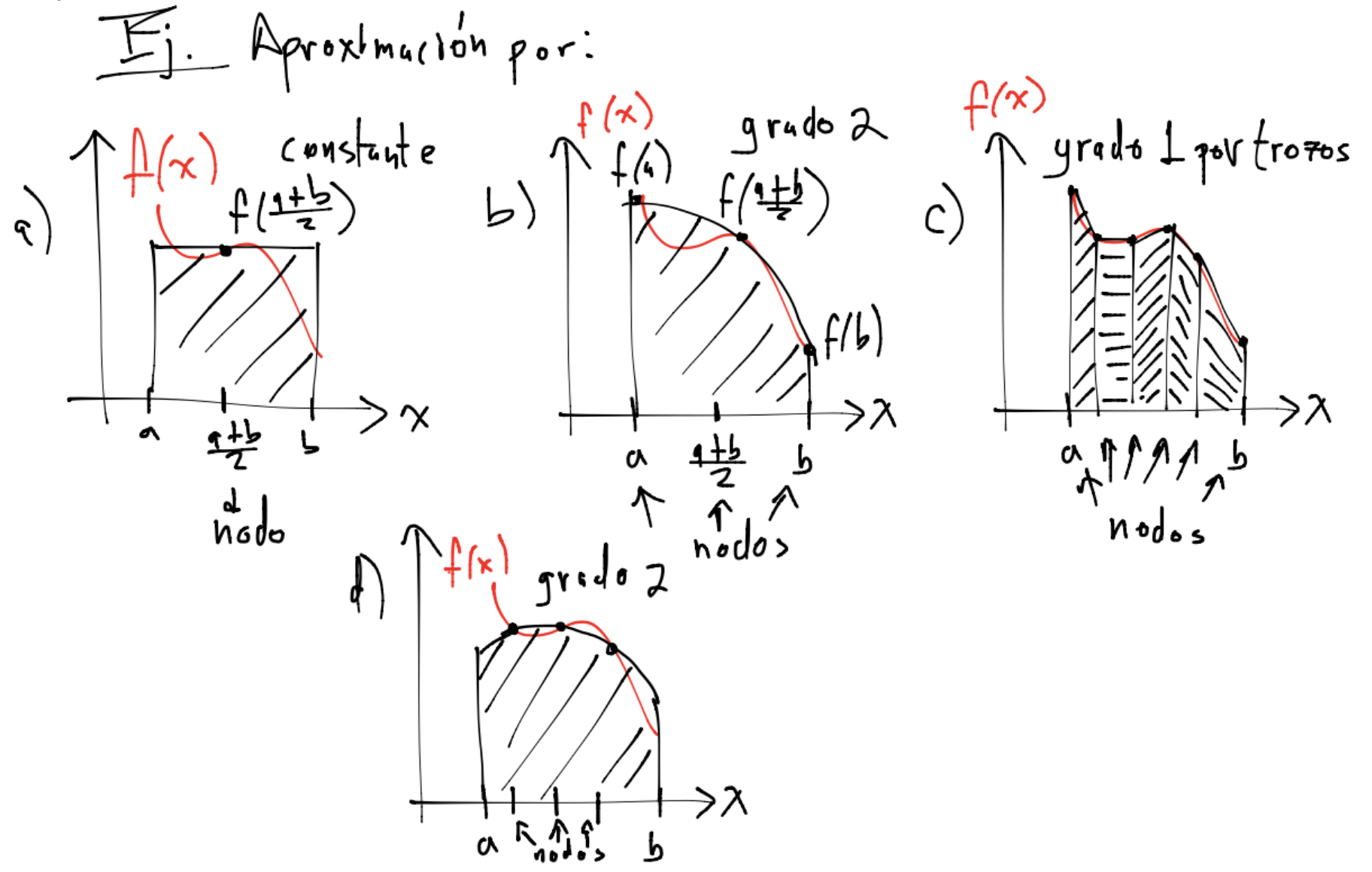
En el dibujo: a),b) y c) se integra numéricamente por Newton-Cotes. d) es por cuadratura Gaussiana.
Observación
Si la fórmula por Newton-Cotes involucra el valor de la función en los extremos se nombra cerrada, si no los involucra se les nombra abiertas. En el dibujo d) es abierta.
Definición
Los métodos que utilizan la idea anterior de dividir en subintervalos se les conoce como métodos de integración numérica compuestos en contraste con los simples:
Para las reglas compuestas se divide el intervalo \([a,b]\) en \(n_\text{sub}\) subintervalos \([a_{i-1},a_i], i=1,\dots,n_\text{sub}\) con \(a_0=a<a_1<\dots<a_{n_\text{sub}-1}<a_{n_\text{sub}}=b\) y se considera una partición regular, esto es: \(a_i-a_{i-1}=\hat{h}\) con \(\hat{h}=\frac{h}{n_\text{sub}}\) y \(h=b-a\). En este contexto se realiza la aproximación:
Comentario
Los métodos de integración numérica por Newton-Cotes o cuadratura Gaussiana pueden extenderse a más dimensiones, sin embargo incurren en lo que se conoce como la maldición de la dimensionalidad que para el caso de integración numérica consiste en la gran cantidad de evaluaciones que deben realizarse de la función del integrando para tener una exactitud pequeña. Por ejemplo con un número de nodos igual a \(10^4\), una distancia entre ellos de \(.1\) y una integral en \(4\) dimensiones para la regla por Newton Cotes del rectángulo, se obtiene una exactitud de \(2\) dígitos. Como alternativa a los métodos por cuadratura anteriores para las integrales de más dimensiones se tienen los métodos de integración por el método Monte Carlo que generan aproximaciones con una exactitud moderada (del orden de \(\mathcal{O}(n^{-1/2})\) con \(n\) número de nodos) para un número de puntos moderado independiente de la dimensión.
Newton-Cotes#
Si los nodos \(x_i, i=0,1,\dots,\) cumplen \(x_{i+1}-x_i=h, \forall i=0,1,\dots,\) con \(h\) (espaciado) constante y se aproxima la función del integrando \(f\) con un polinomio en \((x_i,f(x_i)) \forall i=0,1,\dots,\) entonces se tiene un método de integración numérica por Newton-Cotes (o reglas o fórmulas por Newton-Cotes).
Ejemplo de una integral que no tiene antiderivada#
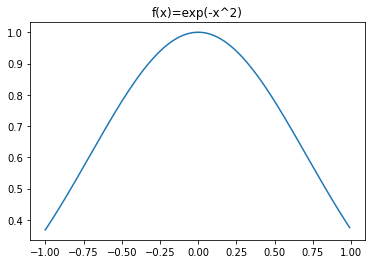
En las siguientes reglas se considerará la función \(f(x)=e^{-x^2}\) la cual tiene una forma:
import math
import numpy as np
import pandas as pd
from scipy.integrate import quad
import matplotlib.pyplot as plt
f=lambda x: np.exp(-x**2)
x=np.arange(-1,1,.01)
plt.plot(x,f(x))
plt.title('f(x)=exp(-x^2)')
plt.show()
El valor de la integral \(\int_0^1e^{-x^2}dx\) es:
obj, err = quad(f, 0, 1)
print((obj,err))
(0.7468241328124271, 8.291413475940725e-15)
Observación
El segundo valor regresado err, es una cota superior del error.
Regla simple del rectángulo#
Denotaremos a esta regla como \(Rf\). En este caso se aproxima el integrando \(f\) por un polinomio de grado cero con nodo en \(x_1 = \frac{a+b}{2}\). Entonces:
con \(h=b-a, x_1=\frac{a+b}{2}\).
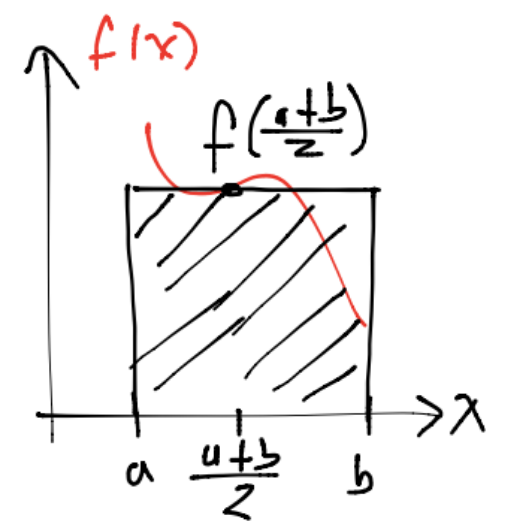
Ejemplo de implementación de regla simple de rectángulo: usando math#
Utilizar la regla simple del rectángulo para aproximar la integral \(\displaystyle \int_0^1e^{-x^2}dx\).
f=lambda x: math.exp(-x**2) #using math library
def Rf(f,a,b):
"""
Compute numerical approximation using simple rectangle or midpoint method in
an interval.
"""
node=a+(b-a)/2.0 #mid point formula to minimize rounding errors
return f(node) #zero degree polynomial
rf_simple = Rf(f,0,1)
print(rf_simple)
0.7788007830714049
Observación
Para cualquier aproximación calculada siempre es una muy buena idea reportar el error relativo de la aproximación si tenemos el valor del objetivo. No olvidar esto :)
Para el cálculo del error utilizamos fórmulas para calcular errores absolutos y relativos:
La siguiente función calcula un error relativo para un valor obj:
def compute_error(obj,approx):
'''
Relative or absolute error between obj and approx.
'''
if math.fabs(obj) > np.nextafter(0,1):
Err = math.fabs(obj-approx)/math.fabs(obj)
else:
Err = math.fabs(obj-approx)
return Err
print(compute_error(obj, rf_simple))
0.04281684114646715
El error relativo es de \(4.2\%\) aproximadamente.
Regla compuesta del rectángulo#
En cada subintervalo construído como \([a_{i-1},a_i]\) con \(i=1,\dots,n_{\text{sub}}\) se aplica la regla simple \(Rf\), esto es:
De forma sencilla se puede ver que la regla compuesta del rectángulo \(R_c(f)\) se escribe:
con \(h=b-a\) y \(n_\text{sub}\) número de subintervalos.
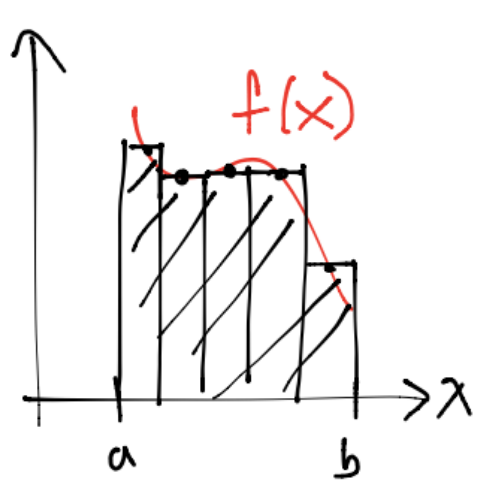
Observación
Los nodos para el caso del rectángulo se obtienen con la fórmula: \(x_i = a +(i+\frac{1}{2})\hat{h}, \forall i=0,\dots,n_\text{sub}-1, \hat{h}=\frac{h}{n_\text{sub}}\). Por ejemplo si \(a=1, b=2\) y \(\hat{h}=\frac{1}{4}\) (por tanto \(n_\text{sub}=4\) subintervalos) entonces:
Los subintervalos que tenemos son: \(\left[1,\frac{5}{4}\right], \left[\frac{5}{4}, \frac{6}{4}\right], \left[\frac{6}{4}, \frac{7}{4}\right]\) y \(\left[\frac{7}{4}, 2\right]\).
Los nodos están dados por:
Observación
Obsérvese que para el caso de la regla del rectángulo Rcf \(n = n_\text{sub}\) con \(n\) número de nodos.
Ejemplo de implementación de regla compuesta de rectángulo: usando math#
Utilizar la regla compuesta del rectángulo para aproximar la integral \(\int_0^1e^{-x^2}dx\).
f=lambda x: math.exp(-x**2) #using math library
def Rcf(f,a,b,n):
"""
Compute numerical approximation using rectangle or mid-point
method in an interval.
Nodes are generated via formula: x_i = a+(i+1/2)h_hat for
i=0,1,...,n-1 and h_hat=(b-a)/n
Args:
f (function): function expression of integrand.
a (float): left point of interval.
b (float): right point of interval.
n (float): number of subintervals.
Returns:
sum_res (float): numerical approximation to integral
of f in the interval a,b
"""
h_hat=(b-a)/n
nodes=[a+(i+1/2)*h_hat for i in range(0,n)]
sum_res=0
for node in nodes:
sum_res=sum_res+f(node)
return h_hat*sum_res
a = 0; b = 1
1 nodo
n = 1
rcf_1 = Rcf(f,a, b, n)
print(rcf_1)
0.7788007830714049
2 nodos
n = 2
rcf_2 = Rcf(f,a, b, n)
print(rcf_2)
0.7545979437721995
\(10^3\) nodos
n = 10**3
rcf_3 = Rcf(f, a, b, n)
print(rcf_3)
0.746824163469049
Errores relativos:
rel_err_rcf_1 = compute_error(obj, rcf_1)
rel_err_rcf_2 = compute_error(obj, rcf_2)
rel_err_rcf_3 = compute_error(obj, rcf_3)
dic = {"Aproximaciones Rcf": [
"Rcf_1",
"Rcf_2",
"Rcf_3"
],
"Número de nodos" : [
1,
2,
1e3
],
"Errores relativos": [
rel_err_rcf_1,
rel_err_rcf_2,
rel_err_rcf_3
]
}
print(pd.DataFrame(dic))
Aproximaciones Rcf Número de nodos Errores relativos
0 Rcf_1 1.0 4.281684e-02
1 Rcf_2 2.0 1.040916e-02
2 Rcf_3 1000.0 4.104932e-08
Comentario: pytest#
Otra forma de evaluar las aproximaciones realizadas es con módulos o paquetes de Python creados para este propósito en lugar de crear nuestras funciones como la de compute_error. Uno de estos es el paquete pytest y la función approx de este paquete:
from pytest import approx
print(rcf_1 == approx(obj))
False
print(rcf_2 == approx(obj))
False
print(rcf_3 == approx(obj))
True
Y podemos usar un valor de tolerancia definido para hacer la prueba (por default se tiene una tolerancia de \(10^{-6}\)):
print(rcf_1 == approx(obj, abs=1e-1, rel=1e-1))
True
Pregunta#
Será el método del rectángulo un método estable numéricamente bajo el redondeo? Ver nota Condición de un problema y estabilidad de un algoritmo para definición de estabilidad numérica de un algoritmo.
Para responder la pregunta anterior aproximamos la integral con más nodos: \(10^5\) nodos
n = 10**5
rcf_4 = Rcf(f, a, b, n)
print(rcf_4)
0.7468241328154887
print(compute_error(obj, rcf_4))
4.099426997862257e-12
Al menos para este ejemplo con \(10^5\) nodos parece ser numéricamente estable…
Regla compuesta del trapecio#
En cada subintervalo se aplica la regla simple \(T(f)\), esto es:
Con \(T_i(f) = \frac{(a_i-a_{i-1})}{2}(f(a_i)+f(a_{i-1}))\) para \(i=1,\dots,n_\text{sub}\).
De forma sencilla se puede ver que la regla compuesta del trapecio \(T_c(f)\) se escribe como:
con \(h=b-a\) y \(n_\text{sub}\) número de subintervalos.
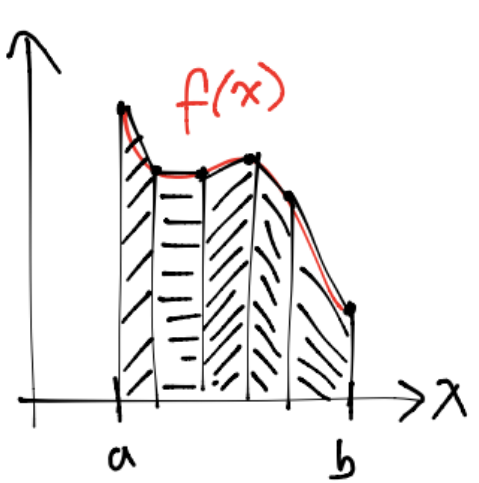
Observaciones
Los nodos para el caso del trapecio se obtienen con la fórmula: \(x_i = a +i\hat{h}, \forall i=0,\dots,n_\text{sub}, \hat{h}=\frac{h}{n_\text{sub}}\).
Obsérvese que para el caso de la regla del trapecio Tcf \(n = n_\text{sub}+1\) con \(n\) número de nodos.
Ejemplo de implementación de regla compuesta del trapecio: usando numpy#
Con la regla compuesta del trapecio se aproximará la integral \(\int_0^1e^{-x^2}dx\). Se calculará el error relativo y graficará \(n_\text{sub}\) vs Error relativo para \(n_\text{sub}=1,10,100,1000,10000\).
f=lambda x: np.exp(-x**2) #using numpy library
def Tcf(n,f,a,b): #Tcf: trapecio compuesto para f
"""
Compute numerical approximation using trapezoidal method in
an interval.
Nodes are generated via formula: x_i = a+ih_hat for i=0,1,...,n and h_hat=(b-a)/n
Args:
f (function): function expression of integrand
a (float): left point of interval
b (float): right point of interval
n (float): number of subintervals
Returns:
sum_res (float): numerical approximation to integral of f in the interval a,b
"""
h=b-a
nodes=np.linspace(a,b,n+1)
sum_res=sum(f(nodes[1:-1]))
return h/(2*n)*(f(nodes[0])+f(nodes[-1])+2*sum_res)
Graficamos:
numb_of_subintervals=(1,10,100,1000,10000)
tcf_approx = np.array([Tcf(n,f,0,1) for n in numb_of_subintervals])
La siguiente función calcula un error relativo para el valor obj con vectorización:
def compute_error_point_wise(obj,approx):
'''
Relative or absolute error between obj and approx.
'''
if np.abs(obj) > np.nextafter(0,1):
Err = np.abs(obj-approx)/np.abs(obj)
else:
Err = np.abs(obj-approx)
return Err
relative_errors = compute_error_point_wise(obj, tcf_approx)
print(relative_errors)
[8.42024373e-02 8.21259857e-04 8.20989064e-06 8.20986364e-08
8.20987410e-10]
plt.plot(numb_of_subintervals, relative_errors,'o')
plt.xlabel('number of subintervals')
plt.ylabel('Relative error')
plt.title('Error relativo en la regla del Trapecio')
plt.show()

Si no nos interesa el valor de los errores relativos y sólo la gráfica podemos utilizar la siguiente opción:
from functools import partial
Ver functools.partial para documentación, liga para una explicación de partial y liga2, liga3 para ejemplos de uso.
tcf_approx_2 = map(partial(Tcf,f=f,a=a,b=b),
numb_of_subintervals) #map returns an iterator
La siguiente función calcula un error relativo para un valor obj:
def compute_error_point_wise_2(obj, approx):
for ap in approx:
yield math.fabs(ap-obj)/math.fabs(obj) #using math library
Observación
La función compute_error_point_wise_2 anterior es un generator, ver liga para conocer el uso de yield.
relative_errors_2 = compute_error_point_wise_2(obj, tcf_approx_2)
plt.plot(numb_of_subintervals,list(relative_errors_2),'o')
plt.xlabel('number of subintervals')
plt.ylabel('Relative error')
plt.title('Error relativo en la regla del Trapecio')
plt.show()

Otra forma con scatter:
tcf_approx_2 = map(partial(Tcf,f=f,a=a,b=b),
numb_of_subintervals) #map returns an iterator
relative_errors_2 = compute_error_point_wise_2(obj, tcf_approx_2)
[plt.scatter(n,rel_err) for n,rel_err in zip(numb_of_subintervals,relative_errors_2)]
plt.xlabel('number of subintervals')
plt.ylabel('Relative error')
plt.title('Error relativo en la regla del Trapecio')
plt.show()

Regla compuesta de Simpson#
En cada subintervalo se aplica la regla simple \(S(f)\), esto es:
con \(S_i(f) = \frac{h}{6}\left[f(x_{2i})+f(x_{2i-2})+4f(x_{2i-1})\right]\) para el subintervalo \([a_{i-1},a_i]\) con \(i=1,\dots,n_\text{sub}\).
De forma sencilla se puede ver que la regla compuesta de Simpson compuesta \(S_c(f)\) se escribe como:
con \(h=b-a\) y \(n_\text{sub}\) número de subintervalos.
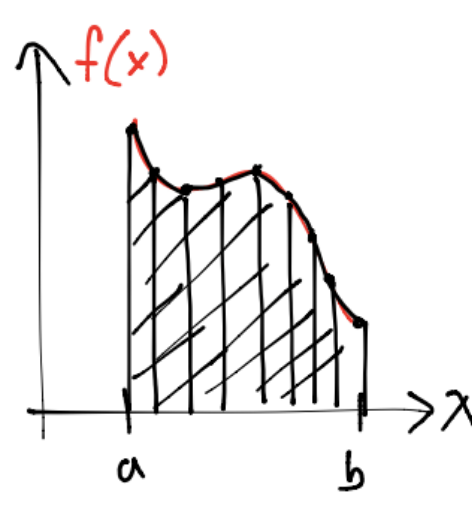
Observaciones
Los nodos para el caso de Simpson se obtienen con la fórmula: \(x_i = a +\frac{i}{2}\hat{h}, \forall i=0,\dots,2n, \hat{h}=\frac{h}{n_\text{sub}}\).
Obsérvese que para el caso de la regla de Simpson Scf \(n = 2n_\text{sub}+1\) con \(n\) número de nodos.
Ejercicio
Utilizando lenguajes de programación, implementar la regla compuesta de Simpson para aproximar la integral \(\int_0^1e^{-x^2}dx\). Calcular error relativo y realizar una gráfica de \(n\) vs Error relativo para \(n=1,10,100,1000,10000\) utilizando Numpy e iterators.
Expresiones de los errores para las reglas compuestas del rectángulo, trapecio y Simpson#
La forma de los errores de las reglas del rectángulo, trapecio y Simpson se pueden obtener con interpolación o con el teorema de Taylor. Ver Diferenciación e Integración para detalles y Polinomios de Taylor y diferenciación numérica para el teorema. Suponiendo que \(f\) cumple con condiciones sobre sus derivadas, tales errores son:
Análisis del error por redondeo y truncamiento en la aproximación por la regla compuesta del rectángulo#
Los resultados numéricos y gráficas muestran que las reglas por Newton Cotes son estables numéricamente bajo el redondeo (ver nota Condición de un problema y estabilidad de un algoritmo para definición de estabilidad de un algoritmo) y también se puede corroborar realizando un análisis del error. En esta sección consideramos la aproximación a la integral definida de una función por la regla compuesta del rectángulo \(R_c(f)\).
con \(h=b-a\), \(x_i\) nodo \(i\), subintervalos \([a_{i-1},a_i]\) con \(i=1,\dots,n_{\text{sub}}\) para \([a,b]\), \(n_\text{sub}\) número de subintervalos y \(\hat{h}=\frac{h}{n_\text{sub}}\).
Suponemos que \(\hat{f}(x)\) aproxima a \(f(x)\) y por errores de redondeo \(\hat{f}(x) = f(x)(1 + \epsilon_{f(x)})\) con \(|\epsilon_{f(x)}| \leq \epsilon_{maq}\) error de redondeo al evaluar \(f\) en \(x\). \(\hat{f}(x)\) es la aproximación en un SPFN (ver nota Sistema de punto flotante). Además supóngase que \(x_i \in \mathcal{Fl}, \forall i = 1, \dots, n_{\text{sub}}\).
Entonces en la aproximación por la regla \(R_c(f)\):
\(\displaystyle \int_a^b f(x)dx = \hat{h} \sum_{i=1}^{n_\text{sub}}f\left( x_i\right) + \mathcal{O}(\hat{h}^2)\) y calculando el error absoluto:
suponiendo en el último paso que \(C >0\) es tal que \(| f(x_i)\epsilon_{f(x_i)}| \leq C\epsilon_{\text{maq}}, \forall i=1, \dots , n_{\text{sub}}\)
Obsérvese que \(\hat{h}\displaystyle \sum_{i=1}^{n_\text{sub}}\hat{f}(x_i)\) es la aproximación por la regla del rectángulo compuesta que se obtiene en la computadora por lo que la cantidad \(\left | \displaystyle \int_a^b f(x)dx - \hat{h} \sum_{i=1}^{n_\text{sub}}\hat{f}(x_i) \right |\) es el error absoluto de tal aproximación.
El error relativo es:
con \(K_1, K_2 >0\) constantes.
Entonces la función \(g(h) = \mathcal{O}(\hat{h}^2) + K_2\) acota al error absoluto y al error relativo. Si \(\hat{h} \rightarrow 0\) (incrementa \(n_{\text{sub}}\)) el error por truncamiento tiende a cero y el error por redondeo tiende a una constante.
Lo anterior prueba que la regla compuesta del rectángulo es estable numéricamente bajo el redondeo.
Integración por el método de Monte Carlo#
Los métodos de integración numérica por Monte Carlo son similares a los métodos por cuadratura en el sentido que se eligen puntos en los que se evaluará el integrando para sumar sus valores. La diferencia esencial con los métodos por cuadratura es que en el método de integración por Monte Carlo los puntos son seleccionados de una forma aleatoria (de hecho es pseudo-aleatoria pues se generan con un programa de computadora) en lugar de generarse con una fórmula.
Problema#
En esta sección consideramos \(n\) número de nodos.
Aproximar numéricamente la integral \(\displaystyle \int_{\Omega}f(x)dx\) para \(x \in \mathbb{R}^\mathcal{D}, \Omega \subseteq \mathbb{R}^\mathcal{D}, f: \mathbb{R}^\mathcal{D} \rightarrow \mathbb{R}\) función tal que la integral esté bien definida en \(\Omega\).
Por ejemplo para \(\mathcal{D}=2:\)
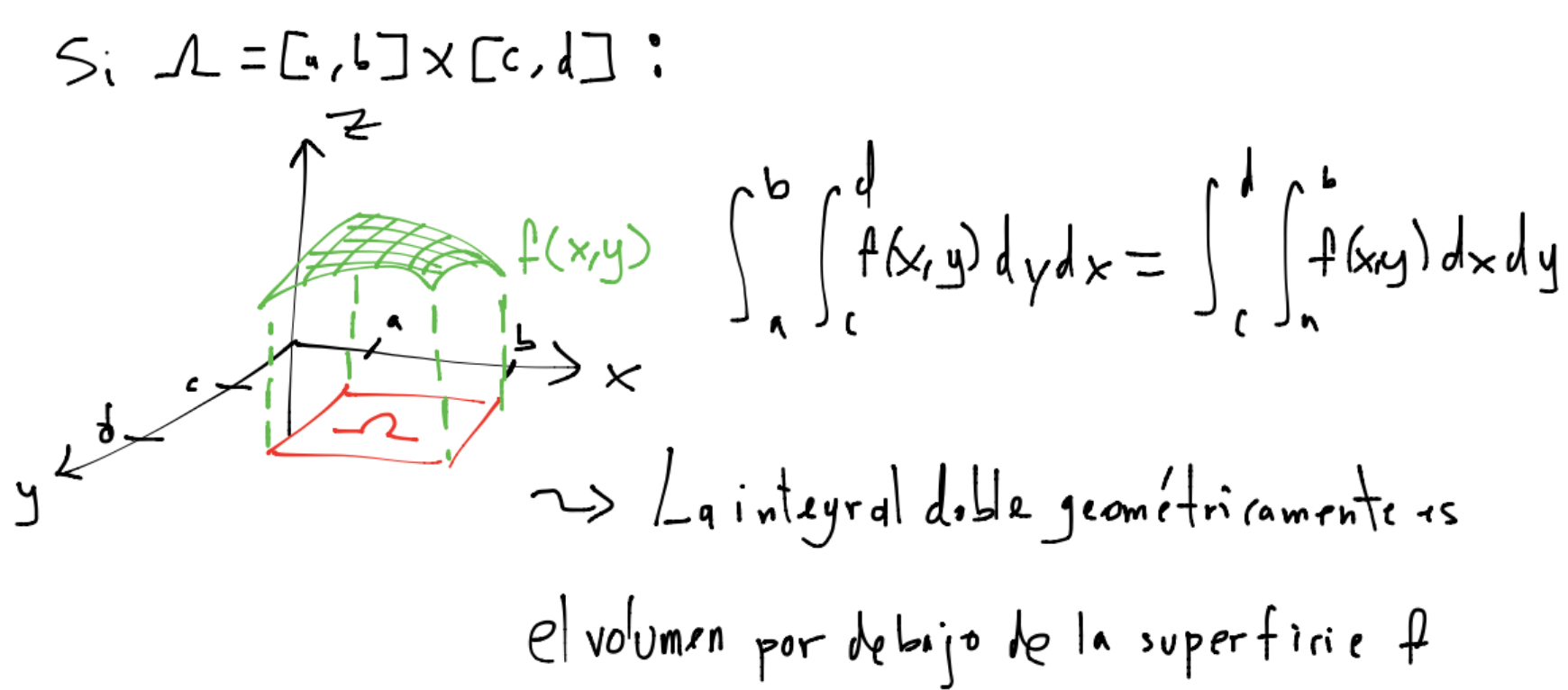
Para resolver el problema anterior con \(\Omega\) un rectángulo, podemos utilizar las reglas por cuadratura por Newton-Cotes o cuadratura Gaussiana en una dimensión manteniendo fija la otra dimensión. Sin embargo considérese la siguiente situación:
La regla del rectángulo (o del punto medio) y del trapecio tienen un error de orden \(\mathcal{O}(\hat{h}^2)\) independientemente de si se está aproximando integrales de una o más dimensiones. Supóngase que se utilizan \(n\) nodos para tener un valor de espaciado igual a \(\hat{h}\) en una dimensión, entonces para \(\mathcal{D}\) dimensiones se requerirían \(N=n^\mathcal{D}\) evaluaciones del integrando, o bien, si se tiene un valor de \(N\) igual a \(10, 000\) y \(\mathcal{D}=4\) dimensiones el error sería del orden \(\mathcal{O}(N^{-2/\mathcal{D}})\) lo que implicaría un valor de \(\hat{h}=.1\) para alrededor sólo dos dígitos correctos en la aproximación (para el enunciado anterior recuérdese que \(\hat{h}\) es proporcional a \(n^{-1}\) y \(n\) = \(N^{1/\mathcal{D}}\)). Este esfuerzo enorme de evaluar \(N\) veces el integrando para una exactitud pequeña se debe al problema de generar puntos para llenar un espacio \(\mathcal{D}\)-dimensional y se conoce con el nombre de la maldición de la dimensionalidad, the curse of dimensionality.
Una opción para resolver la situación anterior si no se desea una precisión alta (por ejemplo con una precisión de \(10^{-4}\) o \(4\) dígitos es suficiente) es con el método de integración por Monte Carlo (tal nombre por el uso de números aleatorios). La integración por el método de Monte Carlo está basada en la interpretación geométrica de las integrales: calcular la integral del problema inicial requiere calcular el hipervolumen de \(\Omega\).
Ejemplo#
Supóngase que se desea aproximar el área de un círculo centrado en el origen de radio igual a \(1\):
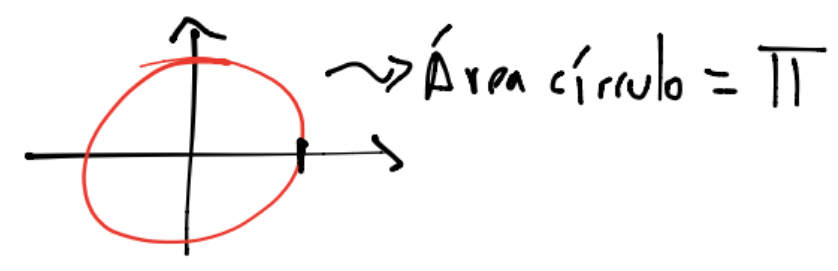
entonces el área de este círculo es \(\pi r^2 = \pi\).
Para lo anterior encerramos al círculo con un cuadrado de lado \(2\):
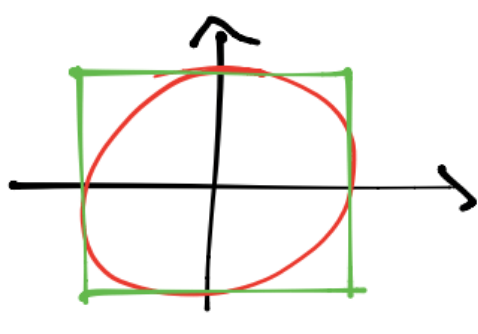
Si tenemos \(n\) puntos en el cuadrado:
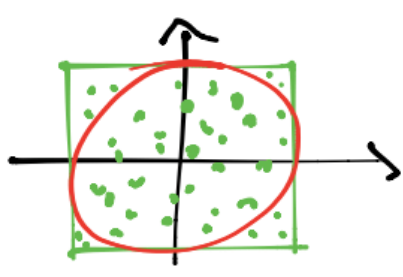
y consideramos los \(m\) puntos que están dentro del círculo:
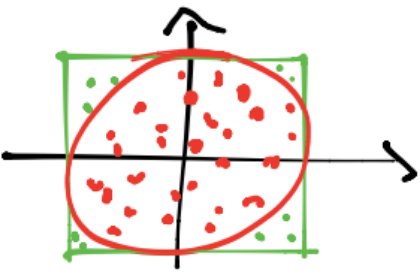
Entonces: \(\frac{\text{Área del círculo}}{\text{Área del cuadrado}} \approx \frac{m}{n}\) y se tiene: Área del círculo \(\approx\)Área del cuadrado\(\frac{m}{n}\) y si \(n\) crece entonces la aproximación es mejor.
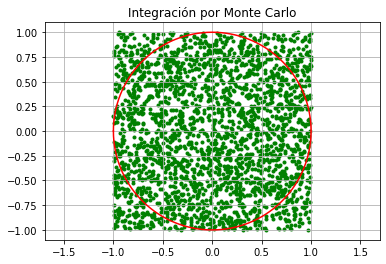
Prueba numérica:
density_p=int(2.5*10**3)
x_p=np.random.uniform(-1,1,(density_p,2))
plt.scatter(x_p[:,0],x_p[:,1],marker='.',color='g')
density=1e-5
x=np.arange(-1,1,density)
y1=np.sqrt(1-x**2)
y2=-np.sqrt(1-x**2)
plt.plot(x,y1,'r',x,y2,'r')
plt.title('Integración por Monte Carlo')
plt.grid()
plt.axis("equal")
plt.show()
f=lambda x: np.sqrt(x[:,0]**2 + x[:,1]**2) #norm2 definition
ind=f(x_p)<=1
x_p_subset=x_p[ind]
plt.scatter(x_p_subset[:,0],x_p_subset[:,1],marker='.',color='r')
plt.title('Integración por Monte Carlo')
plt.grid()
plt.axis("equal")
plt.show()
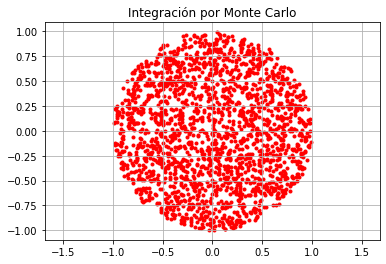
Área del círculo es aproximadamente:
square_area = 4
print(square_area*len(x_p_subset)/len(x_p))
3.1984
Si aumentamos el número de puntos…
density_p=int(10**4)
x_p=np.random.uniform(-1,1,(density_p,2))
ind=f(x_p)<=1
x_p_subset=x_p[ind]
print(square_area*len(x_p_subset)/len(x_p))
3.14
density_p=int(10**5)
x_p=np.random.uniform(-1,1,(density_p,2))
ind=f(x_p)<=1
x_p_subset=x_p[ind]
print(square_area*len(x_p_subset)/len(x_p))
3.1488
Comentarios
El método de Monte Carlo revisado en el ejemplo anterior nos indica que debemos encerrar a la región de integración \(\Omega\). Por ejemplo para una región \(\Omega\) más general:
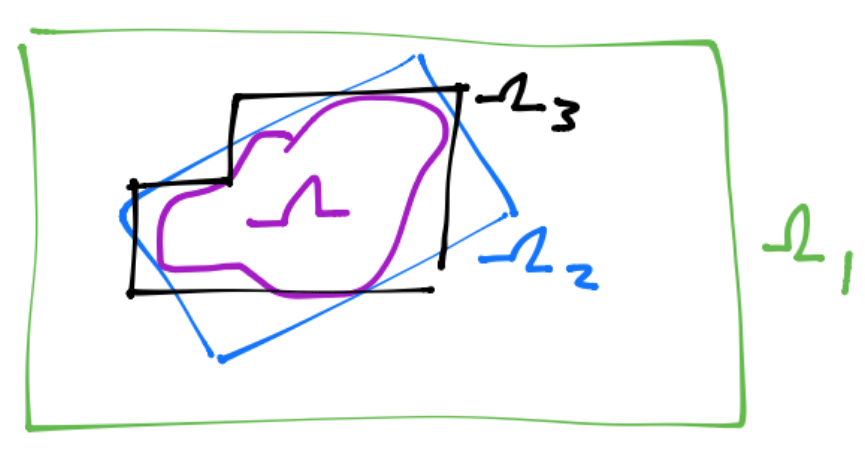
entonces la integración por el método de Monte Carlo será:
donde: \(V\) es el hipervolumen de \(\Omega_E\) que encierra a \(\Omega\), esto es \(\Omega \subseteq \Omega_E\), \(\{x_1,\dots,x_n\}\) es un conjunto de puntos distribuidos uniformemente en \(\Omega_E\) y \(\overline{f}=\frac{1}{n}\displaystyle \sum_{i=1}^nf(x_i)\)
Consideramos \(\overline{f}\) pues \(\displaystyle \sum_{i=1}^nf(x_i)\) representa el valor de \(m\) si pensamos a \(f\) como una restricción que deben cumplir los \(n\) puntos en el ejemplo de aproximación al área del círculo: Área del círculo \(\approx\)Área del cuadrado\(\frac{m}{n}\) (en este caso Área del cuadrado es el hipervolumen \(V\)).
Algunas características para regiones \(\Omega_E\) que encierren a \(\Omega\) es que:
Sea sencillo generar números aleatorios uniformes.
Sea sencillo obtener su hipervolumen.
Ejemplos#
Aproximar las siguientes integrales:
density_p=int(10**4)
\(\displaystyle \int_0^1\frac{4}{1+x^2}dx = \pi\)
f = lambda x: 4/(1+x**2)
x_p = np.random.uniform(0,1,density_p)
obj = math.pi
a = 0
b = 1
vol = b-a
ex_1 = vol*np.mean(f(x_p))
print("error relativo: {:0.4e}".format(compute_error(obj, ex_1)))
error relativo: 9.9333e-04
\(\displaystyle \int_1^2 \frac{1}{x}dx = \log{2}\).
f = lambda x: 1/x
x_p = np.random.uniform(1,2,density_p)
obj = math.log(2)
a = 1
b = 2
vol = b-a
ex_2 = vol*np.mean(f(x_p))
print("error relativo: {:0.4e}".format(compute_error(obj, ex_2)))
error relativo: 4.0686e-04
\(\displaystyle \int_{-1}^1 \int_0^1x^2+y^2dxdy = \frac{4}{3}\).
f = lambda x,y:x**2+y**2
a1 = -1
b1 = 1
a2 = 0
b2 = 1
x_p = np.random.uniform(a1,b1,density_p)
y_p = np.random.uniform(a2,b2,density_p)
obj = 4/3
vol = (b1-a1)*(b2-a2)
ex_3 = vol*np.mean(f(x_p,y_p))
print("error relativo: {:0.4e}".format(compute_error(obj, ex_3)))
error relativo: 2.5916e-03
\(\displaystyle \int_0^{\frac{\pi}{2}} \int_0^{\frac{\pi}{2}}\cos(x)\sin(y)dxdy=1\).
f = lambda x,y:np.cos(x)*np.sin(y)
a1 = 0
b1 = math.pi/2
a2 = 0
b2 = math.pi/2
x_p = np.random.uniform(a1,b1,density_p)
y_p = np.random.uniform(a2,b2,density_p)
obj = 1
vol = (b1-a1)*(b2-a2)
ex_4 = vol*np.mean(f(x_p,y_p))
print("error relativo: {:0.4e}".format(compute_error(obj, ex_4)))
error relativo: 7.7616e-03
\(\displaystyle \int_0^1\int_{\frac{-1}{2}}^0\int_0^{\frac{1}{3}}(x+2y+3z)^2dxdydz =\frac{1}{12}\).
f = lambda x,y,z:(x+2*y+3*z)**2
a1 = 0
b1 = 1
a2 = -1/2
b2 = 0
a3 = 0
b3 = 1/3
x_p = np.random.uniform(a1,b1,density_p)
y_p = np.random.uniform(a2,b2,density_p)
z_p = np.random.uniform(a3,b3,density_p)
obj = 1/12
vol = (b1-a1)*(b2-a2)*(b3-a3)
ex_5 = vol*np.mean(f(x_p,y_p,z_p))
print("error relativo: {:0.4e}".format(compute_error(obj, ex_5)))
error relativo: 9.2338e-03
¿Cuál es el error en la aproximación por el método de integración por Monte Carlo?#
Para obtener la expresión del error en esta aproximación supóngase que \(x_1, x_2,\dots x_n\) son variables aleatorias independientes uniformemente distribuidas. Entonces:
con \(x\) variable aleatoria uniformemente distribuida.
Un estimador de \(\text{Var}(f(x))\) es: \(\frac{1}{n}\displaystyle \sum_{i=1}^n(f(x_i)-\overline{f})^2=\overline{f^2}-\overline{f}^2\) por lo que \(\hat{\text{Err}}(\overline{f}) = \sqrt{\frac{\overline{f^2}-\overline{f}^2}{n}}\).
Se tiene entonces que \(\displaystyle \int_\Omega f d\Omega\) estará en el intervalo:
Comentarios
Los signos \(\pm\) en el error de aproximación no representan una cota rigurosa, es una desviación estándar.
A diferencia de la aproximación por las reglas por cuadratura tenemos una precisión con \(n\) puntos independientemente de la dimensión \(\mathcal{D}\).
Si \(\mathcal{D} \rightarrow \infty\) entonces \(\hat{\text{Err}}(\overline{f}) = \mathcal{O}\left(\frac{1}{\sqrt{n}} \right)\) por lo que para ganar un decimal extra de precisión en la integración por el método de Monte Carlo se requiere incrementar el número de puntos por un factor de \(10^2\).
Observación
Obsérvese que si \(f\) es constante entonces \(\hat{\text{Err}}(\overline{f})=0\). Esto implica que si \(f\) es casi constante y \(\Omega_E\) encierra muy bien a \(\Omega\) entonces se tendrá una estimación muy precisa de \(\displaystyle \int_\Omega f d\Omega\), por esto en la integración por el método de Monte Carlo se realizan cambios de variable de modo que transformen a \(f\) en aproximadamente constante y que esto resulte además en regiones \(\Omega_E\) que encierren a \(\Omega\) casi de manera exacta (y que además sea sencillo generar números pseudo aleatorios en ellas!).
Ejemplo#
Para el ejemplo anterior \(\displaystyle \int_0^1\frac{4}{1+x^2}dx = \pi\) se tiene:
f = lambda x: 4/(1+x**2)
x_p = np.random.uniform(0,1,density_p)
obj = math.pi
a = 0
b = 1
vol = b-a
f_bar = np.mean(f(x_p))
ex_6 = vol*f_bar
print("error relativo: {:0.4e}".format(compute_error(obj,ex_6 )))
error relativo: 6.1895e-04
error_std = math.sqrt(sum((f(x_p)-f_bar)**2)/density_p**2)
print(error_std)
0.0064134600862227375
intervalo:
left_point_interval = ex_6-vol*error_std
right_point_interval = ex_6+vol*error_std
print((left_point_interval, right_point_interval))
(3.137123675347265, 3.1499505955197105)
la estimación se encuentra en el intervalo:
ex_6 >= left_point_interval and ex_6 <= right_point_interval
True
Ejercicios
Utilizando lenguajes de programación, aproximar, reportar errores relativos e intervalo de estimación en una tabla:
\(\displaystyle \int_0^1\int_0^1\sqrt{x+y}dydx=\frac{2}{3}\left(\frac{2}{5}2^{5/2}-\frac{4}{5}\right)\).
\(\displaystyle \int_D \int \sqrt{x+y}dydx=8\frac{\sqrt{2}}{15}\) donde: \(D=\{(x,y) \in \mathbb{R}^2 | 0 \leq x \leq 1, -x \leq y \leq x\}\).
\(\displaystyle \int_D \int \exp{(x^2+y^2)}dydx = \pi(e^9-1)\) donde: \(D=\{(x,y) \in \mathbb{R}^2 | x^2+y^2 \leq 9\}\).
\(\displaystyle \int_0^2 \int_{-1}^1 \int_0^1 (2x+3y+z)dzdydx = 10\).
Aproximación de características de variables aleatorias#
La integración por el método de Monte Carlo se utiliza para aproximar características de variables aleatorias continuas. Por ejemplo, si \(x\) es variable aleatoria continua, entonces su media está dada por:
donde: \(f\) es función de densidad de \(X\), \(S_X\) es el soporte de \(X\) y \(h\) es una transformación. Entonces:
con \(\{x_1,x_2,\dots,x_n\}\) muestra de \(f\). Y por la ley de los grandes números se tiene:
con convergencia casi segura. Aún más: si \(E_f[h^2(X)] < \infty\) entonces el error de aproximación de \(\overline{h}_n\) es del orden \(\mathcal{O}\left(\frac{1}{\sqrt{n}} \right)\) y una estimación de este error es: \(\hat{\text{Err}}(\overline{h}) = \sqrt{\frac{\overline{h^2}-\overline{h}^2}{n}}\). Por el teorema del límite central:
con \(N(0,1)\) una distribución Normal con \(\mu=0,\sigma=1\) \(\therefore\) si \(n \rightarrow \infty\) un intervalo de confianza al \(95\%\) para \(E_f[h(X)]\) es: \(\overline{h}_n \pm z_{.975} \hat{\text{Err}}(\overline{h}_n)\).
Uno de los pasos complicados en el desarrollo anterior es obtener una muestra de \(f\). Para el caso de variables continuas se puede utilizar el teorema de transformación inversa o integral de probabilidad. Otros métodos son los nombrados métodos de monte Carlo con cadenas de Markov o MCMC.
Ejemplo#
h = lambda x: 1
n = 10**3 #number of points
normal_rvs = np.random.normal(loc = 5, size = n)
np.mean(h(normal_rvs))
1.0
Ejemplo#
h = lambda x: x
np.mean(h(normal_rvs))
5.014580184171905
Ejemplo#
h = lambda x: x**2
np.mean(h(normal_rvs))
26.177762253134738
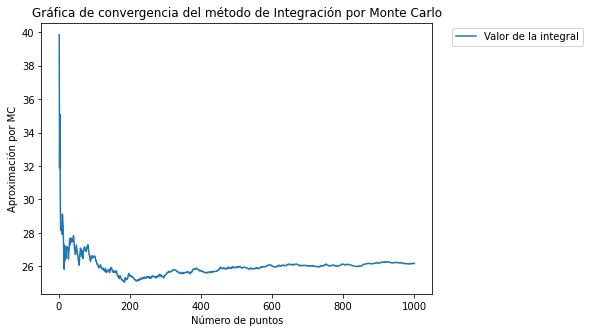
Gráfica que apoya la visualización de la convergencia al valor de la integral por las aproximaciones vía Monte Carlo
iterations = np.arange(n)+1
cumulative_mean = np.cumsum(h(normal_rvs))/iterations
plt.figure(figsize=(7,5))
plt.plot(iterations, cumulative_mean)
plt.legend(["Valor de la integral"], bbox_to_anchor=(1.4, 1))
plt.title("Gráfica de convergencia del método de Integración por Monte Carlo")
plt.ylabel("Aproximación por MC")
plt.xlabel("Número de puntos")
plt.show()
Ejemplo#
from numpy.random import exponential
from scipy.stats import norm
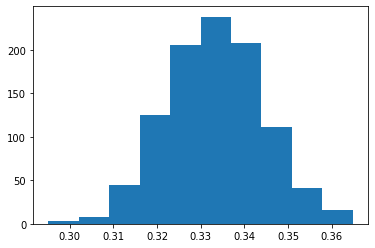
nsim = 1000
res = np.zeros(nsim)
for i in range(nsim):
exp_rvs = exponential(1/3, n)
res[i] = np.mean(exp_rvs)
Teorema del límite central
plt.hist(res)
plt.show()
Estimación del intervalo
mean_exp = 1/3
exp_rvs = exponential(mean_exp, n)
upper_limit = math.inf
lower_limit = 0
def f_scipy_integrand(x):
return x*1/mean_exp*math.exp(-1/mean_exp*x)
obj,err = quad(f_scipy_integrand, lower_limit, upper_limit)
h = lambda x: x
h_eval = h(exp_rvs)
h_bar = np.mean(h_eval)
print("error relativo: {:0.4e}".format(compute_error(obj,h_bar )))
error relativo: 9.8560e-03
est_error = np.sqrt((np.mean(h_eval**2) - h_bar**2)/n)
left_interval_point_central_limit = h_bar-norm.ppf(0.975)*est_error
right_interval_point_central_limit = h_bar + norm.ppf(0.975)*est_error
(left_interval_point_central_limit,right_interval_point_central_limit)
(0.3156262364396932, 0.35761107917502427)
La estimación de la integral se encuentra en el intervalo anterior:
h_bar >= left_interval_point_central_limit and h_bar<= right_interval_point_central_limit
True
Observación
Para tener una mayor estabilidad en el cálculo de la integral se realiza más de una aproximación a la integral y se reporta el promedio de resultados.
Ejercicios
Resuelve los ejercicios y preguntas de la nota.
Referencias
R. L. Burden, J. D. Faires, Numerical Analysis, Brooks/Cole Cengage Learning, 2005.
M. T. Heath, Scientific Computing. An Introductory Survey, McGraw-Hill, 2002.